
CLIP:Learning Transferable Visual Models From Natural Language Supervision
0. 前言
1. 要解决的问题
之前的计算机视觉模型的数据集都是针对某一类特定任务,迁移效果较差,同时,一些训练时表现好的模型可能在测试中表现不佳。
2.主要贡献
如何利用自然语言作为监督信号
- 不预先定义标签类别,直接利用从互联网爬取的400 million 个image-text pair进行图文匹配任务的训练,并将其成功迁移应用于30个现存的计算机视觉——OCR、动作识别、细粒度分类。举例来说,无需利用ImageNet的数据进行训练,就可以达到ResNet-50在该数据集上有监督训练的效果。
- 利用language作为监督信号来学习视觉特征。
3. 方法
论文方法的核心是在自然语言的监督中学习。
从自然语言中学习有几个潜在的好处:
- 和用于图像分类的标准标记相比,扩展自然语言监督要更容易,因为不要求标注内容需要采用机器学习的兼容模式;
- 自然语言可以在互联网上大量的文本中进行学习;
- 自然语言学习不仅是学习一种表现,同时也将其和语言表示联系起来,灵活的实现“zero-shot”转移。
从自然语言中学习有几个潜在的好处:和用于图像分类的标准标记相比,扩展自然语言监督要更容易,因为不要求标注内容需要采用机器学习的兼容模式;自然语言可以在互联网上大量的文本中进行学习;自然语言学习不仅是学习一种表现,同时也将其和语言表示联系起来,灵活的实现“zero-shot”迁移。
CLIP主要完成的任务是:给定一幅图像,在32768个随机抽取的文本片段中,找到能匹配的那个文本。为了完成这个任务,CLIP这个模型需要学习识别图像中各种视觉概念,并将视觉概念将图片关联,也因此,CLIP可以用于几乎任意视觉人类任务。例如,一个数据集的任务为区分猫和狗,则CLIP模型预测图像更匹配文字描述“一张狗的照片”还是“一张猫的照片”。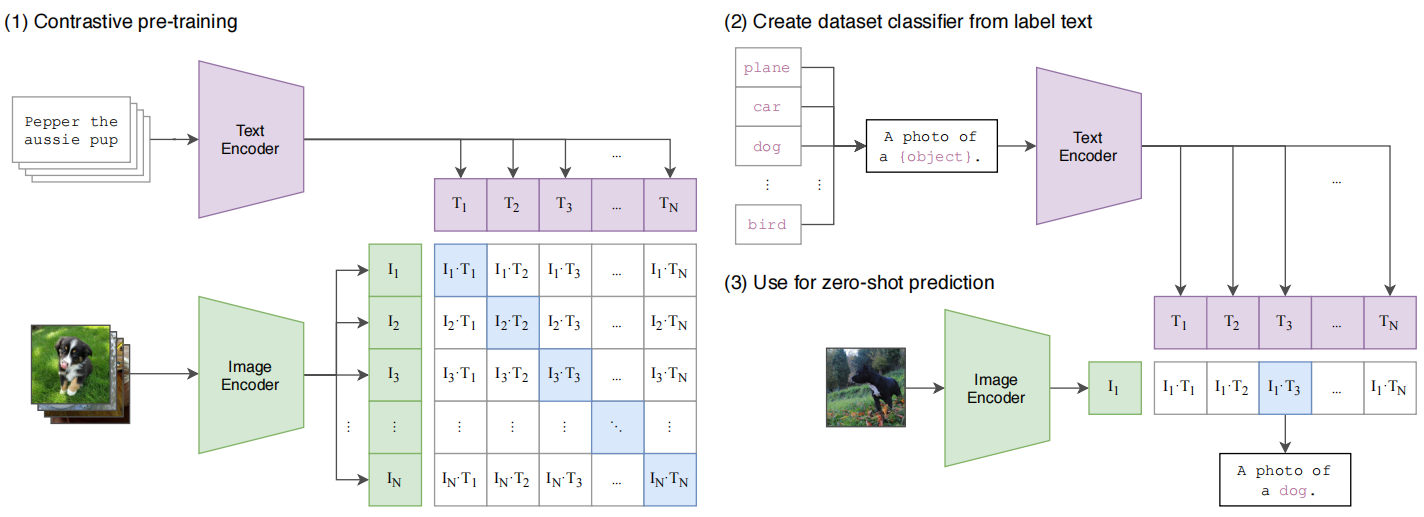
预训练采用对比学习,匹配的图片-文本对为正样本,不匹配的为负样本。收集到的文本-图像对,分别经过Text-Encoder和Image-Encoder,然后通过点积计算一个batch中文本和图像两两之间的相似度,得到一个batch size x batch size的相似度矩阵,对角线上的相似度值就是正样本的相似度值,因此在训练过程中优化目标就是让正样本的相似度值尽可能大。
在进行图片分类任务的推理时,由于没有分类头,作者利用自然语言进行分类,也就是prompt template,模型首先需要将类别标签转换成和预训练时候一样的句子,因此这里用到了prompt操作,获得类别相应的句子。最后计算输入图片和每个类别对应句子的相似度,相似度最高的句子对应的类别的就是预测的类别。
4. 效果如何
在imagenet上即使是zero-shot也可以达到ResNet-50的效果,迁移能力令人震惊,但是在一些难以用文本描述的数据集上,如纹理数据集,表现效果较差,且在各数据集上的效果与SOTA比还是有差距,不过其他的都是监督学习,所以总体来看效果还是十分不错。
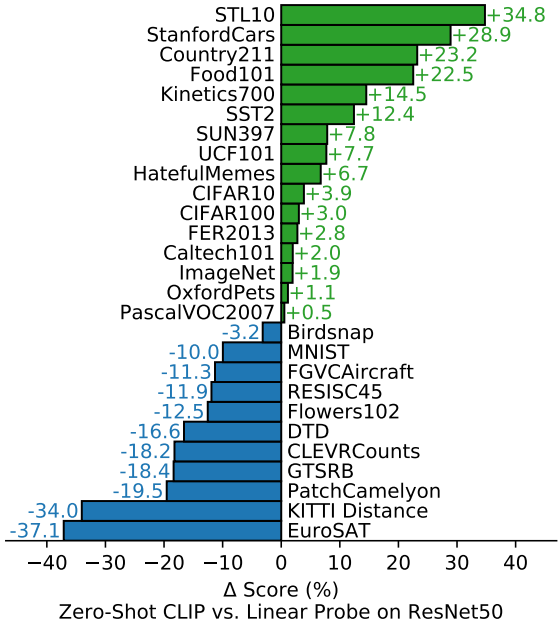
CLIP在各数据集上的zero-shot效果与ResNet50有监督效果对比(采用Linear Probe)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号