吴恩达深度学习课程脉络(四)卷积神经网络
第一周
1.1 计算机视觉 C
深度学习令wu兴奋有2点,计算机视觉的发展出现很多新产品应用,及在CV发展过程中产生的新网络结构跟算法,能与其他交叉领域结合应用;他在做speech recognition的时候会从这里找灵感;
介绍了基本任务,图像分类,目标识别,在处理1000*1000*3 像素等大图时,参数太大,引出要用卷积网络
1.2-1.3 边缘检测示例
直接用倆案例edge detection 介绍卷积算法;
训练CNN在一定意义上是在训练每个卷积层的过滤器,让其组合对特定的模式有高的激活,以达到CNN网络的分类/检测等目的
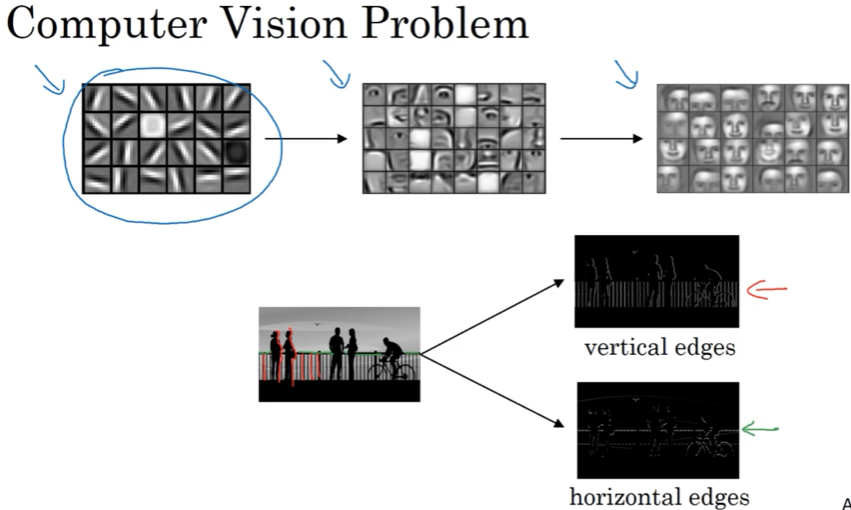
1.4 Padding
构建深度网络需要padding,直接介绍; 重点说valid,same convolution;
1.5 Stride
卷积网络另一个重要操作,直接上案例
1.6 Convolutionals over volumes
在 3 dimensional volumnes上卷积计算,以常规RGB图片来介绍;
如果只对一种颜色的模式感兴趣,可以对其他层的参数设为0;
1.7 单层卷积网络
介绍单层卷积网络,参数个数,notation命名规则
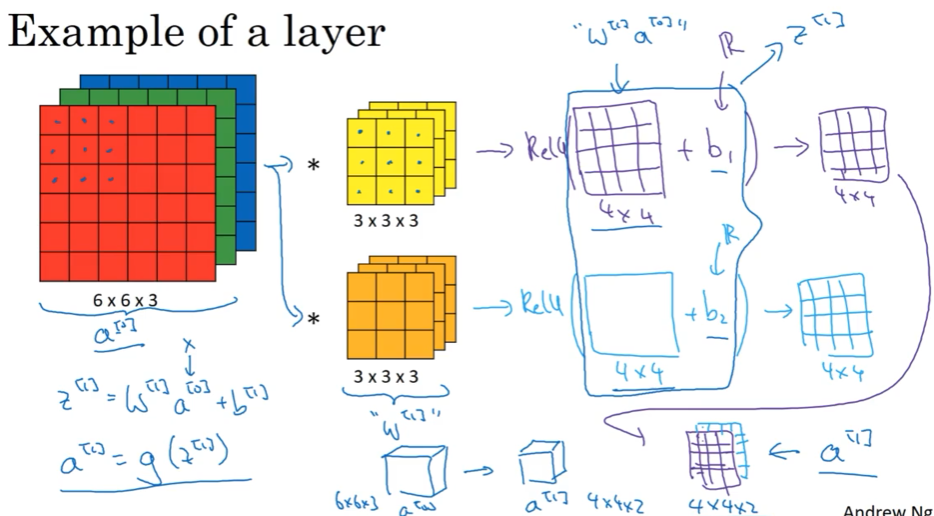

