React essence note - 10 -React 中的 栈调和 (Stack Reconciler) 过程是怎样的
概念
调和: 协调, 协调过程的官方定义:VirtualDOM是一种编程概念, 在这个概念中, UI以一种理想化的, 或者说虚拟的表现形式保存在内存中, 并通过ReactDOM等类库使之与真实的DOM同步. 这个过程叫做协调(调和)- 调和是将
虚拟DOM映射到真实DOM的过程, 严格来说并不能和Diff画等号 调和是使一致的过程Diff是找不同的过程,Diff只是调和的一个环节- 根据
Diff的实现形式不同, 调和过程被划分为React 15: 栈调和以及React 16: Fiber 调和
Diff 策略的设计思想
- Diff 算法其实就是
找不同的过程 - 计算机科学领域, 要想找出两个树结构之间的不同, 传统的计算方法是通过循环递归进行树节点的一一对比, 这个过程的算法复杂度是
O (n^3),具体来说, 若一张页面中有 100 个节点(这样的情况在实际开发中并不少见) , 100^3 算下来就有十万次操作了, 这还只是一次 Diff 的开销;若应用规模更大一点, 维护 1000 个节点, 那么操作次数将会直接攀升到 10 亿的量级 - 经常做算法题的人都知道, OJ 中相对理想的时间复杂度一般是 O(1) 或 O(n). 当复杂度攀升至 O(n^2) 时, 我们就会本能地寻求性能优化的手段, 更不必说是人神共愤的 O(n^3) 了!React 团队结合设计层面的一些推导, 总结了以下两个规律, 为将 O (n^3) 复杂度转换成 O (n) 复杂度确立了大前提
# 若两个组件属于同一个类型,他们拥有相同的DOM树形结构
# 处于同一层级的一组子节点,可以通过设置key作为唯一标识, 从而维持各个节点在不同渲染过程的稳定性
# 除此之外, DOM节点之间的跨层级操作并不多, 同层级操作是主流
图解Diff操作
-
- Diff算法性能突破的关键点在于
分层对比
- Diff算法性能突破的关键点在于
-
- 类型一致的节点才有继续Diff的必要性
-
- key属性的设置,可以帮助我们尽可能重用同一层级内的节点
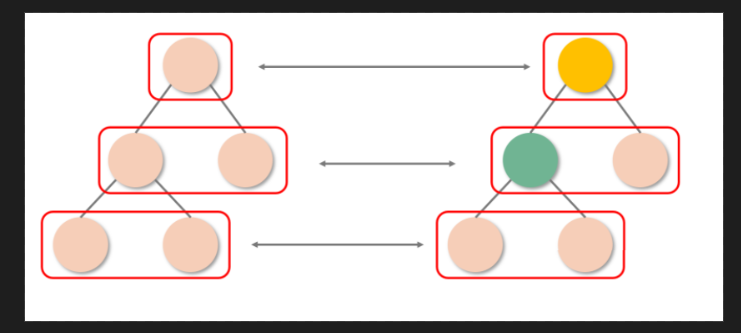
Diff思路(1): 改变事件复杂度量级的决定性思路: 分层对比
- 结合
DOM 节点之间的跨层级操作并不多, 同层级操作是主流这一规律, React 的 Diff 过程直接放弃了跨层级的节点比较, 它只针对相同层级的节点作对比, 如下图所示. 这样一来, 只需要从上到下的一次遍历, 就可以完成对整棵树的对比, 这是降低复杂度量级方面的一个最重要的设计 - 虽然栈调和将传统的树对比算法优化为了分层对比, 但整个算法仍然是以递归的形式运转的,
分层递归也是递归
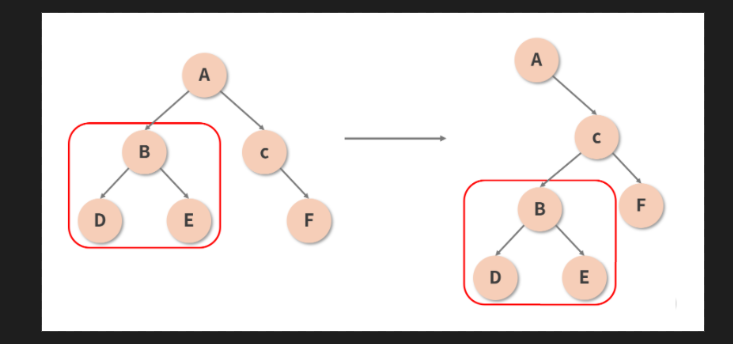
- 那么如果真的发生了跨层级的节点操作(比如将以 B 节点为根节点的子树从 A 节点下面移动到 C 节点下面, 如下图所示) 会怎样呢? 很遗憾, 作为
次要矛盾, 在这种情况下 React 并不能够判断出移动这个行为, 它只能机械地认为移出子树那一层的组件消失了, 对应子树需要被销毁;而移入子树的那一层新增了一个组件, 需要重新为其创建一棵子树.
