
福大软工1816 · 第五次作业 - 结对作业2
1.具体分工
我主要负责的是代码实现和测试,队友负责的是爬虫获取和博客框架撰写;
2.PSP表格:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
| Planning | 计划 | 100 | 120 |
| •Estimate | •估计这个任务需要多少时间 | 1200 | 1300 |
| Development | 开发 | 60 | 60 |
| •Analysis | •需求分析 (包括学习新技术) | 120 | 300 |
| •Design Spec | •生成设计文档 | 20 | 30 |
| •Design Review | •设计复审 | 20 | 40 |
| •Coding Standard | •代码规范(为目前的开发制定合适的规范) | 30 | 50 |
| •Design | •具体设计 | 60 | 80 |
| •Coding | •具体编码 | 240 | 400 |
| •Code Review | •代码复审 | 60 | 120 |
| •Test | •测试(自我测试,修改代码,提交修改) | 20 | 30 |
| Reporting | 报告 | 100 | 150 |
| •Test Repor | •测试报告 | 20 | 35 |
| •Size Measurement | •计算工作量 | 20 | 30 |
| •Postmortem & Process Improvement Plan | •事后总结, 并提出过程改进计划 | 60 | 100 |
| 合计 | 2130 | 2730 |
解题思路描述与设计实现说明
- 爬虫使用
通过使用python的request和beautifulsoup库实现对2018cvpr论文数据的爬取
- 代码组织与内部实现设计(类图)

- 解题思路 :在个人作业1的基础上无非增加了i,o,m,w,n的传参数据,只需要通过main(String[]args)内的
args读入命令行参数,for一遍判断所需功能设置,再将这些参数传导到需要改变的功能,例如权重-n [x]的时
候将x传入ResultComparator内的OUT_limit的参数限制输出便可,其他同理;对2<=m<=10的时候,需要将字
符流分为“字母数字”和“分隔符”流,不断遍历、回溯寻找符合要求的词组拼凑,找出所需要的所有词组。
- 算法的关键与关键实现部分流程图

)
- 通过对题设信息的分析,得出-m的设计流程图,运用分割函数分割和List函数存储,再进行拼凑词组操作。符合条件
的词组将会进入map(word,value)统计词频和储存。
附加题设计与展示
- 设计的独到之处
- 我可以爬取历年的论文,对每年的论文作者做出关系图。也可以对历年论文进行分析统计出发表论文数目
最高的几个作者,国家,地区等,用柱状图进行直观显示。
关键代码解释
- 关键是在对M的判断和“数字字母流” 和“分隔符流”的整合拼凑,拼凑成功则词组这块功能就能成功一大半,
还有就是在读取的时候还需要防止数组溢出。一开始我在这里出现了“分隔符”的数组溢出,没发现,调试了N小时
最后才想起来“数字字母流” 和“分隔符流”的大小不一致!
if (m >= 2 && m <= 10) {//需要记录词组词频时做以下处理
int eachI = 0;//循环条件
String Str = new String();//保存一个词组
int count = 0;//记录词组字符串Str中以保存的单词个数
List<String> myList = new ArrayList<String>();
List<String> anotherSign = new ArrayList<String>();
List<String> anotherword = new ArrayList<String>();
List<String> AllSign = Arrays.stream(line.split("[0-9a-zA-Z]"))//用正则将一行字符中的分隔符提取出来
.collect(Collectors.toList());
for (int z = 0; z < AllSign.size(); z++) {//删除AllSign中多余的"",并将分隔符保存进anotherSign中
if (!AllSign.get(z).equals("")) {
anotherSign.add(AllSign.get(z));
}
}
List<String> AllWords = Arrays.stream(line.split("[^0-9a-zA-Z]"))//用正则将一行单词中的分隔符提取出来
.map(String::toLowerCase)
.collect(Collectors.toList());
for (int t = 0; t <AllWords.size(); t++) {
if (!AllWords.get(t).equals("")) {
anotherword.add(AllWords.get(t));//删除AllWords中多余的"",并将单词保存进anotherword中
}
}
if(anotherword.size()<m){
return; //单词数大于m后处理溢出
}
else {//一次循环保存一个词组或一个合法的单词
for (eachI = 0; eachI < anotherword.size(); eachI++) {
if (isValidWord(anotherword.get(eachI))) {//判断是不是合法单词
if (count < m - 1) {//count用来判断是否加分隔符到Str
if(eachI==anotherword.size()-1) {//读到anotherword的最后一个单词跳出循环
break;
}else{
Str += (anotherword.get(eachI) + anotherSign.get(eachI));//Str加一个合法单词和分隔符
count++;
}
} else {
Str += anotherword.get(eachI);//只加一个合法单词
myList.add(Str);//加入mylist
count = 0;//初始化count和Str
Str = "";
if (eachI == anotherword.size() - 1) {
break;//读到anotherword的最后一个单词跳出循环
} else {
eachI = eachI - m + 1;//保存完一个词组后需要将eachI向前回溯到anotherWord的一个新位置,保证下个词组正确保存
}
}
} else {
Str ="";
count = 0;
}
}
}
性能分析与改进
- 1.增加条件判断,减少程序空间开辟而浪费开销。
- 2.在-m参数里由于循环的使用占用了比较多的时间,主要是由于用正则切割的单词和分隔符时出现了多余的字符,
还要用循环把多余的字符删除。对于这部分的改进我想是不再使用正则切割字符,而是通过逐个读取字符切割,这样
就不会有多余的字符,也就不用循环再删除了。还有就是代码中设有比较多的中间变量,如果能够缩减这些中间变量
的数量就能减少耗时,也不会出现变量溢出的情况。还有就是代码的结构不是很好,类的封装也不是很好,会导致更加
频繁的调用浪费时间,以及代码的重复率也有一些高。要想改进的话就是尽量的分配好类的功能。
- 3.对程序执行1000次得到性能分析图
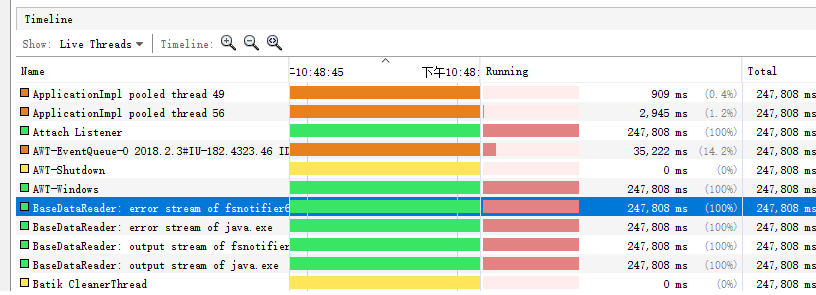