关于A[L],并不是所有的数据格式都一样,注意它的shape,有些把channels数放前面,而把样本数m放后面
1.8 简单卷积网络示例
多层,简单卷积网络介绍
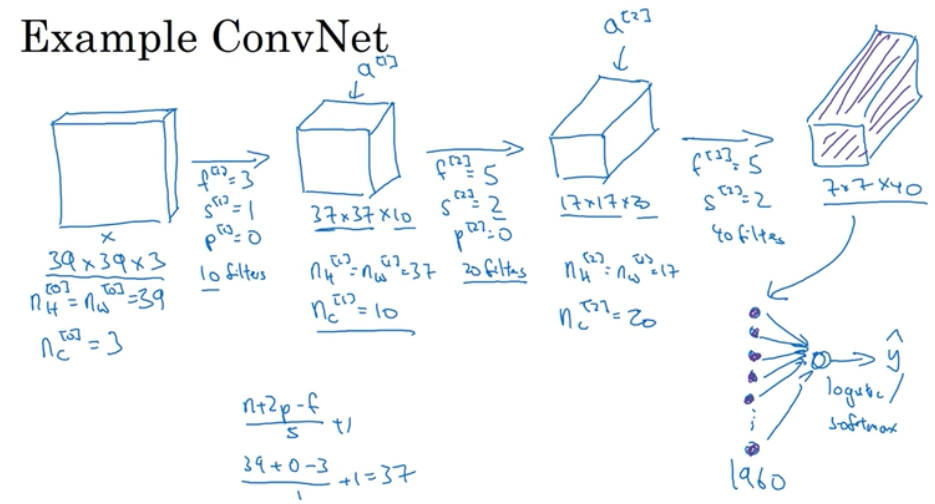
最后一步,把全部的参数展开成一维的; 边长减少,通道数增加,这是一个趋势
1.9 池化层
典型的网络还包括池化层,直接介绍;
注意:
1)maxpooling跟avg都是在每个N_C通道上单独进行计算的;因此不改变N_C通道数
2)filter size跟stride对pooling后data shape的影响跟卷积层一样
1.10 卷积神经网络示例
以受LeNet-5启发的下图网络介绍,分析各层参数
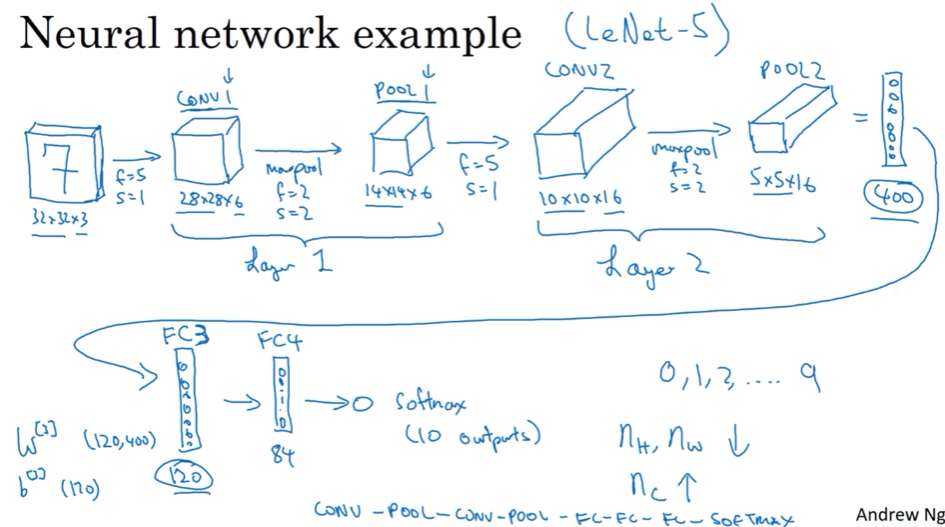
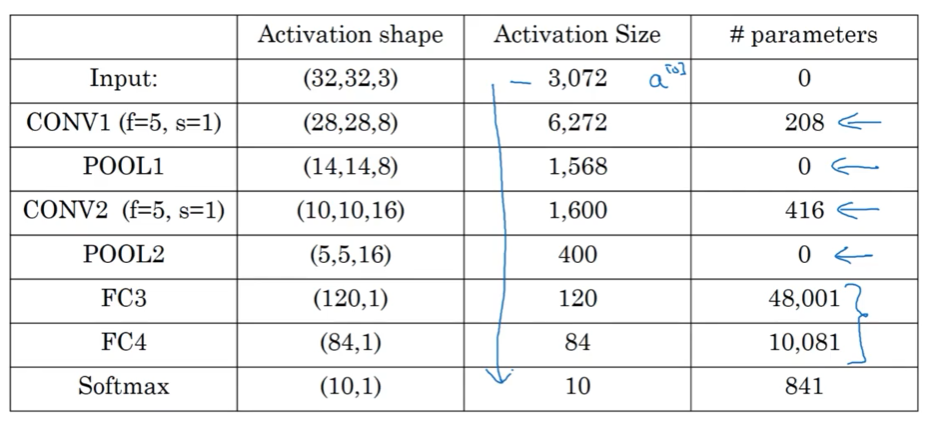
需要指出的是,
1)pooling layers没有参数,而conv layers的参数教少,大部分的参数集中在Full connection layers;
2)activation size倾向于逐渐下降,下降的太快对性能不好;
1.11 为啥使用卷积?
参数共享parameter sharing,一个通道,全部共用
稀疏链接 sparsity of connections. 一个卷积值,只于卷积通道,以及前一层的卷积核范围大小的值有关