- 销毁 + 重建的代价是昂贵的, 因此 React 官方也建议开发者不要做跨层级的操作, 尽量保持 DOM 结构的稳定性
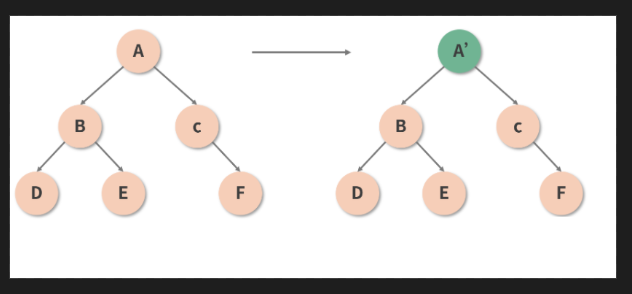
Diff思路(2): 减少递归的 '一刀切' 策略: 类型的一致性决定递归的必要性
- 本着抓
主要矛盾的基本原则, React 认为,只有同类型的组件, 才有进一步对比的必要性, 若参与diff的两个组件类型不同, 那么直接放弃比较, 原地替换旧的节点.如下图所示: 只有确认组件类型相同后, React 才会在保留组件对应 DOM 树(或子树)的基础上, 尝试向更深层次去 Diff, 这样一来, 就能很大程度上减少 diff过程中冗余的递归操作
Diff思路(3): 重用节点的好帮手: key 属性帮 React 记住 节点
key属性帮助维持节点的稳定性, React中对于 key 属性的定义
key 是用来帮助React识别哪些内容被修改,添加 或者删除. key 需要写在用数组渲染出来的元素内部, 并且需要赋予一个稳定的值, 稳定在这里很重要, 如果key发生了变更, React则会触发UI的重渲染
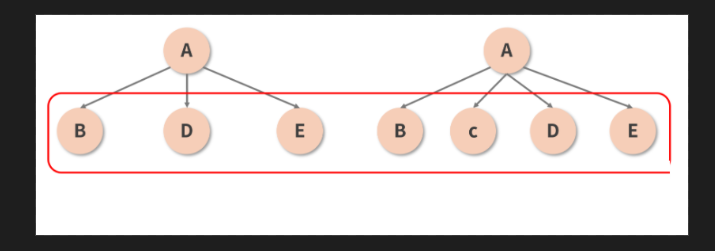
key试图解决的是同一层级下节点的重用问题.如下图所示
// =========> ❌❌❌❌ Key 的应用
// A 组件在保持类型和其他属性均不变的情况下, 在两个子节点(B 和 D)之间插入了一个新的节点(C). 按照已知的 Diff 原则, 两棵树之间的 Diff 过程应该是这样的:
// step 1: 首先对比位于第 1 层的节点, 发现两棵树的节点类型是一致的(都是 A), 于是进一步 Diff
// step 2: 开始对比位于第 2 层的节点, 第 1 个接受比较的是 B 这个位置, 对比下来发现两棵树这个位置上的节点都是 B, 没毛病, 放过它
// step 3: 第 2 个接受比较的是 D 这个位置, 对比 D 和 C, 发现前后的类型不一致, 直接删掉 D 重建 C
// step 4: 第 3 个接受比较的是 E 这个位置, 对比 E 和 D, 发现前后的类型不一致, 直接删掉 E 重建 D
// step 5: 最后接受[比较]的是树 2 的 E 节点这个位置, 这个位置在树 1 里是空的, 也就是说树 2 的E 是一个新增节点, 所以新增一个 E.
