600行python实现WC程序
github https://github.com/Alexleslie/Software-Engineer/tree/master/wc
程序实现功能:基础功能和扩展功能
程序用法:
1. 参数说明 : -w 词数 ; -c 字符数 ; -l 行数; -a 行数细节
2. 用法说明:-w -a -c -l (参数数量不限定)+ 文件/目录/通配符
1. 举例 : -w -a -c *.c 获取当前目录下所有后缀为c的文件的次数,行数细节,字符数
-l C:\leslie\ 获取指定目录下的所有文件的函数
-w -a -c -l C:\*.c 获取c盘所有目录下所有c文件的次数,字符数,函数,行数细节
解题思路描述:
1. 首先需要读取文件,然后对文件内容做一定的处理
2. 先完成基础功能,并在此之上完成扩展功能
3. 优化代码的编写,测试代码的可行性和扩展性
设计实现过程:
1. 项目总共由5个函数,分别为:
1. 计算行数函数
2. 计算字符数函数
3. 计算词数函数
4. 计算代码行,注释行,空行函数
5. 获取文件列表函数
2. 五个函数都是独立功能函数,函数5作为初始化函数,在每一次程序运行时都会自动执行。
代码说明:
遍历函数
> 这个函数作为初始化函数,执行目录遍历,通配符识别功能,可以接受各种形式的输入,文件名,文件夹,通配符等,返回文件列表,无论一个或者多个。
1 def visitDir(path, keyword=None): # path 可为文件名或者是目录路径,关键字为通配符设计 2 file_list = [] 3 if (not os.path.isdir(path)) and ('*' not in path): # 如果只是单个文件的话,返回这个 4 return [path] # 以列表形式返回这个文件名。 用列表形式返回是因为方便后面迭代处理 5 if "*" in path: # 如果包含通配符 6 keyword = path[path.index("*") + 1:] # 获取要匹配的文本内容,放在关键字中 7 if path.index('*') != 0: # 如果通配符前有路径 比如 c:/leslie/*.c 8 os.curdir = path[:path.index("*")] # 那么当前路径置换为通配符前的路径 9 for root, dirs, files in os.walk(os.curdir): # 遍历目录 10 for f in files: 11 file = os.path.join(root, f) 12 if keyword[::-1] == file[::-1][:len(keyword)]: # 如果有该文件名包含关键字 13 file_list.append(file) 14 return file_list # 返回所有文件的列表
基础函数:
> 3个基础功能的实现
1 def lines(content): 2 return 'Lines: ' + str(len(content.readlines())) 3 4 def Char(content): 5 return 'Character: ' + str(len(content.read())) 6 7 def Word(content): 8 return "Word: " + str(len(re.findall(r"\b(\w.+?)\b", content.read()))) # 正则匹配
多行代码函数:
> 计算代码行,注释行,空行
1 def Muti_lines(content): 2 empty_line, comment_line, code_line, position = [0 for i in range(4)] # 设立标志位为0 3 file_line = content.readlines() # 总行数 4 muti_feature = ['\\*', '"""', "'''"] # 多行注释标识符 5 for i in range(len(file_line)): # 对于每一行 6 if position: # 如果当前处在多行注释中 7 comment_line += 1 8 if position in file_line[i]: # 如果在多行注释尾部 9 position = None # 清空标志位 10 elif any(c in file_line[i] for c in muti_feature): # 如果出现多行注释符 11 postion = [j for j in muti_feature if j in file_line[i]][0] # 获取多行注释符,并作为标志位,和上一个if条件呼应 12 comment_line += 1 13 elif len(file_line[i]) <= 1: # 空行判断 14 empty_line += 1 15 elif any(c in file_line[i] for c in ['\\\\', '#']): # 单行注释 16 comment_line += 1 17 code_line = len(file_line) - empty_line - comment_line 18 return "comment_line|empty_line|code_line %d|%d|%d" % (comment_line, empty_line, code_line)
主函数
> 采用字典的方法,对输入的参数具有很高的容错性和扩展性
if __name__ == '__main__': args = sys.argv # 获取命令行输入的参数 method_dict = {'-c': Char, '-l': lines, '-w': Word, '-a': Muti_lines} # 将每个功能函数放在一个字典里,参数与函数一一对应 current_method = [i for i in args if '-' in i] # 获取用户输入的参数 file_list = visitDir(args[-1]) # 需要处理的获取文件/目录,并且执行遍历函数,获取所有需要处理的文件。 for k in [i + ": " + method_dict[j](open(i, encoding='ISO-8859-15')) for i in file_list for j in current_method]: print(k) # 在用户输入的参数列表中,根据字典查询获取需要相对于的函数,并且对每一个文件都进行用户指定的函数处理。
测试图片
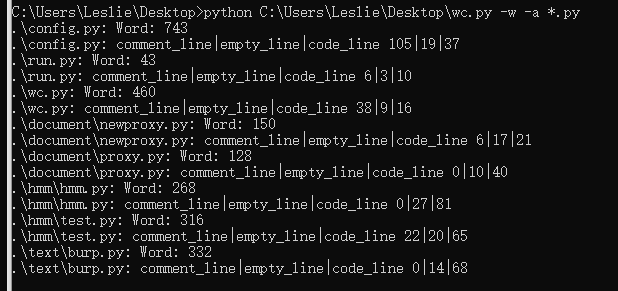
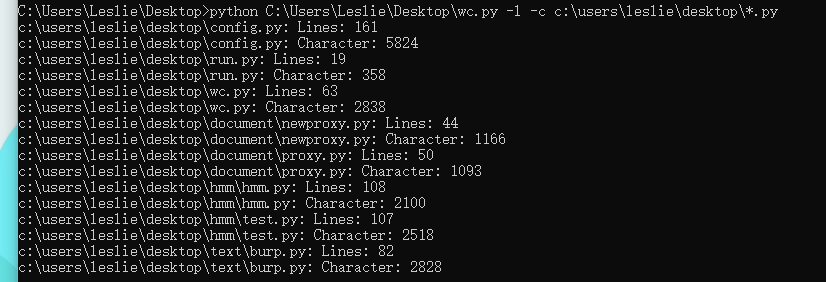
小结:
1. 找出问题的本质,虽然输入可能为目录,文件,通配符,但功能函数处理的单元还是文件,所以要做一步程序预处理工作--->将满足输入(目录,文件,通配符)的文件结合成文件列表,方便后续函数调用。
2. 多行注释的处理比较复杂,需要设立标志位解决冲突问题
3. 命令行参数输入复杂多样,比较难去硬性规范编程,采取字典查询的方式提高了适用性和扩展性
4. 将具体功能独立,方便随时引用
5. 简化代码,提高可读性

 浙公网安备 33010602011771号
浙公网安备 33010602011771号