

Weakly-supervised Temporal Action Localization by Uncertainty Modeling概述
0. 前言
1.针对的问题
背景具有动态性和不一致性,动态性即动态的背景,如足球运动员进行庆祝的背景帧,不一致性指不同的背景帧在外观和语义上可能并不一致,这两个特点导致了目前的大部分方法的缺陷:
(1)有的方法通过合并静态帧来合成伪背景视频,但他们忽略了动态背景帧,即背景帧的动态性。
(2)另一些方法试图将背景帧分类为单独的类别。然而,强制所有背景帧属于一个特定类是不可取的,因为它们不共享任何公共语义,即背景帧的不一致性。
2.主要贡献
1)提出将背景帧描述为分布外样本,克服了由于背景不一致而难以建模的困难。
2)设计了一个新的弱监督动作定位框架,通过多示例学习,仅使用视频级的标签对不确定性进行建模和学习。
3)使用一个损失进一步鼓励在动作和背景之间进行分离,该损失使背景帧的动作概率分布熵最大化。
3.方法
作者认为,与背景帧的特征相比,动作帧通常具有更大的特征量,这是因为动作帧需要为ground-truth动作类生成较高的logits,不过虽然特征量与背景和动作帧之间的区分有相关性,但由于动作和背景的分布非常接近,直接使用特征量进行区分是不够的,所以作者对特征量进行了一些处理,即进行不确定性建模,通过公式推导,片段属于特定类别的概率可以分解为分布内动作概率和不确定性。具体来说:
选择top-k和bottom-k特征量,并分别考虑它们作为伪动作和背景帧,设计了一个不确定性建模损失来分离它们的大小,该损失训练模型为伪动作片段生成较大的特征量,但为伪背景片段生成较小的特征量。不过光有这个损失还不够,因为尽管不确定性建模损失鼓励背景片段为所有动作生成较低的Logits,但由于softmax函数的相对性,某些动作类别的softmax分数可能较高。为了防止背景片段对任何动作类具有较高的softmax分数,引入背景熵损失,以迫使伪背景帧在动作类上具有一致的概率分布。这可以防止他们倾向于某个动作类,并通过最大化它们的动作类分布熵来帮助实现这一点。
模型流程如下:
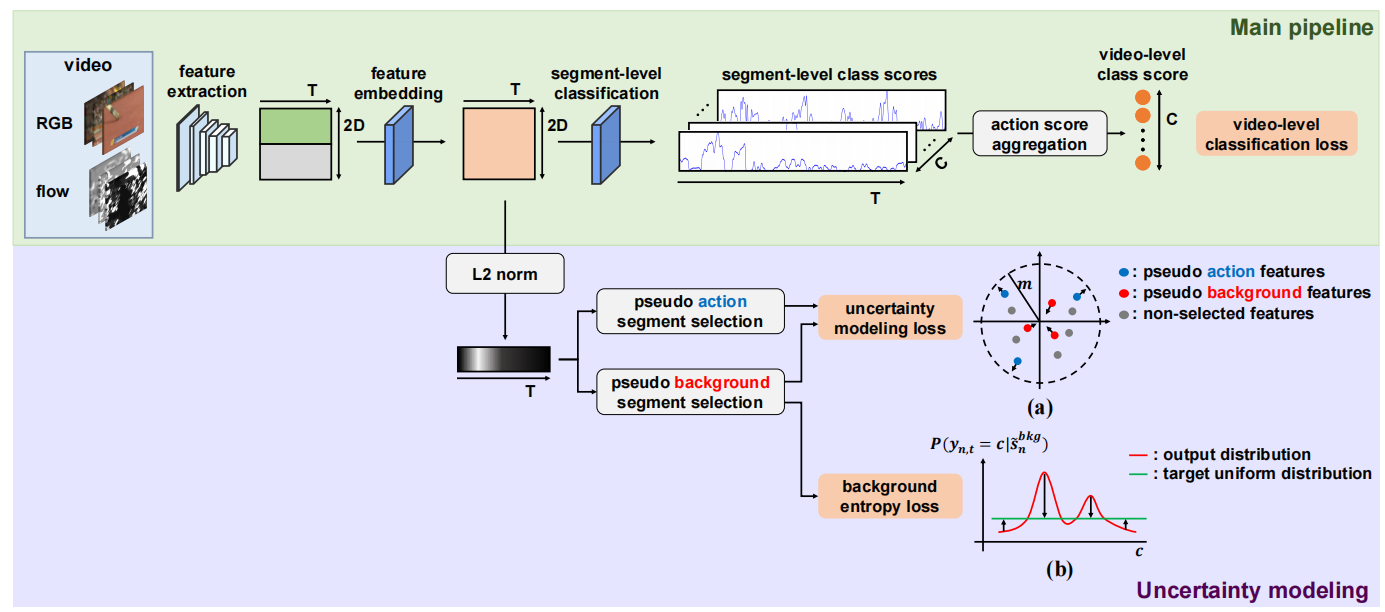
通过I3D抽取RGB和光流特征,将其堆叠构建长度为T的特征图,为了将提取的特征嵌入到特定任务的空间中,经过一个一维卷积和ReLU函数进行特征嵌入,嵌入特征一方面进入主流程,该流程遵循传统MIL流程,得到视频级分类分数,一方面进入不确定性建模流程:
(1)主流程:嵌入特征经过一个动作分类器得到段级类分数,分类器有一个1D卷积和dropout组成,通过动作得分聚合,即取每个动作类的前Kact个分数进行平均,然后使用softmax函数,得到视频级类分数,通过视频级分类损失(二进制交叉熵损失)进行优化。
(2)不确定性建模流程:计算嵌入特征的L2范数得到每个帧的特征量,进行选择得到伪动作帧和伪背景帧,通过不确定性建模损失增大伪动作特征量,减小伪背景特征量,通过背景熵损失使背景片段的动作概率熵最大化
之前的工作将背景类作为第c+1类,但是由于背景帧的不一致性导致这种将所有背景帧归于一类的做法并不合适,论文中的做法类似于划分出两个大类:分布外和分部内,即动作类和背景类,而分类的依据是通过处理后的特征量进行分类。
低概率事件带来高的信息量,当概率小的时候,熵的值就会越大,所以说当不确定性越大的时候,熵越大。
公式3推导:设yn,t=c为A,d=1为B,![]() 为C,则原式P(AB|C)可化为P(AB|C)=P(ABC)/P(C)=[P(C)P(B|C)P(A|BC)]/P(C)=P(B|C)P(A|BC)
为C,则原式P(AB|C)可化为P(AB|C)=P(ABC)/P(C)=[P(C)P(B|C)P(A|BC)]/P(C)=P(B|C)P(A|BC)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号