算了一下全连接参数多,put it together做了个猫分类的网络
第二周
2.1 case studies
过去几年CV研究大量集中在如何利用基本构件组合形成有效CNN,最好的方法是看别人的;在CV中表现好的,在其他任务中往往表现也好;
2.2 经典网络
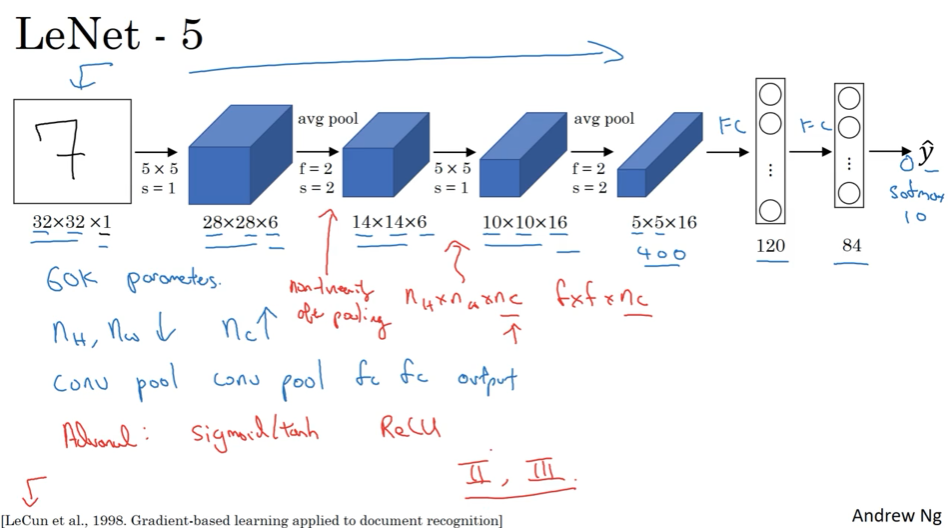
LeNet-5 ( 约6w参数)
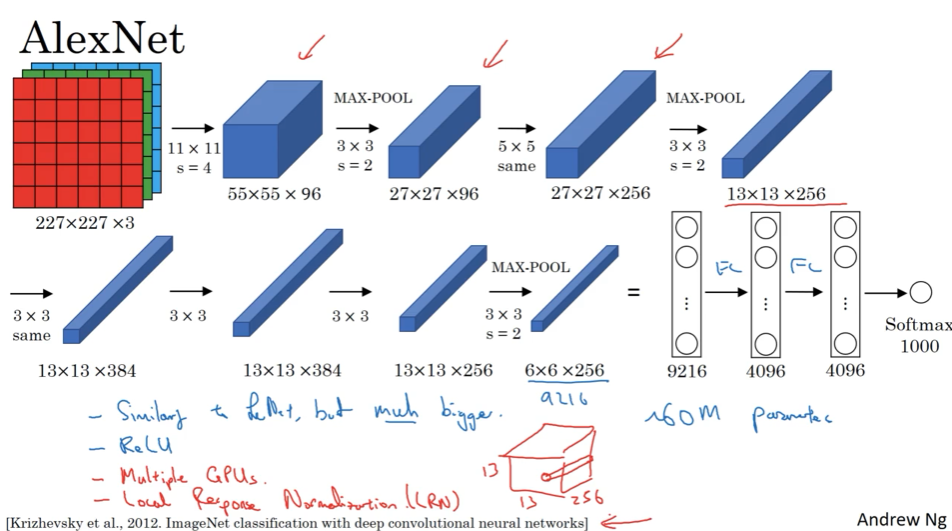
AlexNet ( 约6千万参数)
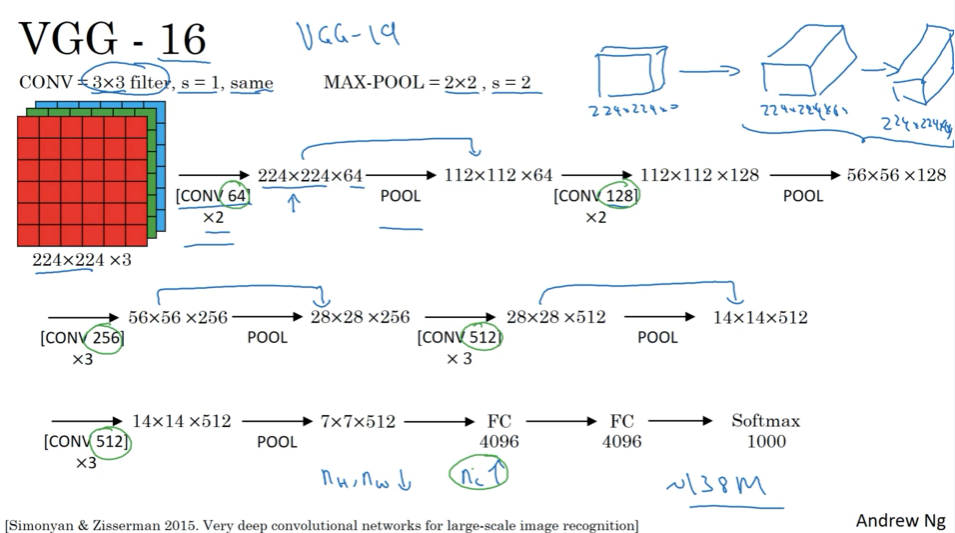
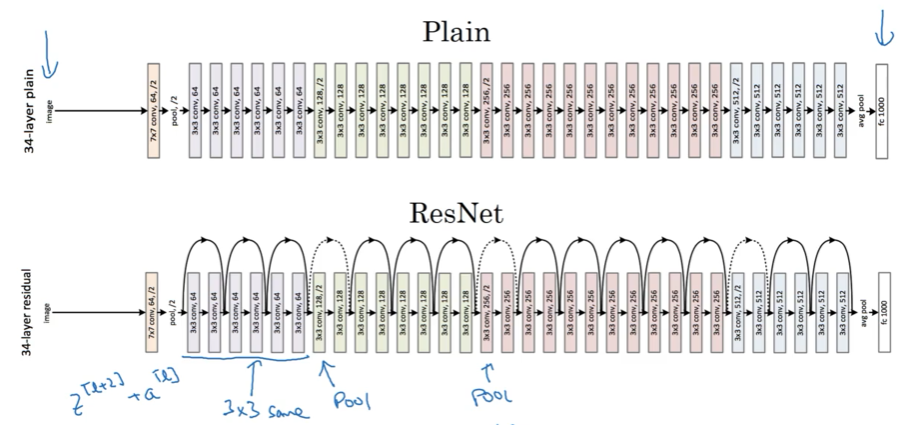
VGG(约1.38亿个参数)
结构一致,每层参数下降系统,有吸引力,缺点是网络太大,训练参数多
2.3 ResNet 残差网络
因梯度爆炸 exploding 跟梯度消失 vanishing ,很深的网络没法训练,ResNet的skip connections 可从前面的activation直接feed给更深的网络层,能训练over 100 层的网络
单个Residual block
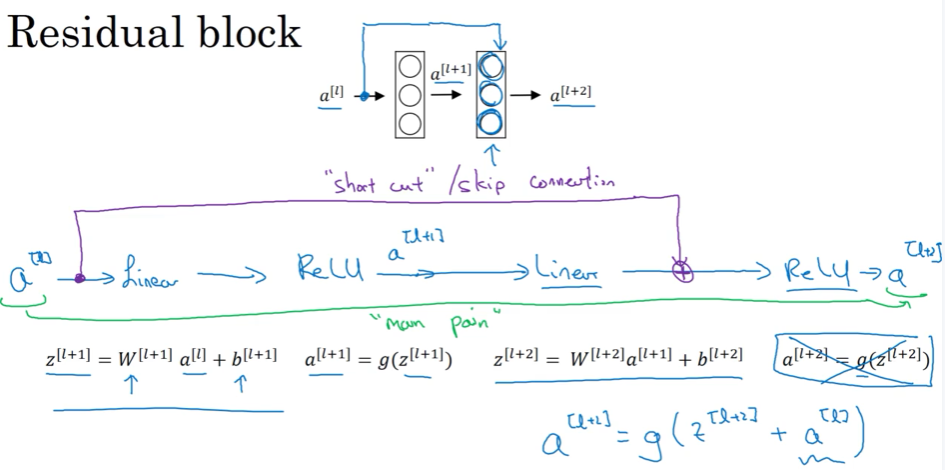
ResNet 在网络层数增加时,也可训练
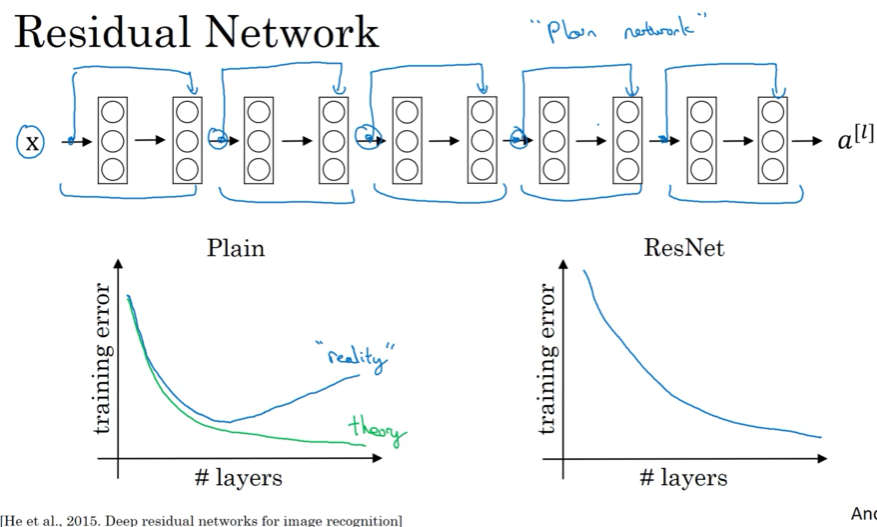
2.4 为啥ResNet有用 ?
