《Taurus Database: How to be Fast, Available, and Frugal in the Cloud》阅读笔记
注:本笔记不是对论文的直接翻译,内容上有些论文比较完整地就省略了,会有一些自己思考的补充信息。
1. Introduction
论文认为,一个好的DBaas架构服务必须提供 durability,scalability, performance,availability, cost-effectiveness 五个方面的保证。
- 不同节点上的三副本通常认为已经足以保证durability;Taurus全文主要讨论的就是如何保证数据库层的durability (log as database)
- 计算存储分离及其各自的分布式实现可以提供scalability
- performance是个相对概念,在Evaluation chapter中的对比会提到Taurus replication strategy(相比quorum-based)和仅有两层网络划分(相比Socrates的四层)导致了Taurus在和Aurora和Socrates相比较时带来的性能收益。
- availability是本文的一个核心,主要是Taurus replication机制和PageStore模块。
- cost-effectiveness没有细讲,也是个相对概念,文中主要是说明了在没有额外增加硬件成本开销的情况下达到了更好的可靠性和性能。
Taurus提出将durability和availability分离,实际也就是将log和data分离。durability由WAL log保证,文中相关的为LogStore;availability依靠PageStore的PLog三副本保证。
2. 基本架构形态
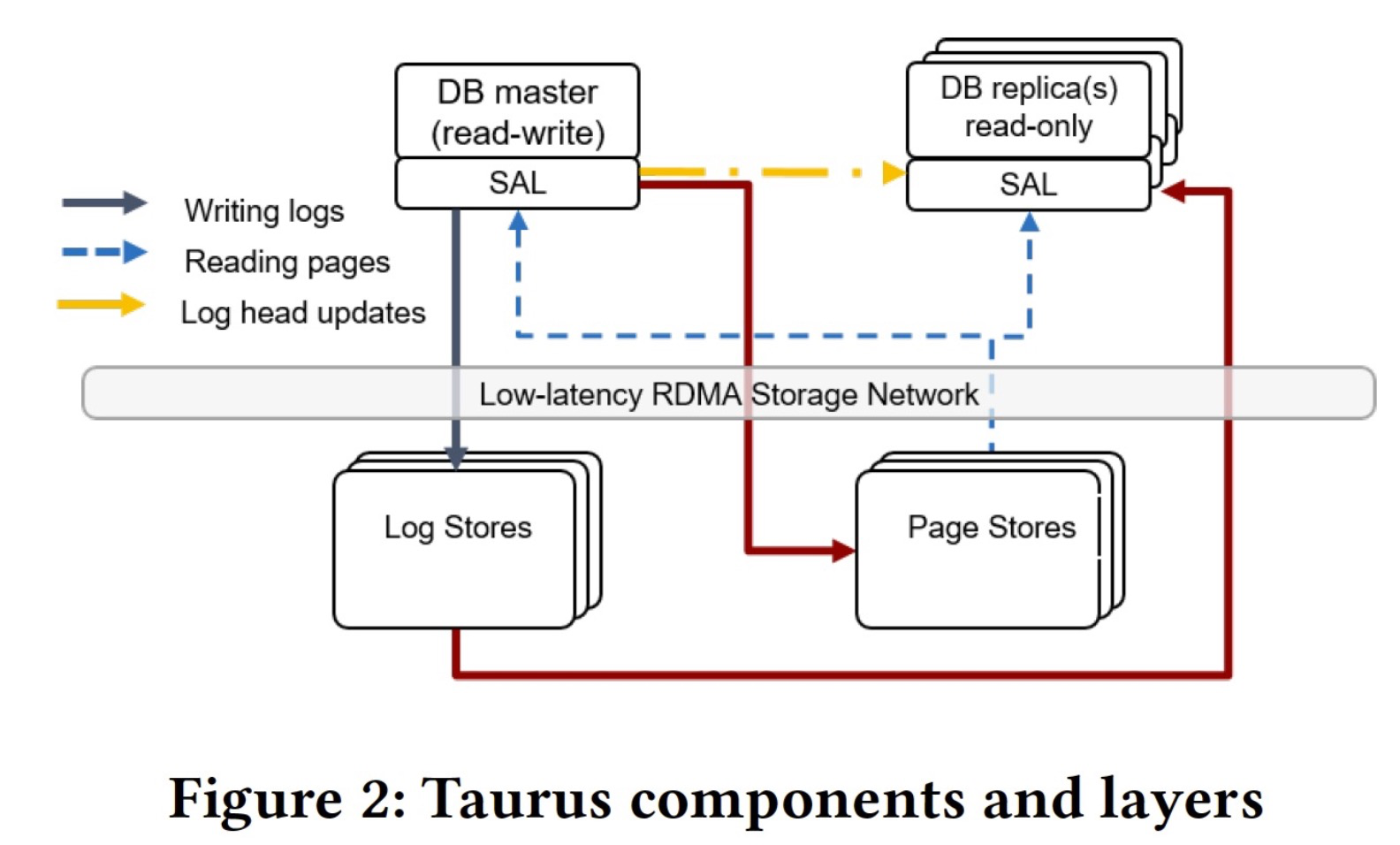
Taurus是个基于共享存储的计算存储分离和一写多读的云数据库,DB前端目前是一个改版的MySQL 8.0,未来会支持PGSQL等。DB引擎通过Storage Abstraction Layer(SAL) 和共享存储交互,SAL可以对标PolarDB的libpfs.a,也是以lib形式存在,但不同的是SAL并未局限为一个文件系统,拥有更多对整体DB和存储融合的适配空间。Master(RW节点)在写入时会先写log到LogStore,再写数据到PageStore。Read replica(RO节点)会从Master同步写位点,并不断从LogStore读相差的日志,apply到自己本地的bufferpool中。
每个PageStore会被划分成若干个10GB大小的Slice,三副本的对象是Slice,即不同机器的三个Slice组成三副本(类似PolarFS的chunk)。PageStore自身的三副本保证写的可靠性(不依靠Log),三副本会通过gossip分布式协议去互相保证数据完整性和可靠性,换句话说,如果写入的三副本其中一个副本失败被拉起,他会依靠另外两个副本做恢复。
3. 模块细节
LogStore
