每周一记——10.11(转正后的第一个星期)
转正之前的两周,就接到了一个任务,关于编译原理的一个任务,在应用中嵌入sql的语句,然后把对应的sql通过预编译的方式转换为C语言,对于我这颗小白菜,我的任务就是把已经通过yyac语法分析生成的语法树,转换为对应的C语言文本。至于为什么要这样做,就是带有嵌入sql的程序,是没有一个编译器能够识别的,只有把用户写的.pc文件,转换为.c文件,才能让C语言编辑器识别。根据.y文件的文法,根据语法树生成的node反向转换为字符串文本,因为在语法分析阶段,会把终结符给筛选出来,只关注非终结符,并生成相应的数据结构node。所以在反向转换为字符串的时候,我们需要手动的补全所有的终结符。大致的分析过程如下:同时我也会举出一些代码实例来更好的阐述我其本质。
首先从文法的开始符号开始分析,已知条件,C语言文法对应的.y文件、根据用户输入的语句已经生成了一棵语法树,vs2017编译器。求出用户原本输入的字符串,声明一个字符串变量c_str。
就拿最简单的声明变量的对应的C语言语句" float x,y"这是用户原本输入的。但是我们得到只得的是一棵语法树,通过语法树自己推出用户的输入。这个过程是通过语法规则来推,而且是自顶向下的,你需要不断的从开始符号开始,不断的往下递归,需要一个node就建立一个case,在case中分析该node所进行规约的分支,然后把对应的非终结符给补全c_str += “,”。有的非终结符号对应的是两条以上的分支,例如E::=T+i|F,所以你需要判断到底选择了哪条分支进行了规约或者移入,这个判断是需要根据后续生成的node反向判断到底选择了哪个分支,如果下一个比如T::=H,此时并没有可以规约的,而是继续移入,直到遇到了一个生成的node,例如H::=i+i,此时可以进行规约了,根据该node的数据结构中,例如CTypeSpac这个node,对该node中成员typename进行赋值,.y文件中对应的就是ctypespec->typename = $1;然而你需要这样写代码case T_CTypeSpec:
{
CTypeSpec *ctypespec = (CTypeSpec*)p_node ;//p_node是定义的一个node数据类型,
if(ctypespec ->typename)
{
//这个分支就是对应的E::=T+i这条规则
T//这里无法直接规约,而是移入,所欲又需要根据下面的规则继续分析。
c_str += "+ i";
}
else
{
//这条分支就是对应的E::=F;这条规则
}
}
总之上面是自顶向下分析,需要通过规约的node里面的内容进行分析选择的是哪一条规则,并且越是在语法树树顶的终结符越是最后被添加进c_str中。最后把这些抽象的理清楚之后,便是具体的代码书写,其本质一条语句就是遍历一棵语法树,而且是从根结点开始遍历,遇见一个结点就建立一个case,以便后面的重复调用和自己递归调用。
下面以一棵C语言声明变量的语法数,来推出用户输入"float x,y";其文法规则可参考https://blog.csdn.net/rill_zhen/article/details/7701259 ,从网上找一棵该语法的语法树,如下图所示
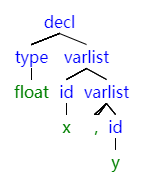
//其对应的.y文件
decl::=type
{
$$ = $1;
}
|var_list
{
$$ = $1;
};
type::= float
{
T_type *type = makeNode(T_type);
type->token = _FLOAT;
type->typename = $1;
$$ = (Node*)type;
};
var_list::=id
{
T_type *type = makeNode(T_type);
type->typename = $1;
$$ = (Node*)type;
}
|, var_list
{
T_type *type = makeNode(T_type);
type->var_list = $2;
};
//其对应的C语言遍历过程
case T_type
{
T_type *type = makeNode(T_type*)node;
if(type->token)
{
c_str += type->typename;
c_str += " ";
}
else
{
if(type->typename)
{
c_str += type->typename;
foreach(l,type->varlist)
{
c_str += " , ";
type = lptr(l);
c_str += type->typename;
}
}
}
}
上述遍历的语法树就到此为止,整个过程就是该反推语句的其中一个完整的过程,对于反反复复和其它的所有的语句,就是另一个完全的新的语法树,或者比这个更大的语法树。
总结:刚开始的时候我无法自顶向下思考,自底向上补全字符串,所以就去看了语法树自顶向下推导的过程和自底向上规约的过程,然后得出其实这整个过程核心算法就是遍历一棵树,从顶到下的遍历一棵树,其余就是一直反向判断和建立新的case。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号