结对项目:用Python实现四则运算
| 这个作业属于哪个课程 | 计科1/2班 |
|---|---|
| 这个作业要求在哪里 | 结对项目 |
| 这个作业的目标 | 实现一个自动生成小学四则运算题目的命令行程序 |
团队成员
| 姓名 | 学号 |
|---|---|
| 梁昊东 | 3121005000 |
| 李铭伟 | 3121004145 |
github链接: https://github.com/e1ecb0t/e1ecb0t/tree/main/caculator
1. PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 40 |
| ·Estimate | 估计这个任务需要多少时间 | 60 | 40 |
| Development | 开发 | 750 | 840 |
| ·Analysis | 需求分析(包括学习新技术) | 240 | 270 |
| ·Design Spec | 生成设计文档 | 120 | 100 |
| ·Design Review | 设计复审 | 30 | 40 |
| ·Coding Standard | 代码规范(为目前的开发制定合适的规范) | 30 | 30 |
| ·Design | 具体设计 | 120 | 140 |
| ·Coding | 具体编码 | 180 | 200 |
| ·Code Review | 代码复审 | 30 | 60 |
| Test | 测试(自我测试,修改代码,提交修改) | 200 | 240 |
| ·Reporting | 报告 | 120 | 150 |
| ·Test Repor | 报告测试 | 30 | 30 |
| ·Size Measurement | 计算工作量 | 20 | 20 |
| ·Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 30 | 40 |
| 合计 | 1010 | 1120 |
2. 效能分析
cpu占用时间检测
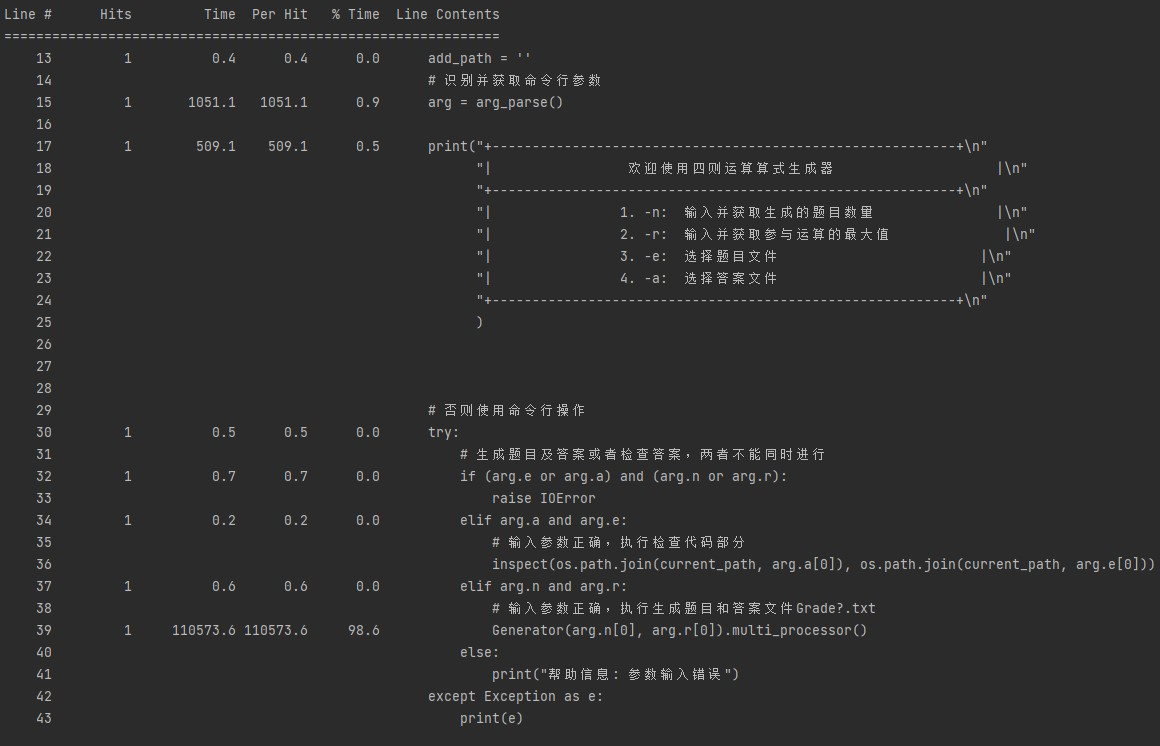
可以看到程序主要耗时的部分为生成题目及答案部分,占cpu耗时的98.6%
内存占用检测
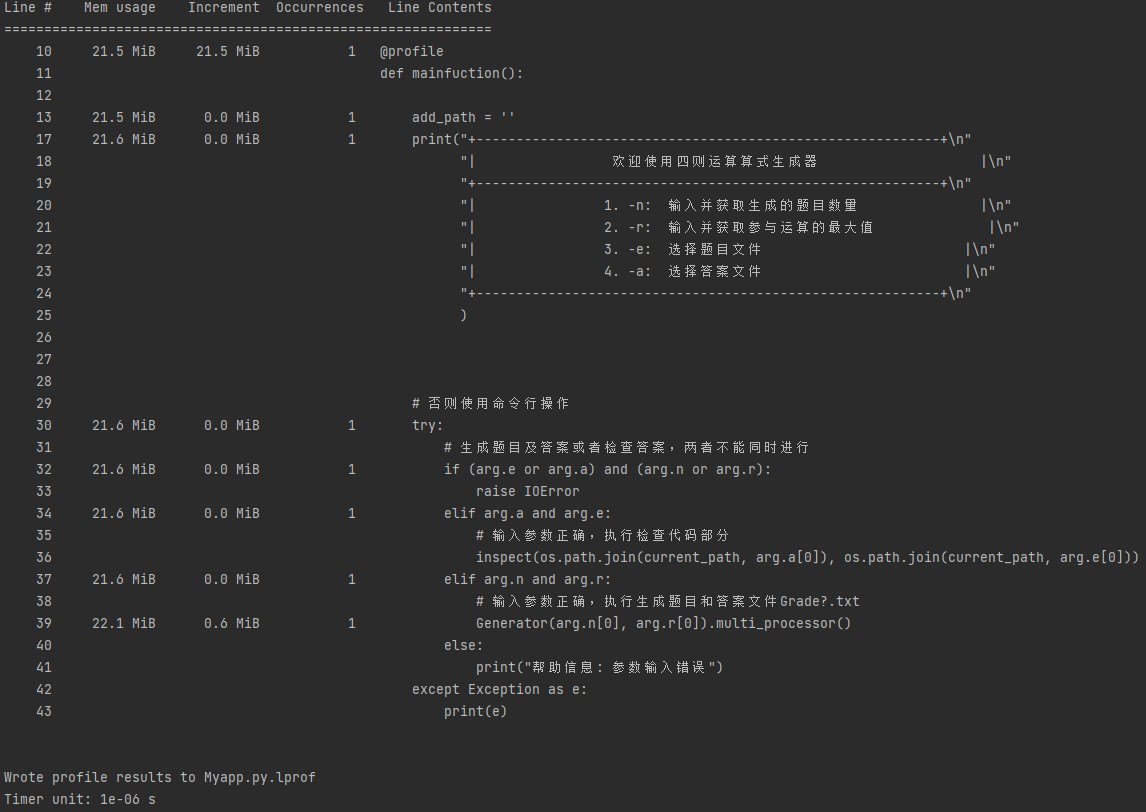
可以看到程序最大内存占用为0.6MiB
程序总耗时

3. 设计实现过程
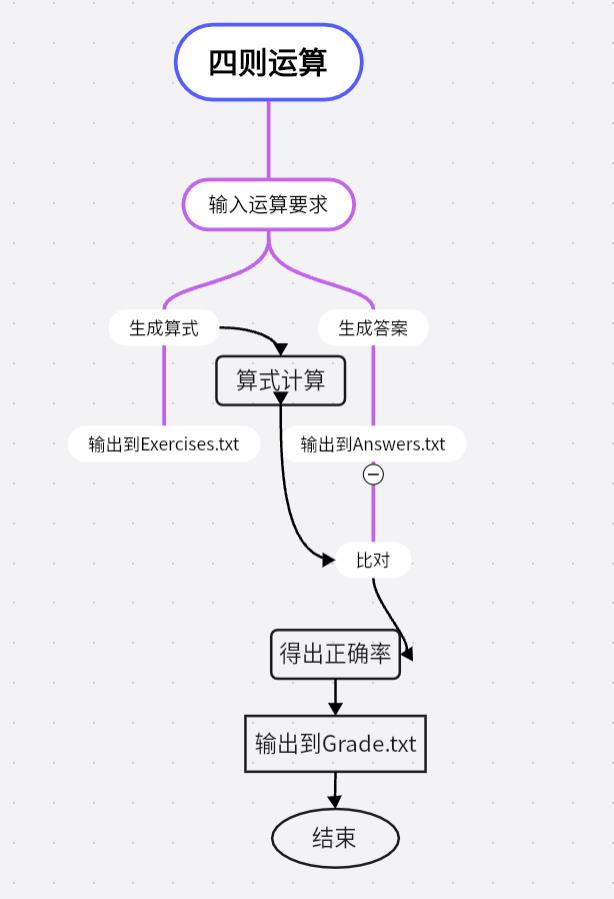
随机生成算术表达式
(1) 在Arithmetic类中,随机生成运算符个数、操作数个数,并设置值域范围。
(2) 随机生成操作数列表和运算符列表。
(3) 构建表达式的中缀表达式,中间可能随机插入括号。
(4) 删除无用括号,返回表达式列表。
计算表达式
(1) 在Calculate类中,将中缀表达式转化为后缀表达式。
(2) 使用栈的方式计算后缀表达式:遍历后缀表达式,数字入栈,操作符时取栈顶两个元素进行运算,结果入栈,直到遍历完表达式。
(3) 返回最终计算结果。
生成多条随机表达式
(1) 在Generator类中,通过多进程实现表达式生成和IO写入并发。
(2) 一个进程随机生成表达式并放入队列。
(3) 另一个进程从队列中取出表达式,写入文件。
(4) 使用缓冲区方式批量写文件,避免IO频繁。
4. 代码说明
main函数
def mainfuction():
识别命令行参数,调用相应的函数
add_path = ''
# 识别并获取命令行参数
arg = arg_parse()
print("+----------------------------------------------------------+\n"
"| 欢迎使用四则运算算式生成器 |\n"
"+----------------------------------------------------------+\n"
"| 1. -n: 输入并获取生成的题目数量 |\n"
