linux命令(面试向)
top命令
相当于linux下的任务管理器,
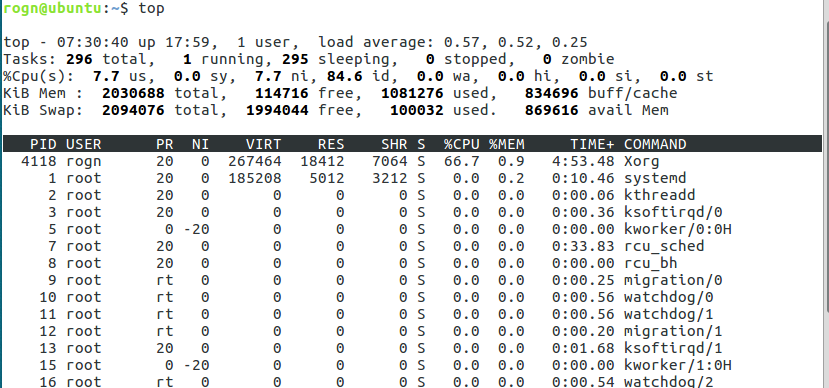
第四行(Mem)
分别表示了内存总量、空闲内存量、当前使用量、以及缓冲使用中的内存量;
第五行(Swap)
表示类别同第四行(Mem),但此处反映着交换分区(Swap)的使用情况。通常,交换分区(Swap)被频繁使用的情况,将被视作物理内存不足而造成的。
进程列表
PID:进程的ID USER:进程所有者 PR:进程的优先级别,越小越优先被执行 NInice:值 VIRT:进程占用的虚拟内存 RES:进程占用的物理内存 SHR:进程使用的共享内存 S:进程的状态。S表示休眠,R表示正在运行,Z表示僵死状态,N表示该进程优先值为负数 %CPU:进程占用CPU的使用率 %MEM:进程使用的物理内存和总内存的百分比 TIME+:该进程启动后占用的总的CPU时间,即占用CPU使用时间的累加值。 COMMAND:进程启动命令名称
free命令
在Linux下查看内存我们一般用free命令:

total:总计物理内存的大小。 used:已使用多大。 free:可用有多少。 Shared:多个进程共享的内存总额。 Buffers/cached:磁盘缓存的大小。 第三行(-/+ buffers/cached): used:已使用多大。 free:可用有多少。
SWAP就是LINUX下的虚拟内存分区,它的作用是在物理内存使用完之后,将磁盘空间(也就是SWAP分区)虚拟成内存来使用 。
netstat
了解当前系统开放了哪些端口,并且要查看开放这些端口的具体进程和用户,可以通过netstat命令进行简单查询
netstat命令各个参数说明如下:
-t : 指明显示TCP端口
-u : 指明显示UDP端口
-l : 仅显示监听套接字(所谓套接字就是使应用程序能够读写与收发通讯协议(protocol)与资料的程序)
-p : 显示进程标识符和程序名称,每一个套接字/端口都属于一个程序。
-n : 不进行DNS轮询,显示IP(可以加速操作)
即可显示当前服务器上所有端口及进程服务,于grep结合可查看某个具体端口及服务情况··
netstat -ntlp //查看当前所有tcp端口·
netstat -ntulp |grep 80 //查看所有80端口使用情况·
netstat -ntulp | grep 3306 //查看所有3306端口使用情况·
grep命令
基本格式:find expression
[options]主要参数:
-c:只输出匹配行的计数。
-i:不区分大小写
-h:查询多文件时不显示文件名。
-l:查询多文件时只输出包含匹配字符的文件名。
-n:显示匹配行及行号。
-s:不显示不存在或无匹配文本的错误信息。
-v:显示不包含匹配文本的所有行。
pattern正则表达式主要参数:
\: 忽略正则表达式中特殊字符的原有含义。
^:匹配正则表达式的开始行。
$: 匹配正则表达式的结束行。
\<:从匹配正则表达 式的行开始。
\>:到匹配正则表达式的行结束。
[ ]:单个字符,如[A]即A符合要求 。
[ - ]:范围,如[A-Z],即A、B、C一直到Z都符合要求 。
.:所有的单个字符。
* :有字符,长度可以为0。
实例
(1)grep 'test' d* #显示所有以d开头的文件中包含 test的行
(2)grep ‘test’ aa bb cc #显示在aa,bb,cc文件中包含test的行
(3)grep ‘[a-z]\{5\}’ aa #显示所有包含每行字符串至少有5个连续小写字符的字符串的行
(4)grep magic /usr/src #显示/usr/src目录下的文件(不含子目录)包含magic的行
(5)grep -r magic /usr/src #显示/usr/src目录下的文件(包含子目录)包含magic的行
参考链接:
1. https://baike.baidu.com/item/Swap/2666174
2. https://blog.csdn.net/ws379374000/article/details/74218530
3. https://www.cnblogs.com/xudong-bupt/archive/2013/03/23/2976793.html
grep命令
基本格式:find expression
1.主要参数
[options]主要参数:
-c:只输出匹配行的计数。
-i:不区分大小写
-h:查询多文件时不显示文件名。
-l:查询多文件时只输出包含匹配字符的文件名。
-n:显示匹配行及行号。
-s:不显示不存在或无匹配文本的错误信息。
-v:显示不包含匹配文本的所有行。
pattern正则表达式主要参数:
\: 忽略正则表达式中特殊字符的原有含义。
^:匹配正则表达式的开始行。
$: 匹配正则表达式的结束行。
\<:从匹配正则表达 式的行开始。
\>:到匹配正则表达式的行结束。
[ ]:单个字符,如[A]即A符合要求 。
[ - ]:范围,如[A-Z],即A、B、C一直到Z都符合要求 。
.:所有的单个字符。
* :有字符,长度可以为0。
2.实例
(1)grep 'test' d* #显示所有以d开头的文件中包含 test的行
(2)grep ‘test’ aa bb cc #显示在aa,bb,cc文件中包含test的行
(3)grep ‘[a-z]\{5\}’ aa #显示所有包含每行字符串至少有5个连续小写字符的字符串的行
(4)grep magic /usr/src #显示/usr/src目录下的文件(不含子目录)包含magic的行
(5)grep -r magic /usr/src #显示/usr/src目录下的文件(包含子目录)包含magic的行
(6)grep -w pattern files :只匹配整个单词,而不是字符串的一部分(如匹配’magic’,而不是’magical’),

 浙公网安备 33010602011771号
浙公网安备 33010602011771号