利用L2正则化或权重衰减时,会压缩activation 值的权重,
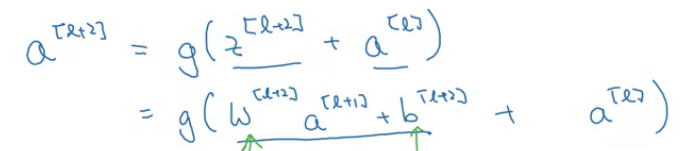
如权重为0了,则只剩下skip connection部分的activation值起作用,其实也就是一个identity function(ReLu用2遍效果一样),学习起来也简单;也就是说增加了2层并没有hurt NN 的performance;
但是如果权重不为0了,则隐藏层单元可以多学信息;
技术点: 因为要跳,所有大部分维度都相同,如果skip之后维度不同,用一个前置矩阵乘一下调整
2.5 1*1卷积
网络中的网络也叫1-1卷积,挺有影响力的。
可认为对6*6个位置用了full connection
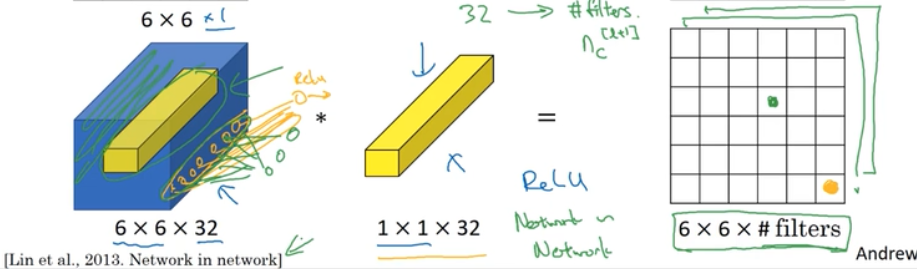
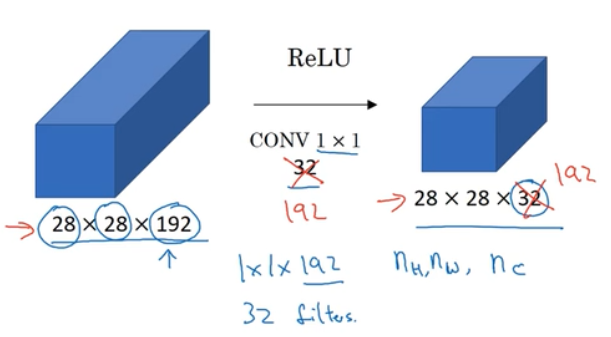
可以用来进行维度压缩
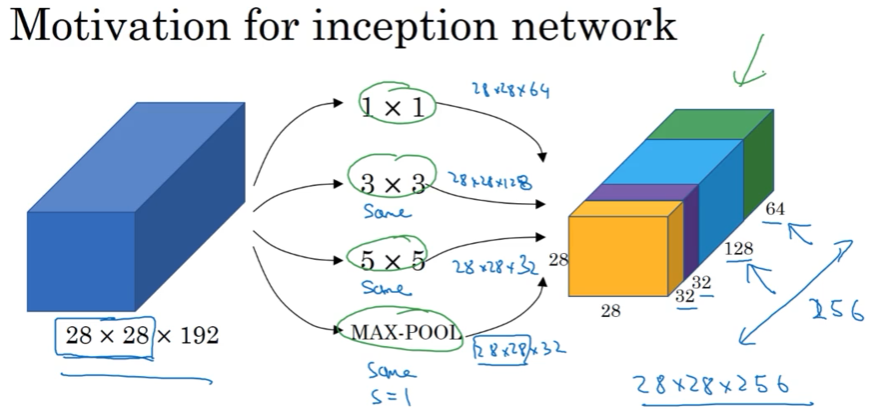
2.6 Incepton 网络简介
对1*1,3*3,5*5,要不要池化,怎么选,Inception帮你选择,网络复杂一些了,但是效果非常不错
想法:
问题:计算太复杂了
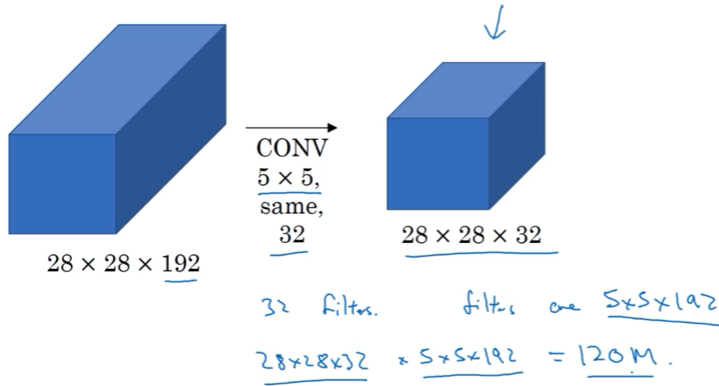
用1*1解决
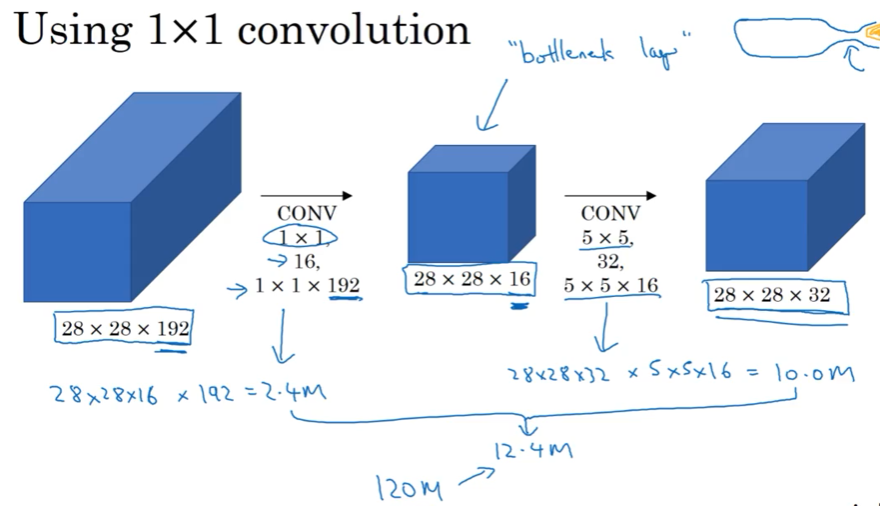
这种压缩会损害网络的表现吗? 只要bottleneck那里设计得合理,不一定
2.7 Incepton 网络
先用1*1卷积进行压缩,再卷积,不同filters卷积后,放一块,进行channels concatenate
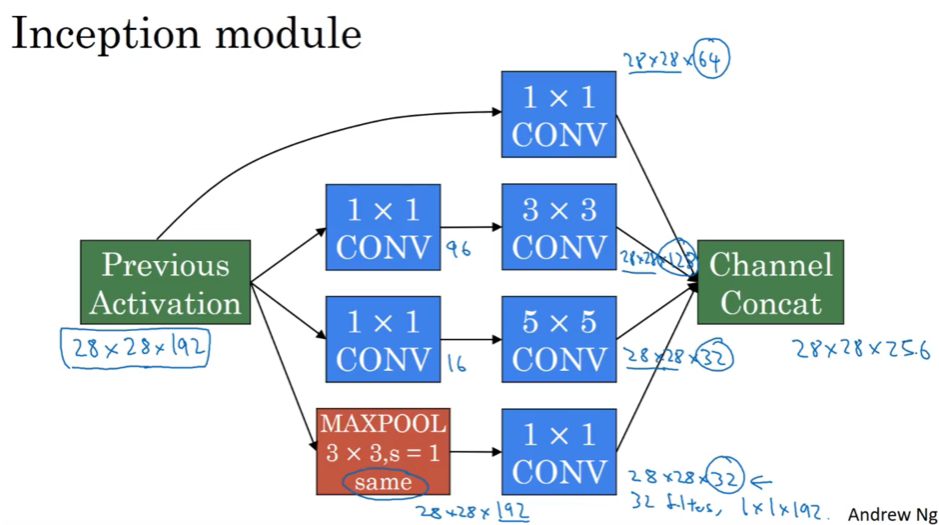