"| 2. -r: 输入并获取参与运算的最大值 |\n"
"| 3. -e: 选择题目文件 |\n"
"| 4. -a: 选择答案文件 |\n"
"+----------------------------------------------------------+\n"
)
# 否则使用命令行操作
try:
# 生成题目及答案或者检查答案,两者不能同时进行
if (arg.e or arg.a) and (arg.n or arg.r):
raise IOError
elif arg.a and arg.e:
# 输入参数正确,执行检查代码部分
inspect(os.path.join(current_path, arg.a[0]), os.path.join(current_path, arg.e[0]))
elif arg.n and arg.r:
# 输入参数正确,执行生成题目和答案文件Grade?.txt
Generator(arg.n[0], arg.r[0]).multi_processor()
else:
print("帮助信息: 参数输入错误")
except Exception as e:
print(e)
检查函数
def inspect(answer_file, expression_file):
# 正确错误列表序号
correct_seq = []
wrong_seq = []
try:
# 读取文件
with open(expression_file, 'r', encoding='utf-8') as fa:
expression_content = fa.readlines()
# 读取文件
with open(answer_file, 'r', encoding='utf-8') as fb:
answer_content = fb.readlines()
# 由答案文件获取序号 再在运算式中找到相对应的题目计算答案 再比较
# 获取列表
for item_b in answer_content:
# 当前答案的行数的序列号
answer_sqe, answer = int(item_b.split('. ')[0]), item_b.split('. ')[1]
# 找到对应的习题的行数
expression = expression_content[answer_sqe - 1]
# ###############################################
# print(answer_sqe, expression)
# 分割字符
pattern = expression.strip().replace(' ', '').replace(' ', '').split('.')[1]
pattern = list(filter(None, split(r'([()×÷+-])', pattern)))
# 提取表达式并计算 如若正确存进
if Calculate(pattern).cal_expression()[0].to_string() == answer.strip():
correct_seq.append(answer_sqe)
# 生成错误列表
for item_a in expression_content:
a_sqe = int(item_a.split('. ')[0])
if a_sqe not in correct_seq:
wrong_seq.append(a_sqe)
# 保存结果
save_inspect(correct_seq, wrong_seq)
except IOError:
print('Failed to open file')
return
计算表达式结果:
class Calculate(object):
def __init__(self, expression):
self.expression = expression