// =========> ✅✅✅✅ Key 的应用
const todoItems = todos.map(todo => (
<div id={todo.id}>
{todo.text}
</div>
))
- 如果你忘记写 key, React 虽然不至于因此报错, 但控制台标红是难免的, 它会给你抛出一个[请给列表元素补齐 key 属性]的 warning, 这个常见的 warning 也从侧面反映出了 key 的重要性. 事实上, 当我们没有设定 key 值的时候, Diff 的过程就正如上文所描述的一样惨烈. 但只要你按照规范加装一个合适的 key, 这个 key 就会像一个记号一样, 帮助 React [记住]某一个节点, 从而在后续的更新中实现对这个节点的追踪. 比如说刚刚那棵虚拟 DOM 树, 若我们给位于第 2 层的每一个子节点一个 key 值, 如下图所示:
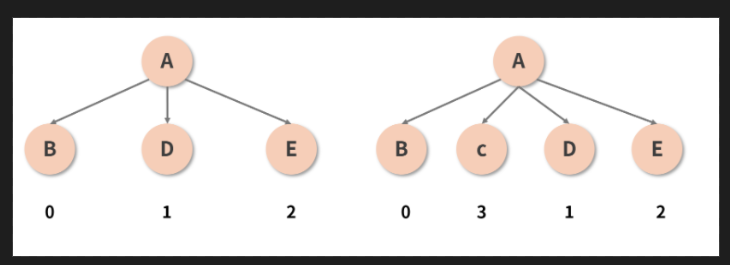
// 这个 key 就充当了每个节点的 ID(唯一标识), 有了这个标识之后,
// 当 C 被插入到 B 和 D 之间时, React 并不会再认为 C、D、E 这三个坑位都需要被重建—
// 它会通过识别 ID, 意识到 D 和 E 并没有发生变化(D 的 ID 仍然是 1, E 的 ID 仍然是 2), 而只是被调整了顺序而已.
// 接着, React 便能够轻松地重用它[追踪]到旧的节点, 将 D 和 E 转移到新的位置, 并完成对 C 的插入.
// 这样一来, 同层级下元素的操作成本便大大降低
总结1
- 栈调和机制下 Diff 算法的核心逻辑:
树递归 - 虚拟 DOM 中还有一个叫作[batch]的东西. [batch]描述的是[批处理]机制,这个机制和 Diff 一样,在 React 中都可以由 setState 来触发
总结2
- diff算法的核心在于
树递归, - diff算法性能突破的关键点在于
分层对比 类型一致的节点才有继续Diff的必要性- key属性的设置,可以帮助我们尽可能
重用同一层级内的节点 - O($n^3$) 优化成 O(n)
为什么传统的树对比是 O(n^3)?
Prev Last
A A
/ \ / \
B D D B
/ \
C C
# 就上面两树的变化而言,若要达到最小更新,首先要对比每个节点是否相同
# PA -> LA
# PA -> LB
# PA -> LC
# PA -> LD
# PB -> LA
# ...
# PD -> LD
# ===> O(n ^ 2)
# 找到差异后还要计算最小转换方式,最终结果为O(n^3)
Keep learning

 浙公网安备 33010602011771号
浙公网安备 33010602011771号