单元测试
- 图1 -i input.txt -w 0 -o result.txt // 图1~2均是必输入参数设置,且区别权重

- 图2 -i input.txt -w 1 -o result.txt //图2权重设置,
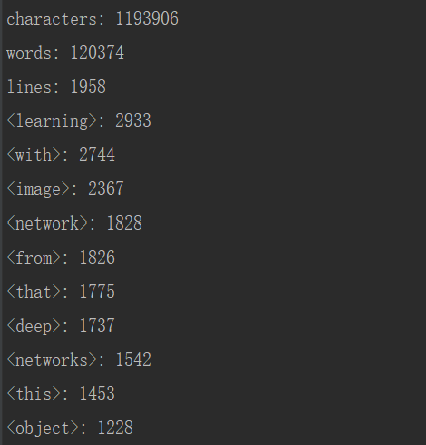
- 图3 -i input.txt -w 0 -m 5 -o reuslt.txt //图3设置词组长度,可以和图1做区别

- 图4 -i input.txt -w 0 -m 5 -n 5 -o reuslt.txt //图4与3做对比

- 图5 -i input.txt -w 0 -n 5 -o result.txt //图5只置设置权重,可以与图4对比

- 图6 -w 0 -n 5 -i input.txt -o result.txt
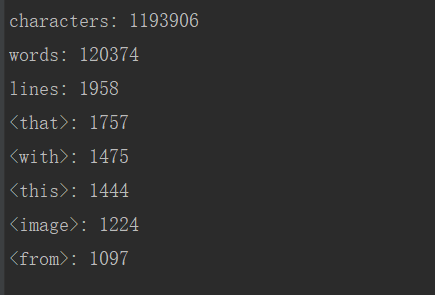
- 图7 -n 5 -w 1 -i input.txt -o result.txt //图7设置权重,其余参数和图6一致

Github的代码签入记录
- 我们是测试好了代码才上传提交的,所以只提交了一次。

遇到的代码模块异常或结对困难及解决方法
- 问题描述
- 本次实践遇到的最大困难就是如何实现-m参数。词组的单词之间需要有分隔符,但是我们原先的代码是没有保存分隔符,
导致-m参数无法实现;后来通过简单粗暴的分割成两个流的做法,发现split函数的缺点发挥的淋漓尽致,又出现保存了N多空
串现象;之后在拼凑时又出现很隐秘、难以发现的数组越界。
- 解决尝试
- 起初我们想对一整行的字符进行分析,然后直接从一整行的字符里取出合法的词组,但是难以实现且会遗漏一些词组。
于是我们改进了代码,将单词和分隔符都分别保存成字符串数组,但是没有好的算法将分隔符和单词结合成一个词组。之
后成功保存后又因为使用的是正则,导致多保存空白字符,无法合成词组;就尝试再创一个List来存储去掉空串后的
两个字符串流,才得以保证接下来拼凑正确无误的词组。
- 问题解决与收获
- 在将单词和分隔符都分别保存成字符串数组以及删去多余的空白字符的基础上,我们用一个循环分别交替遍历两个数组,
依次地将合法的单词和分隔符间隔加入到一个字符串里,这样就能够获得所有的合法词组。这个问题困扰了我们好长时间,
但最终也算是找到了一个虽然不是很好的解决办法,我们还是十分的高兴的。主要还是知识上有所欠缺,找不到合理又高效
的解决办法,所以也提醒我们要好好的补充一些有关Java的知识,希望下次再碰到这种情况时我们就能够很快的解决了 。
评价你的队友
- 1.跃安兄弟学习能力、思维逻辑超强,超快解决爬虫载入问题,国庆回来马上就能投入对软工实践的战斗中去,安哥几乎是有求必应
的状态,每次都能一起并肩作战,合力肝软工。有一次凌晨喊他一起对最后一步代码设计攻坚,没有半点犹豫被我坑过来一起见证凌晨4点
的福大,并为我的程序代码提出很多优化性的建议。
- 2.再说什么JAVA初学者感觉总觉的一直在找藉口开脱,但对java内大量方法和功能运用确实不娴熟,好在这几次作业下来已经对
经常使用的方法有了深刻的认识,也是很令人开心的收获。
学习进度条
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 200 | 200 | 18 | 18 | 使用eclpise编写java,并运用单元测试和性能分析 |
| 2 | 200 | 200 | 14 | 32 | 接触墨刀、Axure等原型设计软件 |
| 3 | 200 | 200 | 5 | 37 | 使用Trello、石墨文本协助团队软件 |
| 4 | 300 | 500 | 20 | 57 | 换成Itellij IDEA 编写java,使用jprofiler性能分析;语言方面对更多方法有深刻了解 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号