

Weakly Supervised Action Localization by Sparse Temporal Pooling Network总结
0.前言
1.针对的问题
这篇论文前的许多视频理解技术都依赖于修剪过的视频作为输入,然而,现实世界中的大多数视频都是未修剪的,包含大量与目标动作无关的帧,由于提取显著信息的挑战,这些技术容易失败。
2.主要贡献
-
引入了一种新的深度神经网络架构,用于未经修剪的视频中进行弱监督动作定位,其中动作是从网络识别出的片段的稀疏子集中检测得到的。
-
提出了一种计算和结合时间分类激活映射和class-agnostic注意力的方法,用于目标动作的时间定位。
-
所提出的弱监督动作定位技术在THUMOS14 [17]上实现了最先进的结果,并在ActivityNet1.3 [14]动作定位任务中表现出色。
3.方法
使用注意力模块来识别一个视频中与目标动作相关的关键片段的稀疏子集,并通过自适应时间池化融合关键片段。
算法概述:
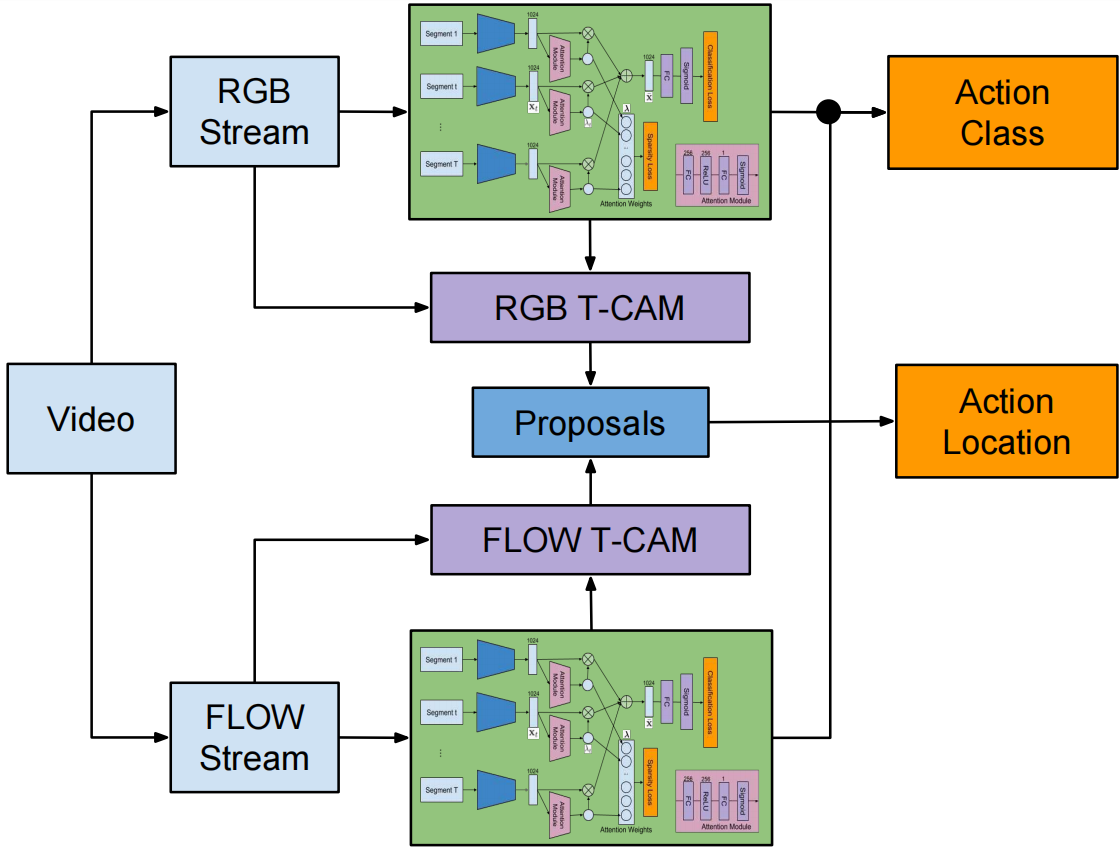
