k8s 通过kafka operator部署kafka集群
注意:如果在一个k8s集群用operator部署了多个kafka集群,想删除一个kafka集群,不能kc delete -f strimzi-install.yaml,否则会删除k8s所有的
用operator部署的kafka集群
使用的operator是strimzi,官方文档:https://strimzi.io/quickstarts/
1、应用 Strimzi 安装文件,包括 `<Strimzi-install-files>`ClusterRoles和ClusterRoleBindings一些自定义资源定义( CRD)。CRD 定义了用于自定义资源(例如` CRDs<Cafka-container-class>` 等)的模式,这些资源将用于管理 Kafka 集群、主题和用户。
kubectl create -f 'https://strimzi.io/install/latest?namespace=kafka-2' -n kafka-2
配置节点亲和性和容忍让operator部署在特定节点组的机器(可选)
wget -O strimzi-install.yaml 'https://strimzi.io/install/latest?namespace=kafka-2'
大概在24785行,搜索Deployment比较准确
--- apiVersion: apps/v1 kind: Deployment metadata: name: strimzi-cluster-operator labels: app: strimzi namespace: kafka-2 spec: replicas: 1 selector: matchLabels: name: strimzi-cluster-operator strimzi.io/kind: cluster-operator template: metadata: labels: name: strimzi-cluster-operator strimzi.io/kind: cluster-operator spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: # 使用正确的标签键 - key: eks.amazonaws.com/nodegroup operator: In values: - EKS-Prod-StatefulSet-1V31 # 在这里添加 tolerations tolerations: - key: "app" operator: "Equal" value: "statefulset" effect: "NoSchedule" serviceAccountName: strimzi-cluster-operator
2、查看操作员的日志
kubectl logs deployment/strimzi-cluster-operator -n kafka-2 -f
3、创建一个新的 Kafka 自定义资源,以获取 Apache Kafka 集群
vim kafka-single-node.yaml
pod亲和性和容忍自行添加(可选)
apiVersion: kafka.strimzi.io/v1 kind: KafkaNodePool metadata: name: kafka namespace: kafka-3 labels: strimzi.io/cluster: mq spec: replicas: 3 roles: - controller - broker storage: type: jbod volumes: - id: 0 type: persistent-claim size: 1500Gi deleteClaim: false kraftMetadata: shared class: gp3-us-west-2c resources: requests: cpu: "300m" memory: "1Gi" template: pod: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: eks.amazonaws.com/nodegroup operator: In values: - EKS-Prod-Kafka-Logging tolerations: - key: "app" operator: "Equal" value: "kafka" effect: "NoSchedule" --- apiVersion: kafka.strimzi.io/v1 kind: Kafka metadata: name: mq namespace: kafka-3 spec: kafka: version: 4.1.1 metadataVersion: 4.1-IV1 listeners: - name: plain port: 9092 type: internal tls: false - name: tls port: 9093 type: internal tls: true config: auto.create.topics.enable: false # 新增:关闭自动创建主题 offsets.topic.replication.factor: 2 transaction.state.log.replication.factor: 2 transaction.state.log.min.isr: 2 default.replication.factor: 2 min.insync.replicas: 2 log.retention.hours: 8 log.segment.bytes: 1073741824 # 可选:topic消息限制 message.max.bytes: 67108864 replica.fetch.max.bytes: 73400320 fetch.max.bytes: 75497472 max.request.size: 7340032 # 可选:确保外部listener的通告地址正确(Strimzi会自动生成,此配置可省略) advertised.listeners: "#{KAFKA_ADVERTISED_LISTENERS}" entityOperator: topicOperator: {} userOperator: {} # 修正:使用正确的template语法 template: pod: # 修正:在entityOperator的template下直接配置 metadata: labels: eks.amazonaws.com/nodegroup: EKS-Prod-Kafka-Logging # 修正:这里可能需要使用affinity而不是nodeSelector affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: eks.amazonaws.com/nodegroup operator: In values: - EKS-Prod-Kafka-Logging tolerations: - key: "app" operator: "Equal" value: "kafka" effect: "NoSchedule" # 为deployment配置 deployment: metadata: labels: eks.amazonaws.com/nodegroup: EKS-Prod-Kafka-Logging
提供外部访问(可选)
apiVersion: kafka.strimzi.io/v1 kind: KafkaNodePool metadata: name: kafka namespace: kafka-3 labels: strimzi.io/cluster: mq spec: replicas: 3 roles: - controller - broker storage: type: jbod volumes: - id: 0 type: persistent-claim size: 1500Gi deleteClaim: false kraftMetadata: shared class: gp3-us-west-2c resources: requests: cpu: "300m" memory: "1Gi" template: pod: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: eks.amazonaws.com/nodegroup operator: In values: - EKS-Prod-Kafka-Logging tolerations: - key: "app" operator: "Equal" value: "kafka" effect: "NoSchedule" --- apiVersion: kafka.strimzi.io/v1 kind: Kafka metadata: name: mq namespace: kafka-3 spec: kafka: version: 4.1.1 metadataVersion: 4.1-IV1 listeners: - name: plain port: 9092 type: internal tls: false - name: tls port: 9093 type: internal tls: true # 新增外部NodePort listener(核心修改) - name: external port: 9094 # 容器内独立端口,避免和内部9092冲突 type: nodeport tls: false configuration: # 指定外部访问的NodePort和broker映射 bootstrap: nodePort: 32518 # 你暴露的外部NodePort brokers: - broker: 0 # 第一个broker ID(Kraft模式从0开始) nodePort: 32519 - broker: 1 # 第二个broker ID nodePort: 32520 - broker: 2 # 第三个broker ID nodePort: 32521 config: auto.create.topics.enable: false # 新增:关闭自动创建主题 offsets.topic.replication.factor: 2 transaction.state.log.replication.factor: 2 transaction.state.log.min.isr: 2 default.replication.factor: 2 min.insync.replicas: 2 log.retention.hours: 8 log.segment.bytes: 1073741824 # 可选:topic消息最大限制 message.max.bytes: 67108864 replica.fetch.max.bytes: 73400320 fetch.max.bytes: 75497472 max.request.size: 73400320 # 可选:确保外部listener的通告地址正确(Strimzi会自动生成,此配置可省略) advertised.listeners: "#{KAFKA_ADVERTISED_LISTENERS}" entityOperator: topicOperator: {} userOperator: {} # 修正:使用正确的template语法 template: pod: # 修正:在entityOperator的template下直接配置 metadata: labels: eks.amazonaws.com/nodegroup: EKS-Prod-Kafka-Logging # 修正:这里可能需要使用affinity而不是nodeSelector affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: eks.amazonaws.com/nodegroup operator: In values: - EKS-Prod-Kafka-Logging tolerations: - key: "app" operator: "Equal" value: "kafka" effect: "NoSchedule" # 为deployment配置 deployment: metadata: labels: eks.amazonaws.com/nodegroup: EKS-Prod-Kafka-Logging
