Pix2Pix的原理及Pytorch实现
follow this video: https://www.youtube.com/watch?v=SuddDSqGRzg&ab_channel=AladdinPersson
paper: https://arxiv.org/pdf/1611.07004.pdf
只讲一下我发现的,与普通GAN的几点差异
区别一: 生成器采用U-Net结构
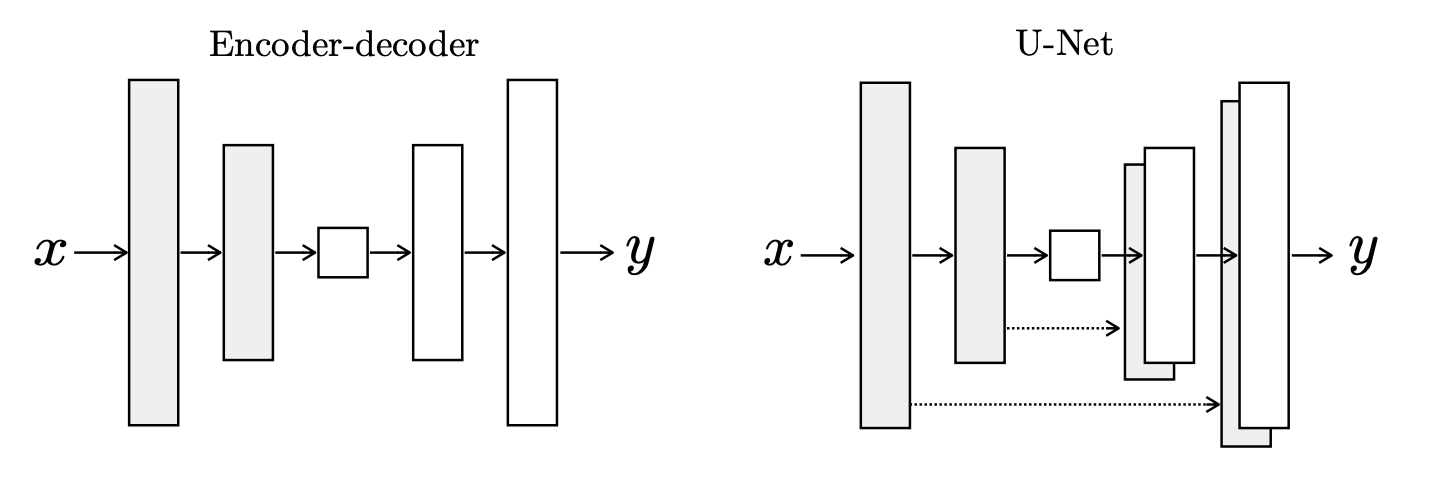
作者提供了上面的两种选择方案,左边是简单的编码器解码器结构,右边是采用skip-connection(跳跃连接)的结构。每层采用“convolution-BatchNorm-ReLU”的方式进行搭建。
区别二: 判别器的结果是个N x N的Patch,而不是1 x 1
即判别器使用PatchGAN,众所周知(??,L2和L1 loss能准确捕捉低频信息,但不能捕捉高频信息,因此我们的GAN判别器只需要对高频结构建模。
为了对高频图像进行建模,将注意力限制在局部图像块的结构上就够了
具体做法如下:(没懂

原理如下:(还是没懂,马尔科夫随机场?

区别三:生成器加上了L1 loss
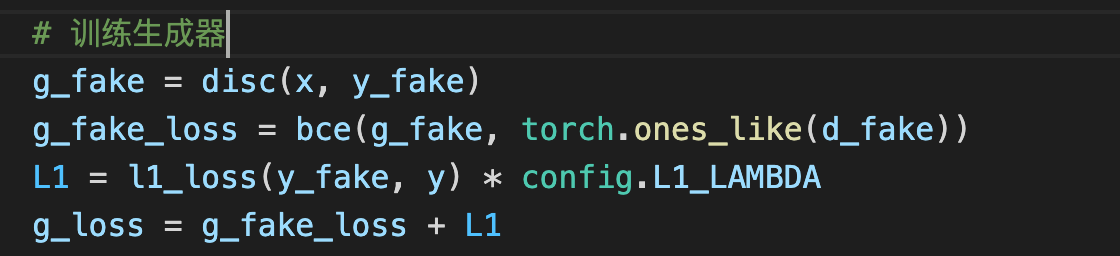
效果: 
L1还原低频,cGAN还原高频,合起来就比较完整了。
完整代码:https://github.com/growvv/GAN-Pytorch/tree/main/Pix2Pix
个性签名:时间会解决一切

 浙公网安备 33010602011771号
浙公网安备 33010602011771号