

AMDGPU核心资源详解
下图清晰地展示了AMD GPU一个计算单元的主要硬件资源组成及其层次关系:
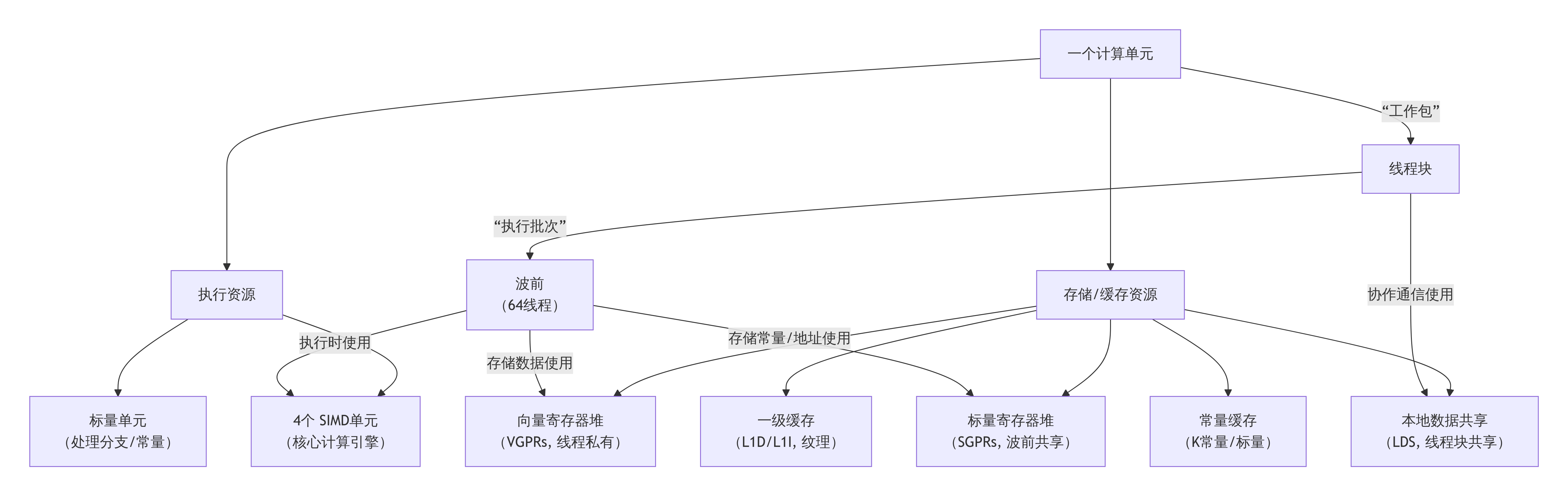
一个CU的资源总量由具体GPU架构(如gfx908/MI100, gfx90a/MI210, gfx942/MI300)决定。我们以常见的CDNA2架构(例如MI210) 为例进行说明。
1. 向量寄存器
这是数量最多、最关键的线程私有资源。
用途:存储内核函数中定义的局部变量、中间计算结果。每个线程的运算数据都放在自己的VGPR中。
硬件:一个大容量的VGPR文件,被所有驻留的线程共享。
配额限制:
每个CU的总量:例如,CDNA2架构有 65,536个(64K)可用的32位VGPR。
每个波前的分配:VGPR是按波前为单位进行分配和管理的。如果一个内核要求每个线程使用 V 个VGPR,那么:
每个波前申请 V * 64 个VGPR(因为一个波前有64个线程)。
然而,硬件分配有粒度!为了管理效率,VGPR的分配不是任意数,而是按照一个“Granularity”(例如,CDNA2是8个VGPR/线程)的倍数向上取整。
关键影响:VGPR的消耗直接决定了一个CU上能同时驻留多少个波前。这是限制GPU并行度的首要因素之一。
2. 标量寄存器
这是波前内共享的、关键的公用资源。
用途:存储波前内所有线程相同的值,例如:循环计数、内核函数的参数指针、内存地址的基址、由标量单元计算的地址偏移等。
硬件:一个独立的SGPR文件。
配额限制:
每个CU的总量:例如,CDNA2架构有 8,192个(8K)SGPR。
每个波前的分配:按波前分配。如果一个内核需要 S 个SGPR/波前,硬件同样会按特定粒度(例如,CDNA2是16个SGPR/波前)向上取整后分配。
关键影响:SGPR不足会导致内核编译失败。但通常SGPR不是瓶颈,因为数量相对充足。
3. 本地数据共享
这是线程块内共享的、可编程的高速缓存。
用途:线程块内所有线程通信和协作的“黑板”。用于归约、转置、共享查找表等需要频繁数据交换的算法。
硬件:一块SRAM,物理上与CU绑定,逻辑上分配给驻留的线程块。
配额限制:
每个CU的总量:固定大小,例如 64KB。
每个线程块的分配:在内核启动时通过 __shared__ 或 hipDynamicShared 声明或指定。分配单位通常是 1KB的倍数。
关键影响:LDS使用量是限制每个CU上能并发执行多少个线程块的另一个主要因素。
资源使用示例与优化启示
假设你在CDNA2架构的GPU上运行一个内核,每个线程需要28个VGPR,每个波前需要80个SGPR,每个线程块申请了16KB的LDS。
1、VGPR计算:
每个波前需求:28 VGPR/线程 * 64 线程 = 1792 VGPR。
分配粒度(8):ceil(1792 / (64*8)) * (64*8) = ceil(1792/512)*512 = 4*512 = 2048 VGPR/波前。
每个CU可驻留波前数:65,536 / 2048 ≈ 32 个波前。
2、SGPR计算:
每个波前需求:80 SGPR。
分配粒度(16):ceil(80/16)*16 = 5*16 = 80 SGPR/波前(恰好满足)。
每个CU可驻留波前数:8,192 / 80 ≈ 102 个波前,远多于VGPR限制,所以VGPR是瓶颈。
3、LDS计算:
每个线程块需求:16KB。
每个CU可驻留线程块数:64KB / 16KB = 4 个线程块。
如果每个线程块有256个线程(4个波前),那么4个线程块共需要 4块 * 4波前/块 = 16个波前。
这与VGPR计算出的 32个波前 上限不冲突,因此实际限制是LDS,该CU最多同时驻留4个线程块(16个波前)。
CU、线程块与资源的动态关系
当一个内核被启动,成千上万个线程块在GPU的所有CU上进行分发时,过程如下:
1、全局分发:GPU的全局工作分配器会将线程块尽可能均匀地分发到所有可用的CU上。它追求的是让所有CU都忙起来。
2、CU本地接纳:每个CU都有一个资源管理器。当一个线程块被分配过来时,管理器会立刻检查本CU当前的剩余资源:
剩余的VGPR是否够容纳这个线程块所有线程的需求?
剩余的SGPR是否够这个线程块的波前们使用?
剩余的LDS空间是否够这个线程块申请的大小?
3、资源划拨与驻留:如果资源充足,CU就会为这个线程块划拨出相应数量的VGPR、SGPR和LDS,然后允许其驻留在本CU。此时,这个线程块的所有波前就进入了本CU的调度队列,等待执行。
持续接纳,直至饱和:只要资源还有剩余,这个CU就会继续接纳新的线程块,为其划拨资源,增加驻留的波前数量。这个过程会一直持续到某个关键资源被耗尽(通常是VGPR或LDS)。此时,该CU就达到了最大驻留线程块数。
posted on 2025-12-24 08:59 lh03061238 阅读(6) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号