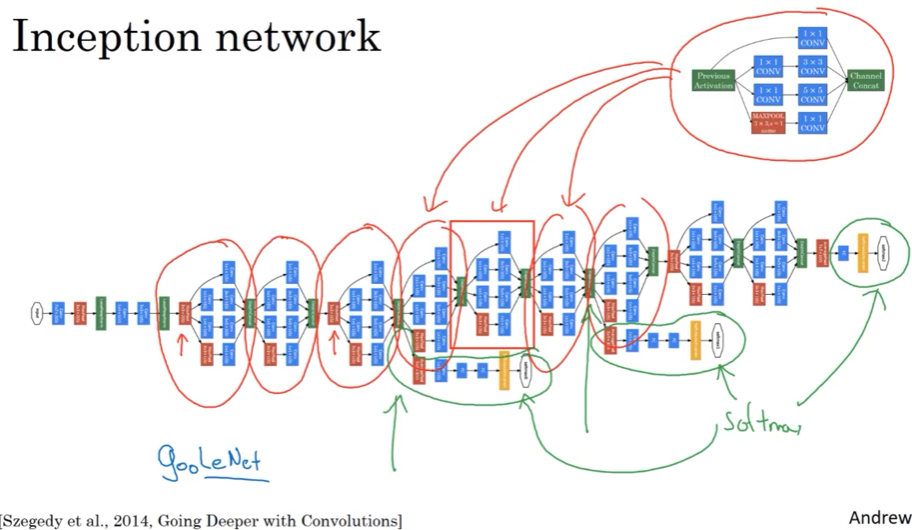
Inception NN最后有FC层,也有从隐藏层分支出去做一个softmax来预测,算是一种正则化;
Inception也叫GoogLeNet有很多发展了Inception v1,v2,v3。。( 其实Yolo也是有很大v1,v2,v3等很多版本了),甚至有人加入了skip connection,有时候也表现不错;
2.8 用open-source去实现
深度学习很多时候不能通过阅读人家的论文复现,但开源代码可以帮助我们
2.9 迁移学习
很多数据集,也有很多模型已经训练好,迁移过来在自己的模型上;
数据少,冻结前面的,直接改最后的softmax训练,多点的数据,考虑往前训练几层,很多的话,直接拿人家的权重作为初始化权重
2.10 数据扩充
mirroring,random cropping,rotation,shearing(倾斜),local warping,color shifting (高级点的: PCA)
2.11 讲CV几点
数据多,人工特征干预可少,用更简单的算法; 数据少,则要多手工特征,;
基线模型表现好,一是集成,二是多种方式测,multi-crop at test time
用发表的模型;用开源实现;用预训练好的模型,在自己数据上微调
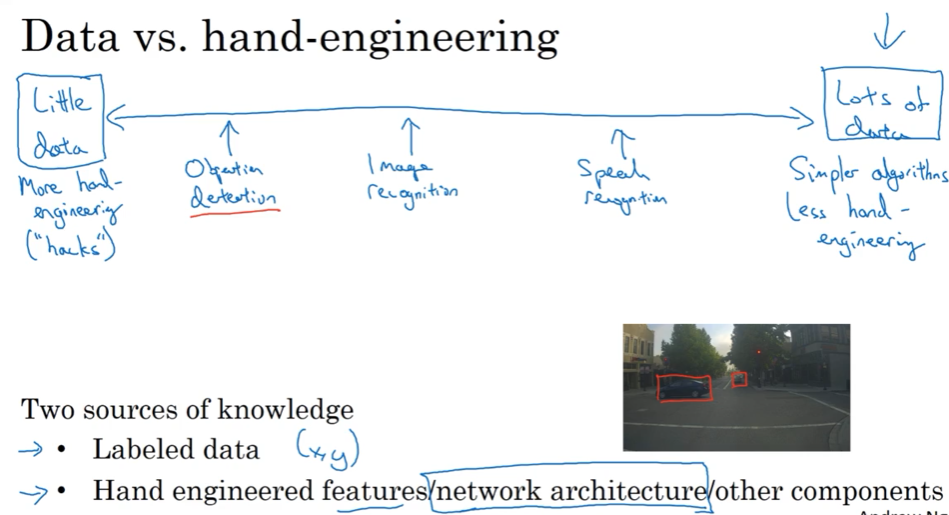
CV似乎有很多数据了,但实际上经常会令人感觉到数据不够,因此CV需要依赖 hand-engineering,跟设计这么复杂的网络结构;
特征工程是一项skillful的工作
第三周 目标检测
3.1 目标定位 object localization
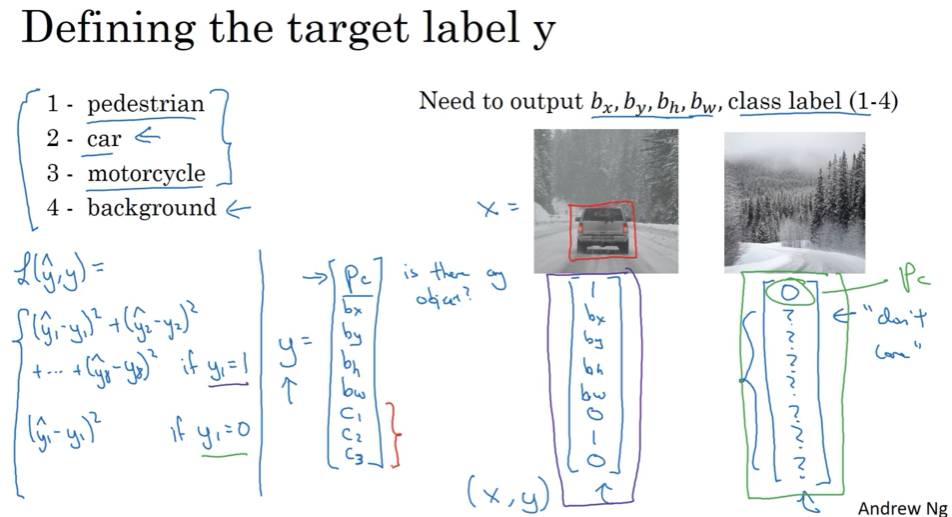