# 分数加法 a1/b1 + a2/b2 = (a1b2 + a2b1)/b1b2
@staticmethod
def fraction_add(fra1, fra2):
molecular = fra1.molecular * fra2.denominator + fra2.molecular * fra1.denominator
denominator = fra1.denominator * fra2.denominator
return Fraction(molecular, denominator)
# 分数减法 a1/b1 - a2/b2 = (a1b2 - a2b1)/b1b2
@staticmethod
def fraction_minus(fra1, fra2):
molecular = fra1.molecular * fra2.denominator - fra2.molecular * fra1.denominator
denominator = fra1.denominator * fra2.denominator
return Fraction(molecular, denominator)
# 分数乘法 a1/b1 * a2/b2 = a1a2/b1b2
@staticmethod
def fraction_multiply(fra1, fra2):
molecular = fra1.molecular * fra2.molecular
denominator = fra1.denominator * fra2.denominator
return Fraction(molecular, denominator)
# 分数除法 a1/b1 ÷ a2/b2 = a1b2/a2b1
@staticmethod
def fraction_divide(fra1, fra2):
molecular = fra1.molecular * fra2.denominator
denominator = fra1.denominator * fra2.molecular
return Fraction(molecular, denominator)
# 基本运算选择器
def operate(self, num1, num2, operater):
if not isinstance(num1, Fraction):
num1 = Fraction(num1)
if not isinstance(num2, Fraction):
num2 = Fraction(num2)
# 计算结果
if operater == '+':
return self.fraction_add(num1, num2)
if operater == '-':
return self.fraction_minus(num1, num2)
if operater == '×':
return self.fraction_multiply(num1, num2)
if operater == '÷':
return self.fraction_divide(num1, num2)
def generate_postfix_expression(self):
# 运算符栈
operator_stack = []
# 后缀栈
postfix_stack = []
for element in self.expression:
# 如果是操作数则添加
if element not in operators:
postfix_stack.append(element)
# 如果是运算符则按优先级
elif element in operator.values():
# 运算符栈为空,或者栈顶为(,则压栈
if not operator_stack or operator_stack[-1] == '(':
operator_stack.append(element)