一个集群中通常有几百个LogStore服务。LogStore的核心是PLog,PLog是一个大小有限(64MB limit)、跨LogStore、append only的多副本存储表示对象(Taurus就是三副本,即三个LogStore);另一种理解是PLog就是一个对上层的可靠性封装,日志写进PLog成功即可视为成功,而实际上PLog写成功响应的前提是需要PLog内三副本LogStore都写成功。如果PLog写超时或失败,cluster manager会重新选择另外三个LogStore创建一个新的PLog。这个策略保证了只要时间允许和有至少三个健康的不同节点的LogStore存活,日志写一定会最终能成功;并且Taurus保证日志写重试不会重试回旧的LogStore以提高成功概率。
日志读只要PLog有一个replica存活就能读成功。日志读通常发生在两种场景:1. Read replica 读最新日志追赶Master;2. 数据库恢复。第一种情况是高频情况,因此LogStore做了一层FIFO cache缓存最新的日志数据。
PLog会分为metadata PLog和data PLog。对于同一组PLog,由于前面提及的超时等原因存在,可能会先后创建多个PLog对象,但是他们负责的是同一批日志。这样一个有序的data PLog列表的增删操作日志和一些映射信息会被记录到metadata中,当metadata满的时候,系统会创建一个新的metadata PLog,将前面的操作日志purge(也许有合并)后,仅将latest的必要的metadata写到新的metadata PLog,旧的会被直接删掉。
PageStore
PageStore主要是对上服务于DB节点的read page请求,对下管理Slices。它不是一个通用的存储,而是具有持久化页的视角和读写管理功能的模块。Master发给PageEngine的写请求实际也是log record,PageEngine会将其apply到存储的pages上。
PageStore通过四个主要的API向SAL提供能力:
- WriteLogs 接收若干log records的写请求
- ReadPage 按照特定页版本去读某个页。其中 PageVersion=(PageID, LSN)
- SetRecycleLSN 在这个LSN之前的版本已固化且不会再被上层数据库事务访问。通常这个LSN适用于purge,比如purge多版本页的旧版本。该接口会被DB引擎周期性调用以保证purge的效率。
- GetPersistentLSN 相当于PageStore的readpoint,小于等于这个LSN的数据是对上可见的。
PageStore internal
当前的PageStore在写密集场景下可以服务百万级的log_record per sec,这里的apply logs涉及到一个概念 log固化:PageStore apply logs & produce and persist new pages 。由此,PageStore有三个实现上的特性:
- Independent log consolidation。即三副本的PageStore的log固化流程不依赖于某种raft或paxos的分布式协议,而是各自去执行对应流程。(但会借助gossip分布式协议去做部分replica写失败的校验和修补)
- log固化的磁盘写是一个append only的追加写过程,保证写盘性能。
- log固化过程中涉及到的page都会在PageStore的memory中,以保证在整个固化或涉及到page的更新都不会产生读IO。
