

Foreground-Action Consistency Network for Weakly Supervised Temporal Action Localization概述
1.针对的问题
由于只有视频注释,大多数现有方法寻求通过由分类进行定位的框架来进行时序动作定位,该框架通常采用选择器来选择动作的高概率片段或前景。然而,现有的前景选择策略存在只考虑前景与动作之间的单向关系这一主要局限,不能保证前景动作的一致性。换言之,它们只利用了前景必须是动作这一先验知识。一个可能的结果是,获得的前景分数只关注判别动作片段。(前景即选择器选择出来的动作高概率片段)
2.主要贡献
(a) 为了提高前景预测的鲁棒性,引入了一种class-wise前景分类流程。该流程对现有方法大多忽略的前景动作一致性进行建模。
(b) 提出了一种混合注意力机制来提高注意力学习,并帮助捕捉准确的动作边界。
(c) 与现有方法相比,本文提出的基于类的前景分类流程可以起到补充作用,从而持续提高动作定位性能。
3.方法
提出了一个基于I3D主干网的FAC-Net框架,在该框架上增加了三个分支,分别为class-wise前景分类分支,class-agnostic注意力分支和多示例学习分支。首先,class-wise前景分类分支建模动作和前景之间的关系,以最大限度地实现前背景分离。此外,采用class-agnostic注意力分支和多示例学习分支对前景动作一致性进行建模,帮助学习有意义的前景分类器。在每个分支中,引入了一种混合注意力机制,该机制为每个片段计算多个注意力分数,以关注判别和非判别片段,从而捕获完整的动作边界。
class-wise前景分类分支(CW分支):之前的方法是计算cas,激活值高的片段(即文中的前景)视为动作,该分支利用了动作应该是前景这一先验知识,提高动作片段被识别为前景的概率,具体来说:初始化一个动作分类器Wa∈R(C+1)×D和一个前景分类器Wf∈RD,计算嵌入Xe和Wa之间的余弦相似性以获取类激活分数Sa,Sa通过带温度系数的softmax获得注意力分数Aa,通过Aa对嵌入求加权和得到增强的特征Fa,由于Aa是通过激活分数得到,且前景的激活分数高,所以前景的权重更大,则加权后的特征中动作特征(这里的动作特征判断应该是将前景视为动作特征,类似伪标签)的权重变大,在通过Fa和Wf计算激活分数和置信度,最后通过交叉熵损失优化。