# 若当前运算符优先级大于运算符栈顶,则压栈
elif priority[element] >= priority[operator_stack[-1]]:
operator_stack.append(element)
# 否则弹栈并压入后缀队列直到优先级大于栈顶或空栈
else:
while operator_stack and priority[element] < priority[operator_stack[-1]]:
postfix_stack.append(operator_stack.pop())
operator_stack.append(element)
# 如果遇到括号
else:
# 若为左括号直接压入运算符栈
if element == '(':
operator_stack.append(element)
# 否则弹栈并压入后缀队列直到遇到左括号
else:
while operator_stack[-1] != '(':
postfix_stack.append(operator_stack.pop())
operator_stack.pop()
while operator_stack:
postfix_stack.append(operator_stack.pop())
return postfix_stack
# 计算表达式(运算过程出现负数,或者除数为0,返回False,否则返回Fraction类)
def cal_expression(self):
# 生成后缀表达式
expressions_result = self.generate_postfix_expression()
# 存储阶段性结果
stage_results = []
# 使用list作为栈来计算
calculate_stack = []
# 后缀遍历
for element in expressions_result:
# 若是数字则入栈, 操作符则将栈顶两个元素出栈
if element not in operators:
calculate_stack.append(element)
else:
# 操作数
num1 = calculate_stack.pop()
# 操作数
num2 = calculate_stack.pop()
# 除数不能为0
if num1 == "0" and element == '÷':
return [False, []]
# 结果
result = self.operate(num2, num1, element)
if result.denominator == 0 or '-' in result.to_string():
return [False, []]
stage_results.append(result.to_string())
# 结果入栈
calculate_stack.append(result)
# 返回结果
return [calculate_stack[0], stage_results]
随机生成表达式
class Generator(object):
def __init__(self, num=10, domain=100, order=0):
self.order = order
# 表达式个数
self.expression_num = num
# 表达式集
self.expressions = []
# 答案集
self.answers = []
# 值域
self.domain = domain
"""
[ [expression1], [expression2], ... ]
"""
# 单次写入的缓冲区
self.buffer_expression = []
self.buffer_answer = []
self.buffer_domain = 1000 if num >= 10000 else 100
"""
用答案作为索引构建的字典,
{
"1'2/2": [
[[压入的数字], [操作数], [运算符]],
[[压入的数字], [操作数], [运算符]],
...
