Python3简明教程(十二)—— 模块
在这节我们将要学习 Python 模块相关知识。包括模块的概念和导入方法,包的概念和使用,第三方模块的介绍,命令行参数的使用等。
模块
到目前为止,我们在 Python 解释器中写的所有代码都在我们退出解释器的时候丢失了。但是当人们编写大型程序的时候他们会倾向于将代码分为多个不同的文件以便使用,调试以及拥有更好的可读性。在 Python 中我们使用模块来到达这些目的。模块是包括 Python 定义和声明的文件。文件名就是模块名加上 .py 后缀。
你可以由全局变量 __name__ 得到模块的模块名(一个字符串)。
现在我们来看看模块是怎样工作的。创建一个 bars.py 文件。文件内容如下:
""" Bars Module ============ 这是一个打印不同分割线的示例模块 """ def starbar(num): """打印 * 分割线 :arg num: 线长 """ print('*' * num) def hashbar(num): """打印 # 分割线 :arg num: 线长 """ print('#' * num) def simplebar(num): """打印 - 分割线
现在我们启动解释器然后导入我们的模块。
>>> import bars >>>
我们必须使用模块名来访问模块内的函数。
>>> bars.hashbar(10) ########## >>> bars.simplebar(10) ---------- >>> bars.starbar(10) **********
导入模块
有不同的方式导入模块。我们已经看到过一种了。你甚至可以从模块中导入指定的函数。这样做:
>>> from bars import simplebar, starbar >>> simplebar(20) --------------------
你也可以使用 from module import * 导入模块中的所有定义,然而这并不是推荐的做法。
包
含有 __init__.py 文件的目录可以用来作为一个包,目录里的所有 .py 文件都是这个包的子模块。
本节实验将创建下面的 mymodule 目录,目录结构如下:
shiyanlou:~/ $ tree mymodule[16:57:21]
mymodule
├── bars.py
├── __init__.py
└── utils.py
0 directories, 3 files
在这个例子中,mymodule 是一个包名并且 bars 和 utils是里面的两个子模块。
首先创建 mymodule 目录:
$ cd /home/shiyanlou
$ mkdir mymodule
然后将上一节编写的 bars.py 拷贝到 mymodule 目录下(可以用cp指令),然后可以使用 touch 创建一个 utils.py 文件。使用 touch 命令创建一个空的 __init__.py 文件。
如果 __init__.py 文件内有一个名为 __all__ 的列表,那么只有在列表内列出的名字将会被公开。
因此如果 mymodule 内的 __init__.py 文件含有以下内容:
from mymodule.bars import simplebar __all__ = [simplebar, ]
那么导入时将只有 simplebar 可用。如果你在 python3 解释器中进行测试,需要确定是在 mymodule 目录同级的目录下执行的 python3,类似下面的操作,否则会出现 ImportError: No module named 'mymodule' 的报错。
$ cd /home/shiyanlou $ python3 >>>
from mymodule import * 只能工作在模块级别的对象上,试图导入函数或类将导致 syntax error。
默认模块
现在你安装 Python 的时候会附带安装不同的模块,你可以按需使用它们,也可以为其它特殊用途安装新模块。在下面的几个例子中,我们将要看到同样例子很多。
 上面的例子展示了怎样获得你系统中安装的所有模块的列表。在这里就不粘贴它们了,因为这是一个很大的列表。
上面的例子展示了怎样获得你系统中安装的所有模块的列表。在这里就不粘贴它们了,因为这是一个很大的列表。
你也能在解释器里使用 help() 函数查找任何模块/类的文档。如果你想要知道字符串所有可用的方法,你可以像下面这样做:
>>> help(str)
os模块
os 模块提供了与操作系统相关的功能。你可以使用如下语句导入它:
>>> import os
getuid() 函数返回当前进程的有效用户 id。
>>> os.getuid()
5000
getpid() 函数返回当前进程的 id。getppid() 返回父进程的 id。
>>> os.getpid() 384 >>> os.getppid() 235
uname() 函数返回识别操作系统的不同信息,在 Linux 中它返回的详细信息可以从 uname -a 命令得到。uname() 返回的对象是一个元组,(sysname, nodename, release, version, machine)。
>>> os.uname() posix.uname_result(sysname='Linux', nodename='eca189f0062c', release=' 4.4.0-93-generic', version='#116~14.04.1-Ubuntu SMP Mon Aug 14 16:07:0 5 UTC 2017', machine='x86_64')
getcwd() 函数返回当前工作目录。chdir(path) 则是更改当前目录到 path。在例子中我们首先看到当前工作目录是 /home/shiyanlou,然后我们更改当前工作目录到 /Code并再一次查看当前工作目录。
>>> os.getcwd() '/home/shiyanlou' >>> os.chdir('Code') >>> os.getcwd() '/home/shiyanlou/Code'