算法采用双流输入:视频帧的RGB信息和帧间的光流信息,并行执行动作分类和定位。 为了进行定位,从双流中计算时间分类激活映射(T-CAMs)并用于生成时序定位目标动作的一维时间动作提议。
模型总体流程如下:
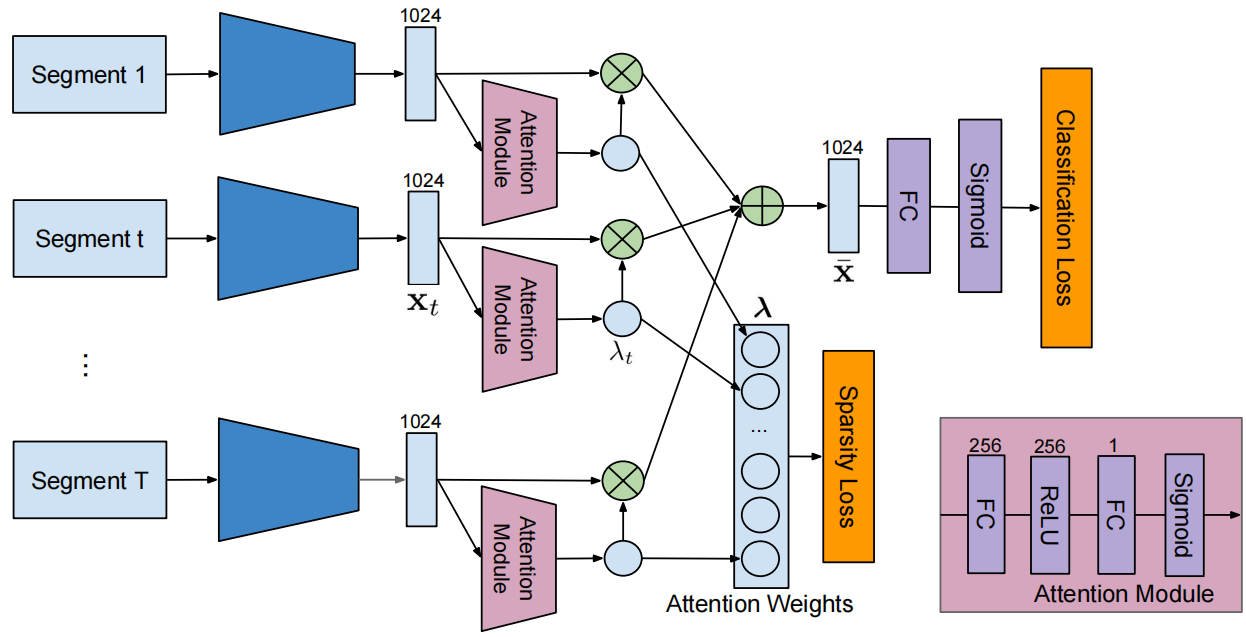
首先对一组片段进行采样,并使用预训练好的卷积神经网络从每个片段中提取特征表示。然后,每个特征向量被输入到一个注意力模块,该模块由两个全连接(FC)层和一个位于两个FC层之间的ReLU层组成。第二个FC层的输出输入到一个sigmoid函数,它强制生成的注意力权值在0到1之间。然后,这些类不可知的注意力权重被用来调整时间平均池化——特征向量加权和,以创建一个视频级别的表示。 该表示输入分类模块,该模块包含一个FC层,然后是sigmoid层,该分类模块可以利用视频级标签以规则的交叉熵损失进行训练。对注意力权重施加L1损失,作为稀疏损失,以加强稀疏注意力,使注意力集中在与动作相关的片段上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号