
爬虫笔记(一)
爬虫基本分为几步:
1、找到RUL
URL不一定是网址,最准确的是打开网页抓包工具(网页按F12)

2、查看网页是get还是post请求。
get请求用requests.get(),post请求用requests.post();此方法的返回值是网页response的类型。常见的有json、test等格式。还是需要通过抓包工具(同上),找到Content-Type,就是返回格式。
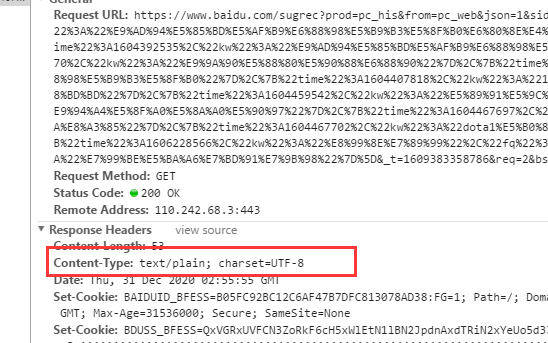
3、以requests.get()为例,requests.get()中有三个参数(目前所接触到的),requests.get(url,params,headers)
url是请求的网页;params是网页参数,动态抓取需要用到;headers是利用UA伪装,模拟浏览器发起请求,不同的浏览器UA不一样,还是用抓包工具查看,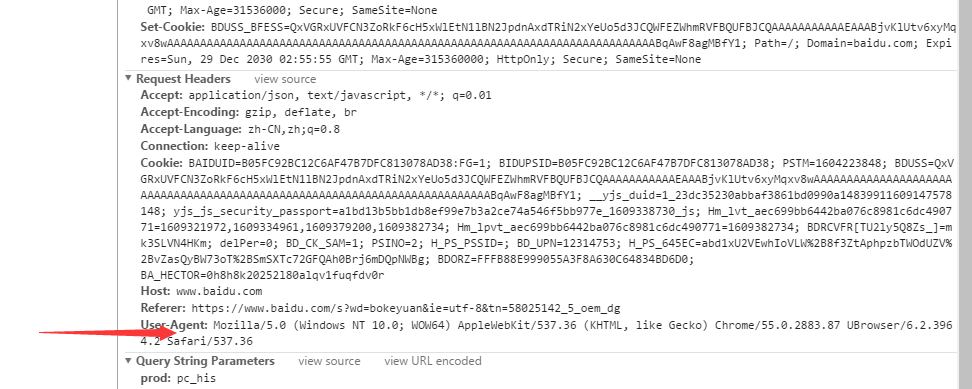
4、解析返回内容。如果网页返回的是json格式,利用responses.json()将json转成字典,可查;如果是text格式,直接.test()就可以。
5、利用python文件功能,保存数据。
with open('./sogou.html','w',encoding='utf-8') as op:
op.write(page_test)
这种文件打开办法,不用open之后再close,方便很多。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号