所以现在让我们使用 os 模块提供的另一个函数来创建一个自己的函数,它将列出给定目录下的所有文件和目录。
def view_dir(path='.'): """ 这个函数打印给定目录中的所有文件和目录 :args path: 指定目录,默认为当前目录 """ names = os.listdir(path) names.sort() for name in names: print(name, end =' ') print()
使用例子中的 view_dir() 函数。
>>> view_dir('/')
.bashrc .dockerenv .profile bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
os 模块还有许多非常有用的函数,你可以在这里阅读相关内容。
Requests模块
Requests 是一个第三方 Python 模块,其官网的介绍如下:
Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用。
警告:非专业使用其他 HTTP 库会导致危险的副作用,包括:安全缺陷症、冗余代码症、重新发明轮子症、啃文档症、抑郁、头疼、甚至死亡。
第三方模块并不是默认的模块,意味着你需要安装它,我们使用 pip3 安装它。
首先要安装 pip3:
$ sudo apt-get update
$ sudo apt-get install python3-pip
然后用 pip3 安装 requests:
$ sudo pip3 install requests
上面的命令会在你的系统中安装 Python3 版本的 Requests 模块。
获得一个简单的网页
你可以使用 get() 方法获取任意一个网页。
>>> import requests >>> req = requests.get('https://github.com') >>> req.status_code 200
req 的 text 属性存有服务器返回的 HTML 网页,由于 HTML 文本太长就不在这里贴出来了。
使用这个知识,让我们写一个能够从指定的 URL 中下载文件的程序。
代码写入文件 /home/shiyanlou/download.py:
#!/usr/bin/env python3 import requests def download(url): ''' 从指定的 URL 中下载文件并存储到当前目录 url: 要下载页面内容的网址 ''' # 检查 URL 是否存在 try: req = requests.get(url) except requests.exceptions.MissingSchema: print('Invalid URL "{}"'.format(url)) return # 检查是否成功访问了该网站 if req.status_code == 403: print('You do not have the authority to access this page.') return filename = url.split('/')[-1] with open(filename, 'w') as fobj: fobj.write(req.content.decode('utf-8')) print("Download over.") if __name__ == '__main__': url = input('Enter a URL: ') download(url)
测试一下程序:
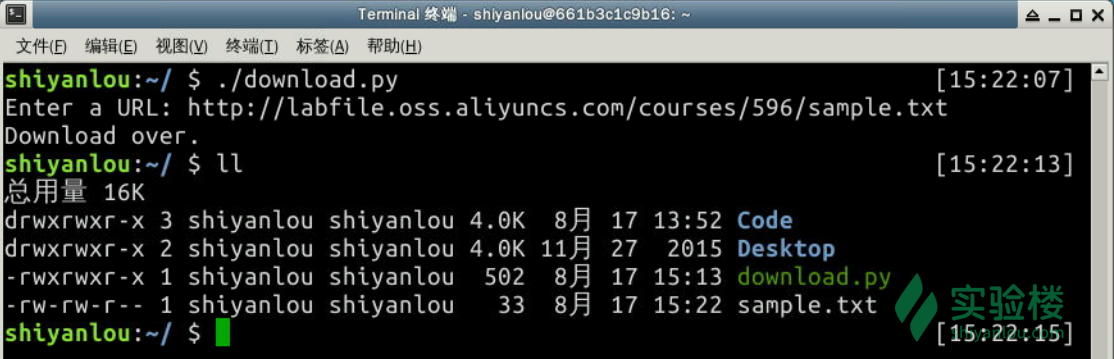
可以看到目录下已经多了一个 sample.txt 文件。
你可能已经注意到了 if __name__ == '__main__': 这条语句,它的作用是,只有在当前模块名为 __main__ 的时候(即作为脚本执行的时候)才会执行此 if 块内的语句。换句话说,当此文件以模块的形式导入到其它文件中时,if块内的语句并不会执行。
你可以将上面的程序修改的更友好些。举个例子,你可以检查当前目录是否已存在相同的文件名。os.path 模块可以帮助你完成这个。
argparse命令行参数处理模块
你还记得 ls 命令吗,你可以传递不同的选项作为命令行参数。
这里是用到的模块是 sys,命令行传入的所有参数都可以使用 sys.argv 获取。如果希望对参数进行处理可以使用 argparse 模块,阅读这篇 文档 学习。
tab补全
首先创建一个文件:~/.pythonrc ,文件内写入如下内容:
import rlcompleter, readline readline.parse_and_bind('tab: complete') history_file = os.path.expanduser('~/.python_history') readline.read_history_file(history_file) import atexit atexit.register(readline.write_history_file, history_file)
下一步在 ~/.bashrc 文件中设置 PYTHONSTARTUP 环境变量指向这个文件:
$ export PYTHONSTARTUP=~/.pythonrc
现在,从今以后每当你打开 bash shell,你将会有 TAB 补全和 Python 解释器中代码输入的历史记录。
要在当前 shell 中使用,source 这个 bashrc 文件。
$ source ~/.bashrc
总结
Python 吸引人的一点是其有众多的模块可以使用,对于自带模块,可以看看 Python3 的官方文档,对于第三方模块,可以在 PyPI 上找找。很多时候你都能找到合适的包帮你优雅的完成部分工作。比如 argparse 模块帮你非常容易的编写用户友好的命令行接口。
参考链接:https://www.shiyanlou.com/courses/596

 浙公网安备 33010602011771号
浙公网安备 33010602011771号