class-agnostic注意力分支(CA分支):CW分支只考虑从动作到前景单边关系,且对于背景类,前景分类器的特征Wf和背景特征Wa(C+1)之间存在歧义,导致实验中所示的性能较差,为了弥补从前景到动作关系的缺失,本文增加了一个CA分支,它还可以学习一个语义上有意义的前景分类器Wf,对CW分支起到补充作用。计算过程与CW分支基本一致,不过将Wa与Wf的位置互换。
多示例学习分支:也是对CW分支的补充,此外,MIL更关心一个类是否出现在整个视频中,而class-agnostic注意力更多地关注局部(因为每个帧的聚合是线性的),这两种流程提供了两种不同的视角来对视频进行分类,并且在某种程度上是互补的,计算过程就是使用CW分支的注意力分数Aa对CW分支得到的类激活分数Sa计算加权和。
混合注意力:即使作者努力构建前景动作一致性,注意力分数仍然不能很好地覆盖ground-truth,因为注意力得分倾向于关注判别前景片段和视觉上相似的背景片段。所以作者提出混合注意力策略,期望注意力能同时关注判别和非判别片段。作者通过在生成注意力分数的softmax中加入温度系数来达到这一目的,大温度系数会使注意力得分倾向于关注判别前景片段和视觉上相似的背景片段,反之则会包括一些判别度更低的片段。CW分支的混合注意力如下图:
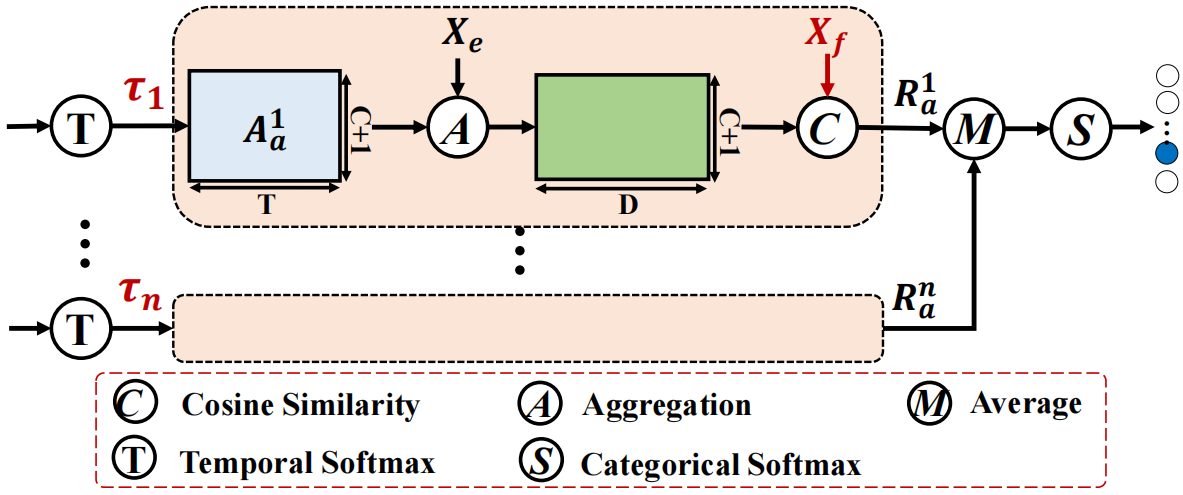
使用N个不同的τ来计算N个class-wise注意力分数{Aia}Ni=1,得到视频级前景激活分数{Ria}Ni=1求平均值以获得最终的前景激活分数,其他两个分支以同样的方式使用这种策略
模型总体结构如下:
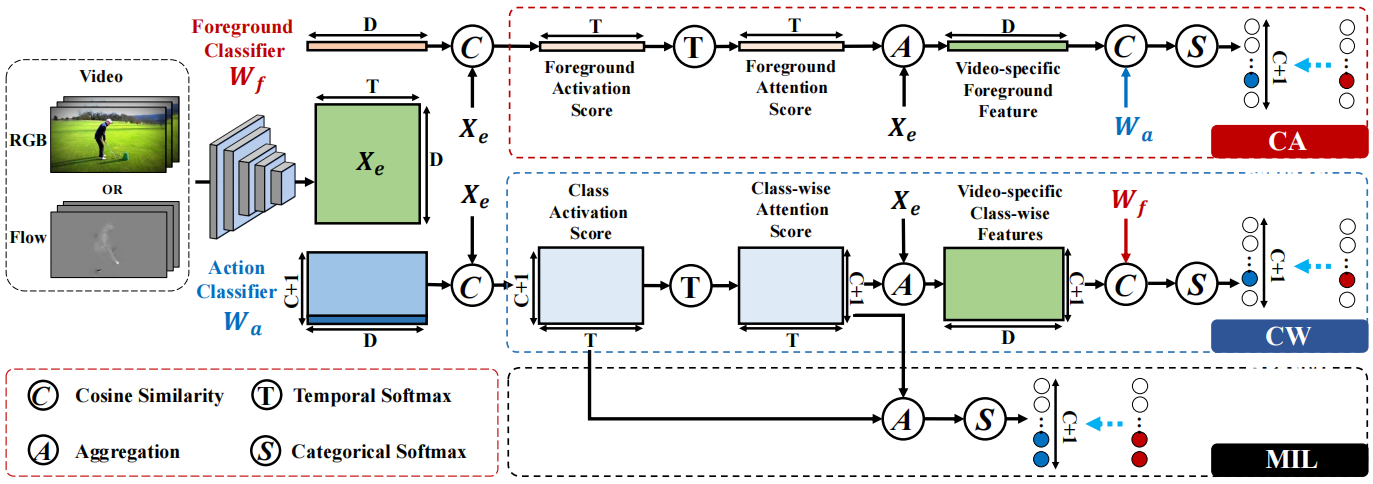
通过I3D提取RGB特征和光流特征,在特征编码之后,使用两层卷积来学习面向任务的特征Xe∈RT×D,将Xe分别输入三个分支。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号