PageStore内的LogDirectory模块复杂管理log records的location和当前PageStore上的Slices的页和版本的映射关系(用一个无锁hashtable)。为了避免LogDirectory膨胀导致PageStore性能跟不上,SAL侧做了throttle机制,LogDirectory在purge或log truncation阶段会被清理变小。

上图是PageStore的主要工作流,其中:
- step4 中可以发现PageStore自己也是有个bufferpool存在的,相当于个分散的二级缓存,采用LFU实现(论文通过测试认为LFU相比LRU更适合作为二级缓存的策略,hit rate可以提升25%)。
- step5 刷脏。实际上只有page刷下去了,相应的persistent LSN才会被更新。
- step6 LogDirectory元信息也会被周期持久化,减少recover时log回放重新生成LogDirectory的开销。
图上需注意的是,LogDirectory是Slice级别的(降低规模减少hash冲突),LogCache和BufferPool是PageStore进程全局的。
在收到一批log records时,决定先对哪个page做固化操作采用的是“log cacge-centric”,即先到达log cache的log record ordered group会被优先处理,处理完就会从log cache删掉。实际上log cache是会被塞满的,满了之后到达的log records就会在磁盘上维护个队列。这样做法可以尽可能避免log cache的命中率下降,尽可能保证处理的都是内存里的log records。 这一段疑点很多,论文没有展开讲,背后问题很可能是PageStore apply log成为瓶颈,后面write path提到的只写一个replica返回也是因为这个问题。论文一开始讲了个不靠谱的借鉴自区块链的最长链优先,根本不适用于log这种需要高效顺序apply的场景,链短的page很可能就会饿死影响整个系统相关LSN推进。随后写了一整段的log cache-centric 如果没有展现相关多线程实现的话,看上去就是个显而易见的FIFO,log cache无非就是个内存队列。
Storage Abstraction Layer
SAL可以理解为存储层的前端和存储数据分布式管理组件,它负责DB引擎与存储的LogStore/PageStore交互,同时也负责创建、管理、删除PageStore的Slices以及管理page在Slices上的映射关系(或者叫storage layout)。
Master写的时候,SAL会有一个database log buffer来尽可能batch io避免小IO、SAL写到active的LogStore replica成功之后,同一个buffer的log records会分发到per-slice buffers(即每个slice有自己的buffer),per-slice buffers会在满或某一时间后触发flush,发给对应PageStore。
SAL维护着cluster visible LSN (CVLSN),这个LSN代表着数据库全局一致点。当日志对应的数据持久化到Slices时,当前持久化的latest LSN可以视作CVLSN。这里包含了两个loose的隐性约定:
- Slice虽然有三副本,但是数据不需要三副本都写完再返回持久化成功,这里replica可以是异步写,Slice之间依靠gossip协议去保证可靠性。