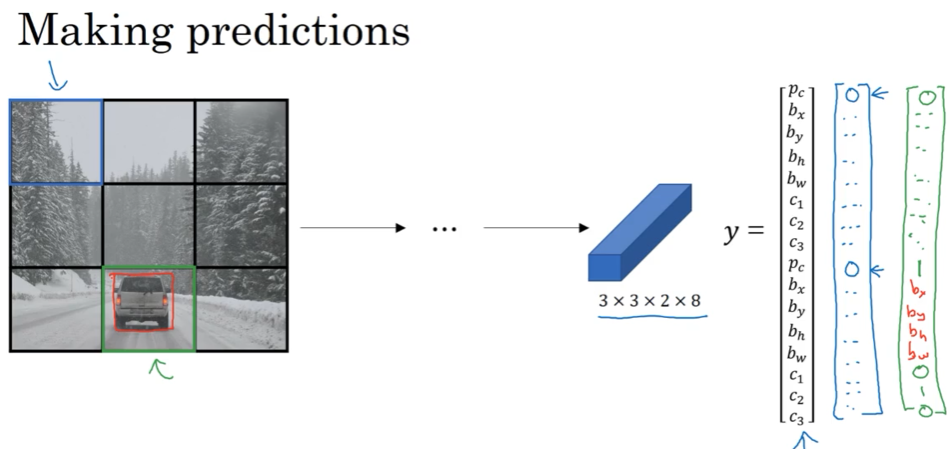
给你个图片进行分类,同时要把目标框出来,这个框框其实也就是detect。 直接建模输出定义box的4个变量
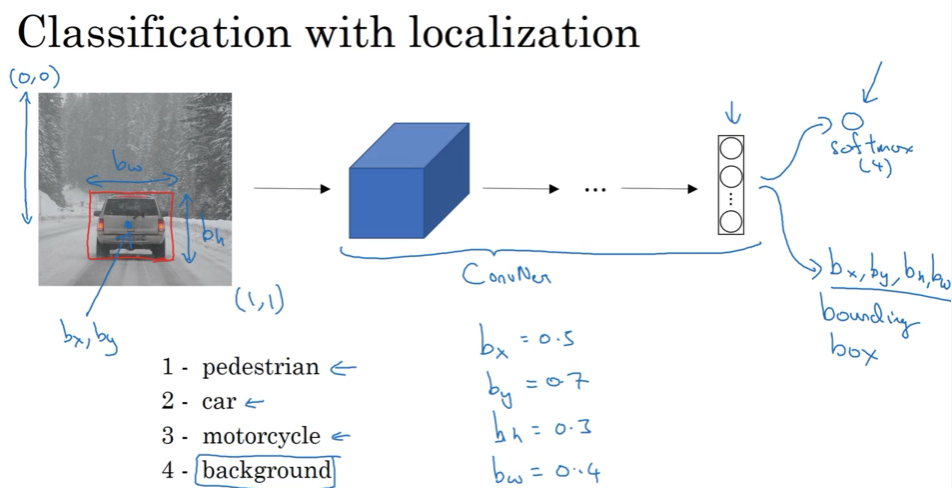
根据P是否为0来定义损失函数,通常对bx-bw坐标用平方损失,p用逻辑回归的交叉熵损失
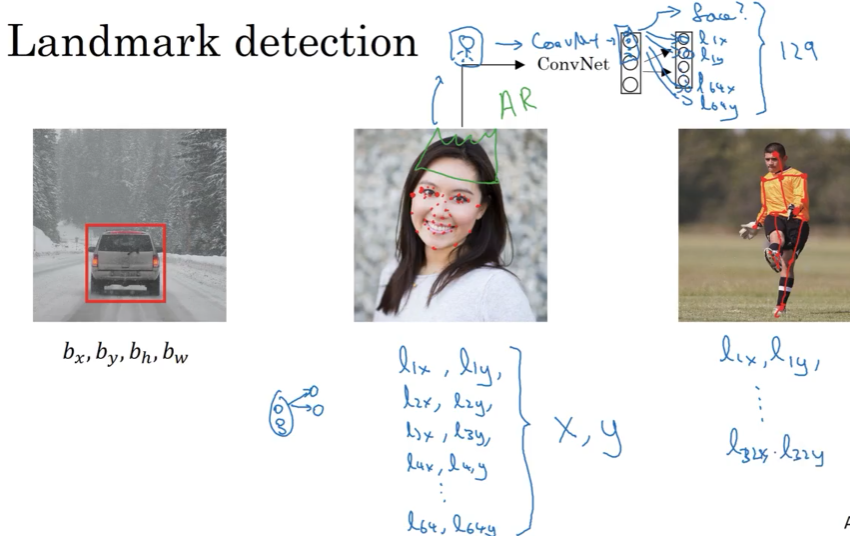
3.2 landmark detection 特征点检测
只输出x,y的坐标,则变成特征点检测。 训练后,可应用AR带绿帽,姿态估计
3.3 目标检测
滑动窗口检测sliding windows detection,小框框大框框滑动,一个一个检测,但计算成本太高,不好
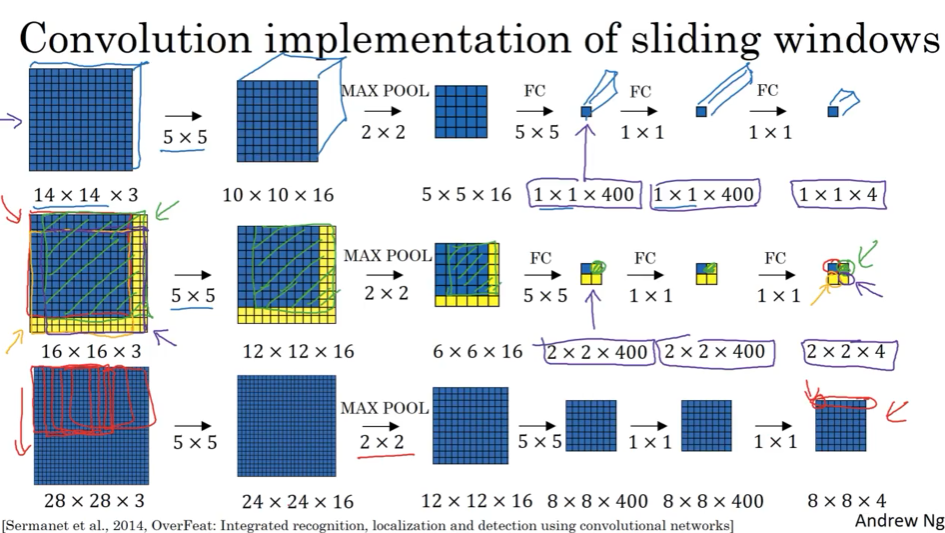
3.4 滑动窗口卷积实现 Convolutional implementation of sliding window
FC层,其实可以看成是卷积核为1的卷积;
5*5*16 跟400的全连接,等价于5*5*16 跟5*5*16=400 的卷积核,连接400次(filter)
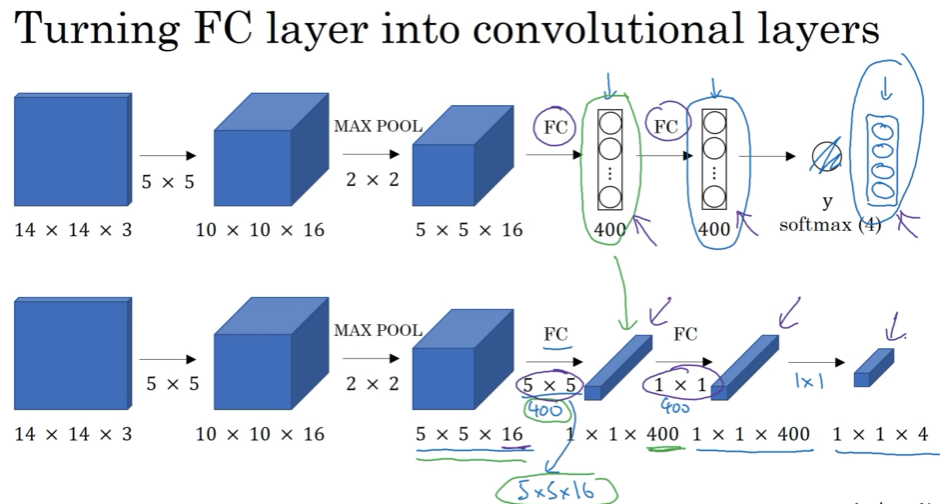
一次性把所有的滑动窗口全检测出来
3.5 Bounding Box预测
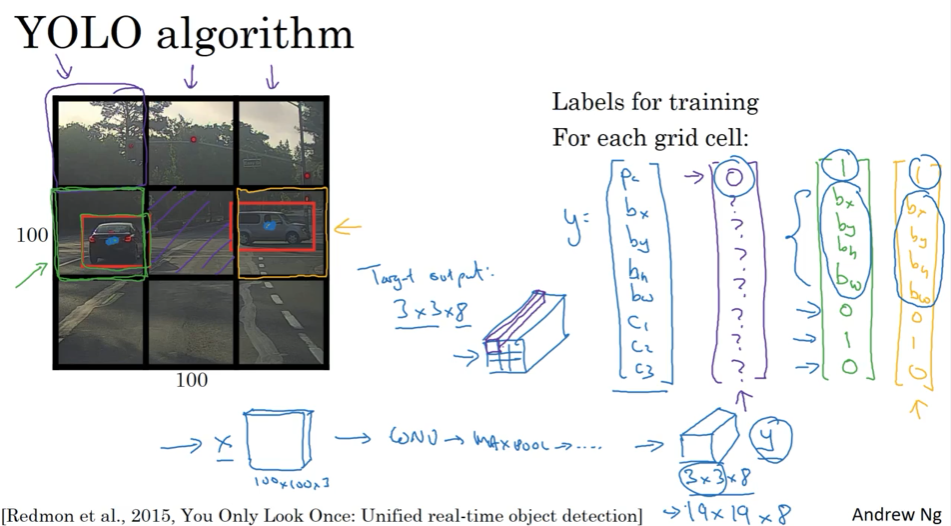
上面的框框还不精确,需要调整,YOLO 算法是其中一个,意思是“you only like once”
分割成网格grid cell,对每个cell贴标签,进行训练,每个cell单独训练
注意:
(1)跨框的只分配给object中心点所在的框