]
}
"""
self.no_repeat_dict = {}
# 检查重复
def judge_repeat(self, answer, test_sign):
for expression_sign in self.no_repeat_dict[answer]:
# 记录相同的个数
same_num = 0
for i in range(3):
if collections.Counter(expression_sign[i]) == collections.Counter(test_sign[i]):
same_num += 1
# 如果中间结果、操作数、运算符均相等,则为重复
if same_num == 3:
return False
return True
# 表达式-生产
def expression_generator(self, queue):
while self.expression_num > 0:
[expression, operand_list, operator_list] = Arithmetic(self.domain).create_arithmetic()
[answer, stage_results] = Calculate(expression).cal_expression()
# 计算错误
if answer:
# 如果该答案不存在字典中,则新建该键值对,否则判断重复,若重复则不添加表达式
stringify_answer = answer.to_string()
if stringify_answer in self.no_repeat_dict:
if self.judge_repeat(stringify_answer, [stage_results, operand_list, operator_list]):
self.no_repeat_dict[stringify_answer].append([stage_results, operand_list, operator_list])
self.expression_num -= 1
res = [expression, answer, self.expression_num]
queue.put(res)
else:
self.no_repeat_dict[stringify_answer] = [[stage_results, operand_list, operator_list]]
self.expression_num -= 1
res = [expression, answer, self.expression_num]
queue.put(res)
# 表达式-消费
def io_operation(self, queue):
index = 0
while True:
index += 1
res = queue.get()
if res is not None:
answer = f"{index}. {res[1].to_string()}"
expression_remain_num = res[2]
expression_str = str(index) + ". "
for item in res[0]:
if item in operator.values():
expression_str += " " + item + " "
else:
expression_str += item
# 存入缓冲区
self.buffer_expression.append(expression_str)
self.buffer_answer.append(answer)
# 缓冲区满100个时 写文件
if index % self.buffer_domain == 0 and expression_remain_num > self.buffer_domain:
# 交由I/O操作函数
save_exercise(self.buffer_expression, self.order)
save_answer(self.buffer_answer, self.order)
# 清空buffer
self.buffer_expression.clear()
self.buffer_answer.clear()
else:
# 交由I/O操作函数
save_exercise(self.buffer_expression, self.order)
save_answer(self.buffer_answer, self.order)
# 清空buffer
self.buffer_expression.clear()
self.buffer_answer.clear()
# exit()
break
# 调用接口 生成多条题目
def multi_processor(self):
start_time = time.time()
queue = multiprocessing.Queue()
producer = multiprocessing.Process(target=self.expression_generator, args=(queue,))
consumer = multiprocessing.Process(target=self.io_operation, args=(queue,))
producer.start()
consumer.start()
producer.join()
queue.put(None)
ene_time = time.time()
print(f"\nBuffer size:{self.buffer_domain}, time cost: {ene_time - start_time}\n")
5. 测试运行
生成题目Exercises.txt:
1. 3'1/4 - 1
2. (3'2/3 × 2'4/7) ÷ 3/6
3. 0 × 5'4/6 - (0 × 0)
4. 2'3/5 ÷ 6
5. 2'6/8 × 7
6. 4'3/5 - 0
7. (1'2/5 × 4'1/2) - (1/2 × 7/9)
8. 8'2/7 - 3/6
9. 2/6 - 0
10. (5'2/7 ÷ 2'2/6) + 9'6/9 + 6'6/7
题目对应结果Answer.txt:
1. 2'1/4
2. 18'6/7
3. 0
4. 13/30
5. 19'1/4
6. 4'3/5
7. 5'41/45
8. 7'11/14
9. 1/3
10. 18'116/147
检查结果Grade.txt:
Correct: 10 [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
Wrong: 0 []
Accuracy: 100.0%
将第一题和第三题的结果修改为错误的之后:
1. 1
2. 18'6/7
3. 2
4. 13/30
5. 19'1/4
6. 4'3/5
7. 5'41/45
8. 7'11/14
9. 1/3
10. 18'116/147
结果为:
Correct: 8 [2, 4, 5, 6, 7, 8, 9, 10]
Wrong: 2 [1, 3]
Accuracy: 80.0%
6. 异常分析
文件保存异常:
# 文件保存位置
if not os.path.exists(root_path):
try:
os.mkdir(root_path)
except:
raise FileNotFoundError
文件读取异常
try:
# 读取文件
with open(expression_file, 'r', encoding='utf-8') as fa:
expression_content = fa.readlines()
# 读取文件
with open(answer_file, 'r', encoding='utf-8') as fb:
answer_content = fb.readlines()
except IOError:
print('Failed to open file')
return
7. 项目小结
通过紧密合作,我们完成了本次作业
- 我们每隔一段时间会讨论项目的进展、遇到的挑战以及下一步的计划,确保了我们的想法和信息能够尽快同步
- 我们进行了明确的分工, 充分发挥了各自的优势
- 在合作中,我们对出现的问题进行统一讨论,有时候我没能解决的问题,对方能解决。我们彼此都能想到对方想不到的点,这样互相完善,比起一个人来说,效率大大提升了
- 在合作项目中,合理把控进度对于按时按质完成项目来说至关重要。我们制定了详细的计划,确保项目按时完成。我们密切监控进展,并及时调整计划。这帮助我们保证了项目最终的完成度。
- 在合作过程中,遇到的困难和挑战应该由所有的的团队成员面对,不能因为不是自己负责的模块就推卸责任

 浙公网安备 33010602011771号
浙公网安备 33010602011771号