MySQL数据库的读写分离、分库分表
一、读写分离
因为用户的增多,数据的增多,单机的数据库往往支撑不住快速发展的业务,所以数据库集群就产生了!
读写分离顾名思义就是读和写分离了,对应到数据库集群一般都是一主一从(一个主库,一个从库)或者一主多从(一个主库,多个从库),业务服务器把需要写的操作都写到主数据库中,读的操作都去从库查询。主库会同步数据到从库保证数据的一致性。
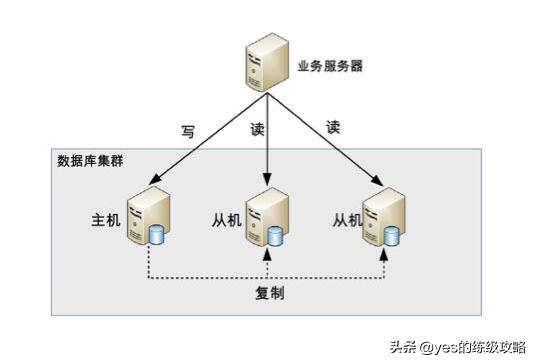
这种集群方式的本质就是把访问的压力从主库转移到从库,适合读的请求较多的情况下。
在单机的情况下,一般我们做数据库优化都会加索引,但是加了索引对查询有优化,但是会影响写入,因为写入数据会更新索引。所以做了主从之后,我们可以单独的针对从库(读库)做索引上的优化,而主库(写库)可以减少索引而提高写的效率。
看起来还是很简单的,但是有两点要注意:主从同步延迟、分配机制的考虑;
主从同步延迟
主库有数据写入之后,同时也写入在binlog(二进制日志文件)中,从库是通过binlog文件来同步数据的,这期间会有一定时间的延迟,可能是1秒,如果同时有大量数据写入的话,时间可能更长。
所以为了解决主从同步延迟的问题有以下几个方法:
1. 二次读取:意思就是读从库没读到之后再去主库读一下
2. 写之后的马上的读操作访问主库
3. 关键业务读写都由主库承担,非关键业务读写分离
二、分库分表
主从集群也就是读写分离,其实只是分担了访问的压力,但是存储的压力没有解决。
分库
假设数据库中有两张表分别是用户表和订单表。如果要分库的话现在你需要买两台机子,搞两个数据库分别放在两台机子上,并且一个数据库放用户表,一个数据库放订单表。
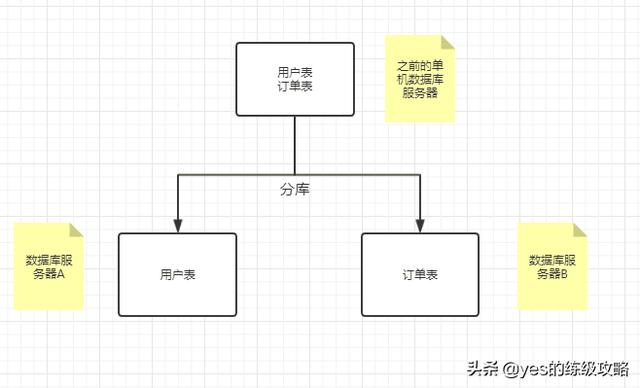
这样存储压力就分担到两个服务器上了,但是会带来新的问题,所以东西变复杂了都会有新的问题产生。。
1. 联表查询
也就是join了,之前在一个数据库里面可以用上join用一条sql语句就可以联表查询得到想要的结果,但是现在分为多个数据库了,所以join用不上了。就比如现在要查注册时间在2019年之后用户的订单信息,你就需要先去数据库A中用户表查询注册在2019年之后的信息,然后得到用户id,再拿这些id去数据库B订单表中查找订单信息,然后再拼接这些信息返回。所以等于得多写一些代码了。
2. 事务问题
搞数据库基本上都离不开事务,但是现在不同的数据库事务就不是以前那个简单的本地事务了,而是分布式事务了,而引入分布式事务也提高了系统的复杂性。
分表
我们已经做了分库了,但是现在情况是我们一个表里面的数据太多了,就一不小心你的公司的产品火了,像抖音这种,所有用户如果就存在一张表里吃不消,所以这时候得分表。分别又分垂直分表和水平分表。
1. 垂直分表
比如我们表有10列,现在一刀切下去,分成了两张表,其中一张表3列,另一张表7列。
这个一刀切下去让两个表分别有几列不是固定的,垂直分表适合表中存在不常用并且占用了大量空间的字段拆分出去。
就拿头条的用户信息,比如用户表只有用户id、昵称、手机号、个人简介这4个字段。但是手机号和个人简介这种信息就属于不太常用的,占用的空间也不小,个人简介有些人写了一坨。所以就把手机号和个人简介这两列拆分出去。
那垂直分表影响就是之前只要一个查询的,现在需要两次查询才能拿到分表之前的完整用户表信息。
2. 水平分表
比如现在用户表有5000万行数据,我们切5刀,分成5个表,每个表1000万行数据。
水平分表就适合用户表行数很多的情况下,一般单表行数超过5000万就得分表,如果单表的数据比较复杂那可能2000万甚至1000万就得分了,这个得看实际情况有些表很简单可能一亿行都不用分。所以当一个表行数超过千万级别的时候关注一下,如果没有性能问题就可以再等等看,不要急着分表,因为分表会是带来很多问题。
水平分表的问题比垂直分表就更烦了。
要考虑怎么切,讲的高级点就叫路由:
1. 按id(也就是范围路由)
比如id 值1-999万的放一张表,1000万-1999万放一张表,一次类推(也就是一段一段)。这个得试的,因为范围分的大了,可能性能还有问题,范围分的小了。。那表不得多死。
这种分法的好处就是容易切啊,简单粗暴,以后新增的数据分表都不会影响到之前的数据,之前的数据都不需要移动。
2. 哈希路由
就是取几列哈希一下看看数据哪个库,比如拿id来做哈希,1500取余8等于4,所以这条记录就放在user_4这个表中,2011取余8等于3,所以这条记录就放在user_3中。这种分法好处就是分的很均匀,基本上每个表的数据都差不多,但是以后新增数据又得分表了咋办,以前的数据都得动,比较烦!
3. 搞一张表来存储路由关系
还是拿用户表来说,就是弄一个路由表,里面存userId和表编号,表示这个userId是这张user表的的。这种方式也简单,之后又要分表了之后改改路由表,迁移一部分数据。但是这种方法导致每次查询都得查两次,并且如果路由表太大了,那路由表又成为瓶颈了!
三、总结
技术没有贵贱,不是用了分布式就牛逼,越复杂的系统维护的成本和难度越高,出现问题的几率越大。这种架构的演化往往都是被用户所驱动的,可以说是"不得已而为之"。
基本上单机数据库可以支撑10万用户量级别。所以一般情况下像数据库吃不消就升级硬件,优化数据库配置、优化代码、引入redis等。只有在真的不行了才上这些更复杂的东西。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号