(2)卷积实现一次性跑,并没一个一个框跑 (用stride控制的?),效率高,可以实现real time
(3)优点在于可以精确输出边界框,test时,输入图片,分grid cell给出结果
(4)指定box时,左上(0,0),右下(1,1),bh,bw可以大于1
如果格子里只有一个预测的object则没问题,一个多框,下面说。实际中,分割较多,如19*19,一个基本上只有一个object。
YOLO论文挺难读,他也读不懂,问了很多资深研究员,甚至有时需要联系作者,看源代码,所以大家看不懂时不要捉急;
3.6 交并比 Intersection over Union
IoU , I own you

3.7 非极大值抑制 Non-max suppresion example
看最大的p框,然后检查所有跟这个最大概率边界框有高IOU的框,去掉,再找最大,再去掉; 如果有3个目标类型,则单独分别进行抑制

3.8 Anchor boxes 专门处理一框2物
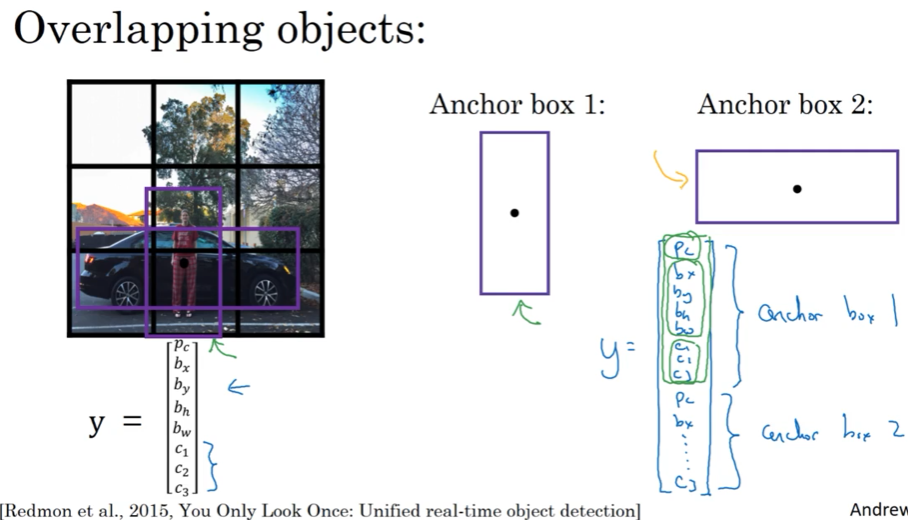
设立Anchor box的好处是让你的学习算法更有针对性,比如针对高高廋廋,或者扁扁长长的形状,有些unit会专门处理这种形状;
一般人工选择5-10个anchor box shape,覆盖不同形状;高级点,Yolo论文中介绍了用k均值聚类,将2类形状聚类选择最有代表性的一组anchor box,自动学习anchor box
无法处理一框3物,以及2个物体的形状一样的情况;
3.9 Yolo算法
训练
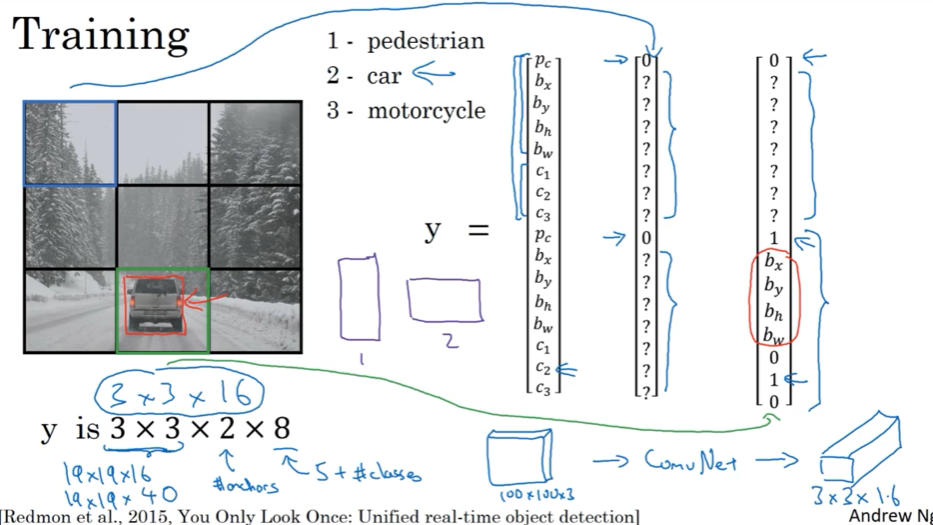

每周物体单独处理一次non-max suppression
3.10 候选区域 Region proposal (R-CNN)