- CVLSN是对于Master写而言,更像是一个write point。因此Read replica同步数据的位点其实也应当是CVLSN。
这里的语义强依赖先写LogStore成功再写PageStore Slices这个前提,因此SAL还需维护一个临时映射关系:当前log buffer和slices的多对多的映射关系,这个关系才能帮助SAL顺利正确地推进CVLSN。
Read replicas (RO节点)
RO节点通常关注的问题:
- 与Master的同步:Master不会同步binlog,而是在写完成后同步相关log records的元信息和写完后更新的LSN。RO从LogStore去自行读取log来apply到自己的bufferpool中并推进自己可读位点(TVLSN,Transaction visible LSN)。
- 读数据的原子性:Master同步log records给RO的时候一定是以一个完整的group同步,RO apply的时候保证不会有中间结果。比如,当某个线程正在分裂某个B+树的page,这时候的改动会涉及到多个page,同时,有别的线程也在遍历这一颗树其他线程,那么为了确保线程看到一致的结果,分裂操作需要变成一个原子操作。加上group之后,RO要么看到分裂前,要么看到分裂后的,至少保证都是某一时期的完整数据。
- 跨节点之间读一致性:论文并未显示对这点有支持,目前机制无法支持节点间一致性读,可能需要上层再加一个proxy带着LSN读来解决相关问题。
- 版本读:引擎中的bufferpool可以存储多版本页。
4. Replication
Write path
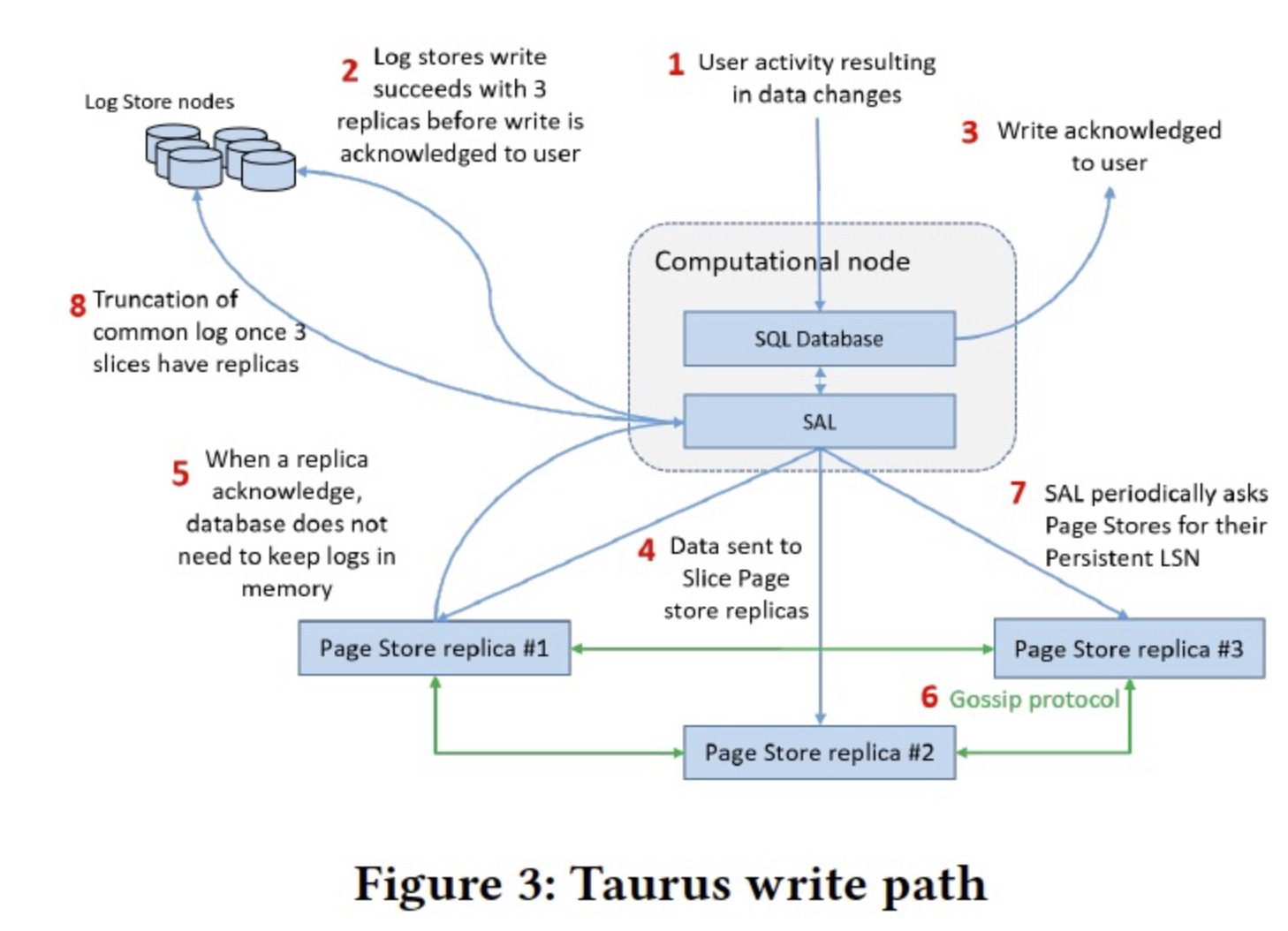
图中是个写路径的描述,其中:
- 2 需要log的三副本都写成功才ack(强一致)
- 3 日志写完就可以ack给用户了,因为Read replica也是依靠日志回放同步的;如果宕机,PageStore也是依靠LogStore做差异的日志恢复,所以不需要等PageStore写完才返回。
- 5 只要有一个Slice replica ack了,SAL就可以把相应部分的log buffer逻辑意义上释放掉,这就是上文说的SAL需要维护一个临时的多对多关系的原因。
- 6 Slices三副本会通过gossip协议detect and recover missing buffers。
- 7、8 和Log truncation有关,见下一节描述。
Log truncation
Log能被删除的前提条件:
- 数据都已写到所有的slice replicas
- 当前数据已对所有RO节点可见
前提1是由每个slice 的 persistent LSN判断的,slice persistent LSN由对应的PageStore维护,可以由GetPersistentLSN()方法显式返回或通过WriteLogs/ReadPage方法顺带隐式返回。当所有 slice persistent LSN 都大于等于log LSN时,则表示前提1被满足,该动作发生在SAL。(即上图write path中step 7)
SAL会总和所有三副本Slices,把其中还未完全达到同步完成的三副本中的最小的persistent LSN作为database persistent LSN(论文说法有点绕,按照实现方法描述了,实际换个角度可以理解为达到三副本同步完成最大的persistent LSN),该LSN会用来作为整个数据库latest的恢复起始点。
