模型评估与模型选择
模型选择的目的是使学到的模型对已知数据和未知数据都有较好的预测能力,同时又要避免过拟合。所考察的指标主要是模型的训练误差及测试误差,模型的复杂度越高,训练误差越小,但测试误差先减小后增大。
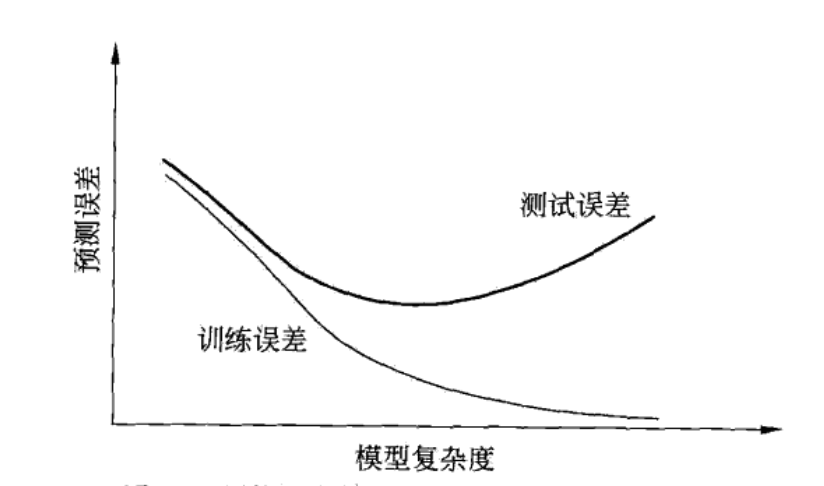
过拟合是指模型的复杂度比真模型更高,模型选择就是选择测试误差最小的适当复杂度的模型,即复杂度要求最接近真模型。但往往并不知道真模型的复杂度,这时可以采用奥卡姆剃刀原理,即在所有可能的模型中,选择能够很好地解释已知数据并且十分简单的模型。
避免过拟合的一种方式是正则化,即在风险函数中加入关于模型复杂度的惩罚项,又称为结构风险最小化策略的实现。模型越复杂,惩罚项越大。正则化的作用就是选择经验风险和模型复杂度同时较小的模型。
交叉验证是为了提高模型预测稳定性的一种策略,分为简单交叉验证、S折交叉验证、留一交叉验证。
- 简单交叉验证:70%训练集,30%测试集,得到训练模型后选出测试误差最小的模型。
- S折交叉验证:随机将已给数据切分为S个互不相交、大小相同的子集,依次选出一个作为测试集,S-1个作为训练集,最后选择平均测试误差最小的模型。
- 留一交叉验证:S折交叉验证的特殊情况,S=N,适用于数据缺乏的情况下使用,N为给定数据集的容量。
评价分类器性能的指标:
- 准确率指测试集中正确被分类的样本比例。
- 精确率指被分为正类的样本中确实是正类的比例。
- 召回率指所有正类样本被正确预测出来的比例。
- F1值是精确率和召回率的调和平均值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号