Deep Motion Prior for Weakly-Supervised Temporal Action Localization概述
0. 前言
1.针对的问题
作者认为现有的方法忽略了两个重要的缺点:1)运动信息的使用不足,2)普遍存在的交叉熵训练损失的不兼容性:XE损失旨在衡量分类模型的性能,与定位任务本质上是不兼容的。具体地说,XE损失鼓励了区分度高的视频clip,这些视频clip往往是零碎的,没有涵盖整个动作。
2.主要贡献
(1)提出一种通过运动图来获得依赖于上下文的深度运动先验以辅助获得精确的动作定位的方法
(2)提出了一种高效的运动引导损失,以通知整个流程更多的运动线索,这些线索可以无缝插入任何现有的WSTAL模型。
(3)在三个具有挑战性的数据集上进行的大量实验证明了提出的DMP网络的有效性。
3.方法
1.针对第一个问题,作者提出建立一个上下文相关的运动先验,称为motionness。引入运动图来基于局部运动载体(例如光流)对运动进行建模。具体而言。对于运动建模,作者引入了一个运动图来放大每个时间片段的感受野,因为光流是两个连续帧之间计算的局部运动表示。具体来说,从位置关系和语义关系两个角度研究了时间关系。作者认为各帧之间存在两种关系:(1)位置关系:即两帧在时序位置上的远近。如果某帧被错误分类,而其周围的帧都被正确预测。这些相邻的片段将提供上下文信息,这有利于该帧的正确分类。(2)语义关系,即各帧运动内容的相似度。如果两帧距离较远,但它们具有相似的运动模式(类似的运动过程)。则这两帧可以互相提供指示性提示,并提供更全面的信息。基于这两种关系,作者构造了一个运动图,它既鼓励相邻的位置上下文,也鼓励遥远的语义关联。该图是一个稀疏图,包含位置边和语义边,位置边用来利用位置相关性,语义边用来捕获语义相关但不相连的片段。同时,光流也能起到辅助作用,
2.针对第二个问题,作者提出了一种运动引导损失来调节基于运动分数的网络训练。该损失可以以即插即用的方式取代现有WSTAL方法中的传统交叉熵损失。传统方法中的top-k均值策略,对于每个类别,具有最大TCAS值的k个项的均值被计算为视频级别分类分数。在本文中,作者进一步评估了这些选定项的运动特性。具体来说,取motionness序列中相应项的值,并将这些值纳入损失计算。这样,TCAS和motionness评分都较高的项会突出显示,而motionness评分较低的项则会降低权重。
作者提出模型称为DMP网络,它由两个分支组成:基本分支和引导分支。基本分支采用标准的多示例学习流程,模型流程如下:
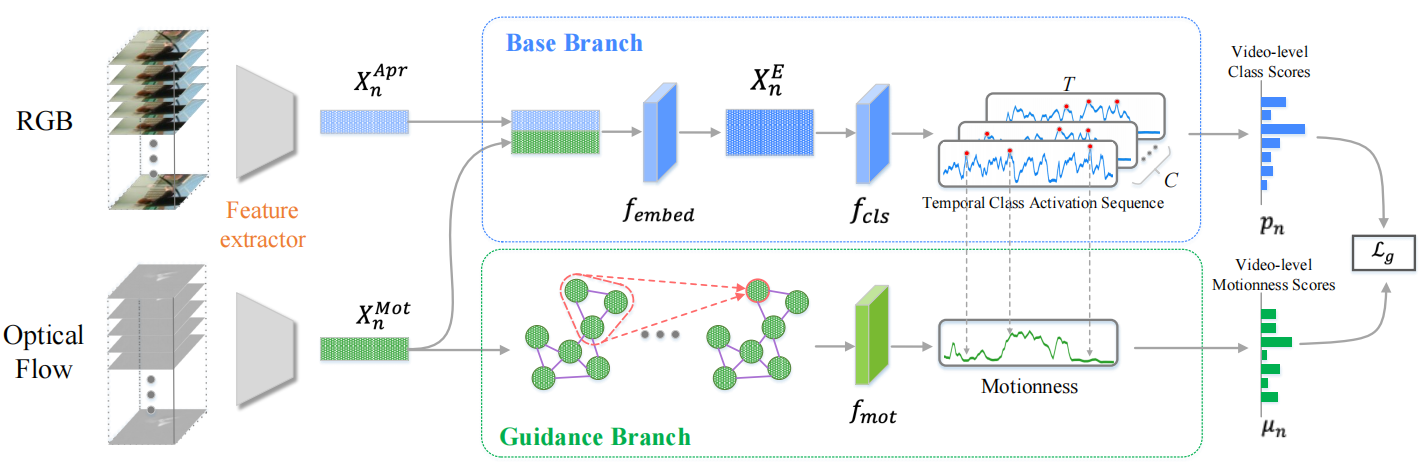
使用预先训练的特征提取器(如I3D[2])分别从采样的RGB片段和光流片段中提取外观特征XnApr和运动特征XnMot,这些特征输入两个分支:产生类特定概率(TCAS)的(a)基本分支和输出未知类的深度运动先验的(b)引导分支。
在基本分支中,对于TCAS的每个通道(类别),在XnApr和XnMot的连接上应用嵌入函数fembed来获得特征XnE,fembed通过时间卷积和ReLU激活函数实现。应用一个分类器fcls来获得片段级的类分数,即TCAS,对于TCAS的每个通道(类别),选择具有最大值(标记为红色节点)的前k项来聚合视频级的分类结果,将分类分数加入运动引导损失Lg。
在引导分支中,对于输入的片段光流特征,如果片段mi和mj的时间距离低于一个预设阈值,则在它们之间建立一条边,使用片段节点之间的余弦相似性来查找语义相关的节点,并在节点间建立一条边,从而得到运动图,在运动图上应用k层GCN,将第K层特征与输入特征连接起来作为最终特征XK,最后在XK上应用二值分类器fmot来获得运动状态。同样选择运动性序列中相应的项,提供给运动引导损失Lg。为了清晰起见,图中只显示了第一个通道的运动性选择,其余的通道都是相似的。
1.为什么要在最后一层保留输入特征?
答:原文中说是参照G-TAD: Sub-Graph Localization for Temporal Action Detection和Graph Convolutional Networks for Temporal Action Localization这两篇论文,前者将语义图和时间图分别进行图卷积,最后将两个卷积结果和输入特征的和作为输出,但是好像并没有说明为什么要保留输入特征,后者操作与本文一样,作者说是在实验中发现这种做法更有效,可能是个trick
2.为什么要构建稀疏图?(稠密图指全连通图)
答:作者在实验中发现,完全连通图的性能落后于稀疏图,作者通过实验观察到,全连通图邻接矩阵的高权重主要集中在对角线区域,即每个节点与其周围的节点更相关,这可能是因为视频数据的slowness prior,短期特征在局部窗口中变化缓慢。因此,相邻权重集中在位置相邻的区域,而忽略了距离较远但语义相关的片段。相比之下,我们的稀疏图通过鼓励片段之间的语义关联,即使它们距离很远,来缓解这个问题。
3.图中第一层图与最后一层图之间的连线代表什么?
答:应该指最后一层节点获取了与之相连的其他节点的补充信息,ACGNet中也有相似度的画法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号