SAL同时会追踪每个PLog的LSN range,如果PLog max LSN < database persistent LSN,则该PLog可被删除。(上图step8)
Read path
bufferpool在这里有个修改,保证大于CVLSN的脏页不会被换出bufferpool(RO节点也有可能,比如日志写完了并被RO同步了,但PageStore持久化未完成),从而保证数据读的正确性。若需要从存储上读页数据,SAL会负责去对应PageStore上读取。
为了避免一些部分操作带来的中间数据(比如保证b+tree分裂的原子性),Master是以group为单位产生log,RO节点在同步log的时候也是以group为粒度apply的,从而避免割裂的单独一条日志带来的语义不完整性。
但此处存疑的一点是,论文没有介绍对于不同RO节点数据的数据一致性怎么保证:即RO1同步的比较慢,RO2同步的比较快,某一时刻他俩看到的可能不是同样的数据。group机制只能保证单位同步的原子性,不能解决多节点一致性问题。
5. Recovery
Taurus recovery分为short-term和long-term,15 min以内的宕机都认为是short-term。对于一个三副本,允许在short-term的时间内一副本挂掉仅有两副本提供服务,但long-term必须完整恢复。
LogStore recovery
short-term failure不用做recovery,当前LogStore的PLog节点会停止写入只能读取。新的可写入的PLog会在另外三个健康的LogStore上创建。如果达到了long-term,则该LogStore会被集群移除,寻找另一健康LogStore加入当前PLog做三副本服务于读取。
PageStore recovery
Taurus依靠gossip协议去恢复PageStore三副本之间出问题的副本。
SAL recovery
SAL作为lib嵌进数据库中,恢复时先恢复SAL,再恢复数据库前端。SAL会读取最后存储的database persistent LSN,使其作为恢复的起始点。日志会回放给PageStore,中间可能会出现宕机前已经固化的数据被重新发给对应PageStore,但PageStore内部会有LSN记录去忽略重复的数据。这一步相当于redo log recover。当SAL代表的底层存储recover完成时,数据库前端开始执行undo log去回滚那些未提交的事务。
6. Evaluation
最后Taurus和Aurora、Socrates分别做了比较,论文显示结论是:
- 在Sysbench 1GB读写、1TB写、 TPC-C(10G、100G)上均优于Aurora,认为主要原因是Taurus的replication IO策略比Aurora的quorum-based性能要好。
- 由于Socrates是SQLServer,架构完全不一样不好比,Taurus借助了Socrates的结果和本地盘MySQL 8.0去比较来达到和Socrates间接比较的效果。最后Taurus认为自己性能较好的一个主要原因是Taurus IO路径上只有两层的计算存储网络分离,而Socrates涉及四个模块的网络IO。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号