让 3 个 Kafka broker 强制分散在 3 台不同 EC2 节点(可选)
apiVersion: kafka.strimzi.io/v1 kind: KafkaNodePool metadata: name: kafka namespace: kafka labels: strimzi.io/cluster: mq spec: replicas: 3 roles: - controller - broker storage: type: jbod volumes: - id: 0 type: persistent-claim size: 500Gi deleteClaim: false kraftMetadata: shared class: gp3-us-west-2c resources: requests: cpu: "1000m" memory: "4Gi" template: pod: affinity: # 新增:Pod 反亲和性,强制 broker 分散在不同节点 podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: strimzi.io/cluster operator: In values: - mq topologyKey: kubernetes.io/hostname nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: eks.amazonaws.com/nodegroup operator: In values: - eks-prod-paimatix-shared-critical-Az3 tolerations: - key: "priority" operator: "Equal" value: "critical" effect: "NoSchedule" --- apiVersion: kafka.strimzi.io/v1 kind: Kafka metadata: name: mq namespace: kafka spec: kafka: version: 4.1.1 metadataVersion: 4.1-IV1 listeners: - name: plain port: 9092 type: internal tls: false - name: tls port: 9093 type: internal tls: true # 新增外部NodePort listener(核心修改) - name: external port: 9094 # 容器内独立端口,避免和内部9092冲突 type: nodeport tls: false configuration: # 指定外部访问的NodePort和broker映射 bootstrap: nodePort: 32518 # 你暴露的外部NodePort brokers: - broker: 0 # 第一个broker ID(Kraft模式从0开始) nodePort: 32519 - broker: 1 # 第二个broker ID nodePort: 32520 - broker: 2 # 第三个broker ID nodePort: 32521 config: auto.create.topics.enable: false # 新增:关闭自动创建主题 offsets.topic.replication.factor: 2 transaction.state.log.replication.factor: 2 transaction.state.log.min.isr: 2 default.replication.factor: 3 min.insync.replicas: 1 log.retention.hours: 168 log.segment.bytes: 1073741824 # 可选:topic消息限制 message.max.bytes: 67108864 replica.fetch.max.bytes: 73400320 fetch.max.bytes: 75497472 max.request.size: 7340032 # 可选:确保外部listener的通告地址正确(Strimzi会自动生成,此配置可省略) advertised.listeners: "#{KAFKA_ADVERTISED_LISTENERS}" entityOperator: topicOperator: {} userOperator: {} # 修正:使用正确的template��法 template: pod: # 修正:在entityOperator的template下直接配置 metadata: labels: eks.amazonaws.com/nodegroup: eks-prod-paimatix-shared-critical-Az3 # 修正:这里可能需要使用affinity而不是nodeSelector affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: eks.amazonaws.com/nodegroup operator: In values: - eks-prod-paimatix-shared-critical-Az3 tolerations: - key: "priority" operator: "Equal" value: "critical" effect: "NoSchedule" # 为deployment配置 deployment: metadata: labels: eks.amazonaws.com/nodegroup: eks-prod-paimatix-shared-critical-Az3
kc apply -f kafka-single-node.yaml
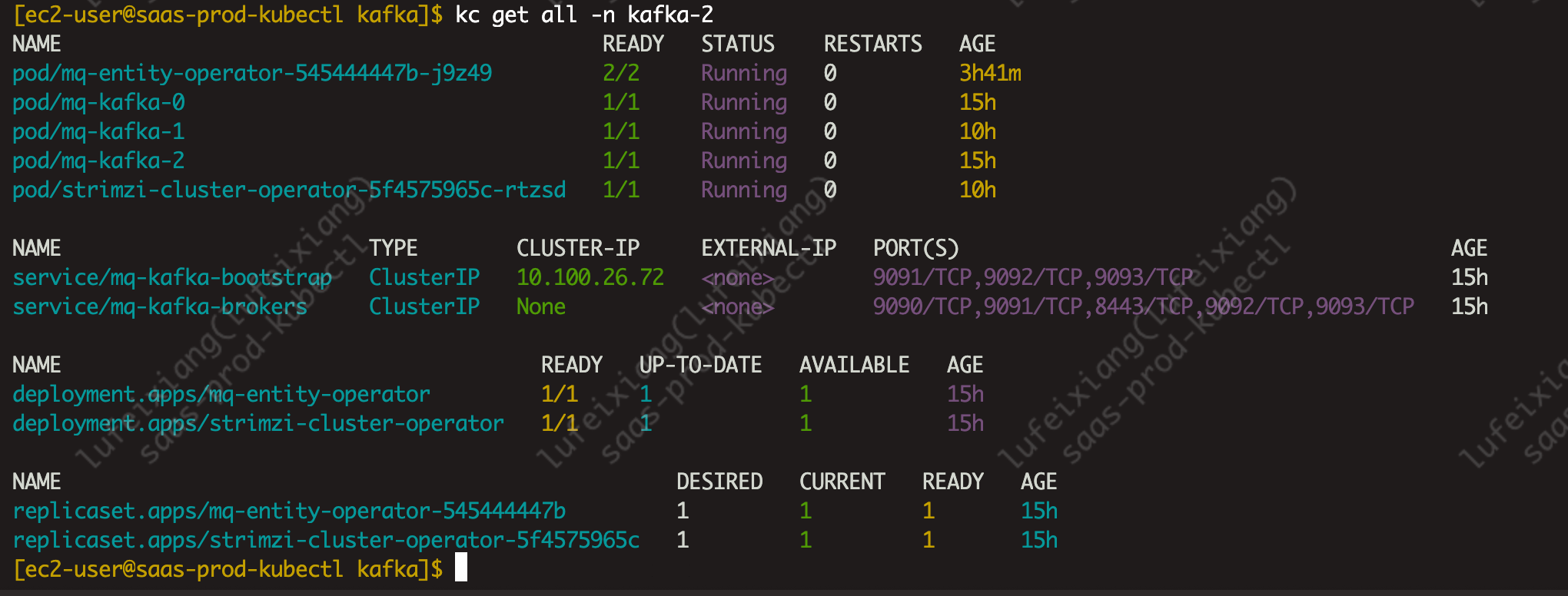
4、查看pod运行状态

 浙公网安备 33010602011771号
浙公网安备 33010602011771号