挺有影响力的,但是wu用得少,optional. 只选择有意义的区域出来,运行卷积分类;
选择的方法是图像分割算法;
R-CNN对区域逐一分类,比较慢,还有个Fast R-CNN,在区域内运用了滑动窗口的卷积实现; 还有个Faster R-CNN,不是用传统的分割算法,而用CNN进行分割分割; 但还是比YOLO慢。。

第四周
Face Recognition 人脸识别
4.1 FR简介

4.2 One-shot学习
数据库中只有一张照片,训练集太少了;如果有个新人加入,sotfmax的节点,会增加一个,有需要训练?
解决方法: 学习一个similarity函数

新人来了,直接增加一个比较变量即可;
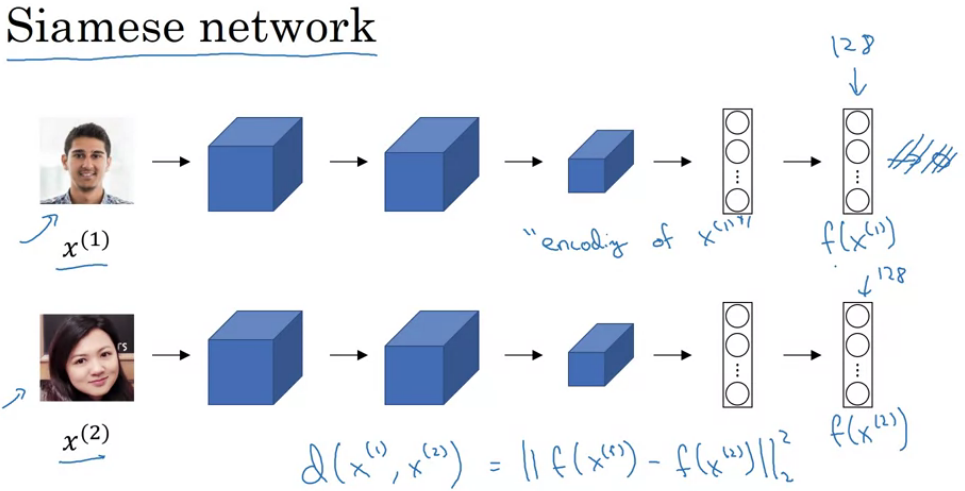
4.3 Siamese网络
对2个图片进行encodeing,在识别卷积网络(Identical convolutional NN)上,对不同input进行运算,然后比较他们,又叫Siamese neural network architect;
4.4 Triple损失
如何学习这个function? 通过Triple loss;因为同时查看三张照片(Anchor, positive, negative - APN),进行训练
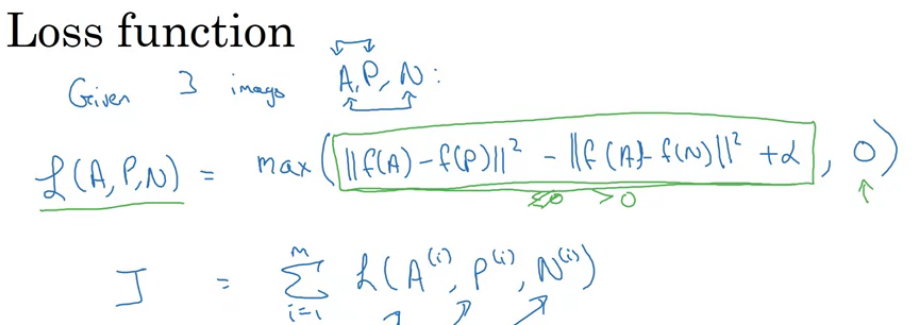
训练的时候,d(A,P) + alpha < d(A,N) 多挑难分辨的APN samples,这样才能更好的使梯度下降; 商业上的训练照片多,几千万,上亿的都有,数据也难获得,好消息是很多大商业公司已经训练好,发布在网上了;
命名规则: __Net , Deep__, 这里face recognition,所以叫: FaceNet;
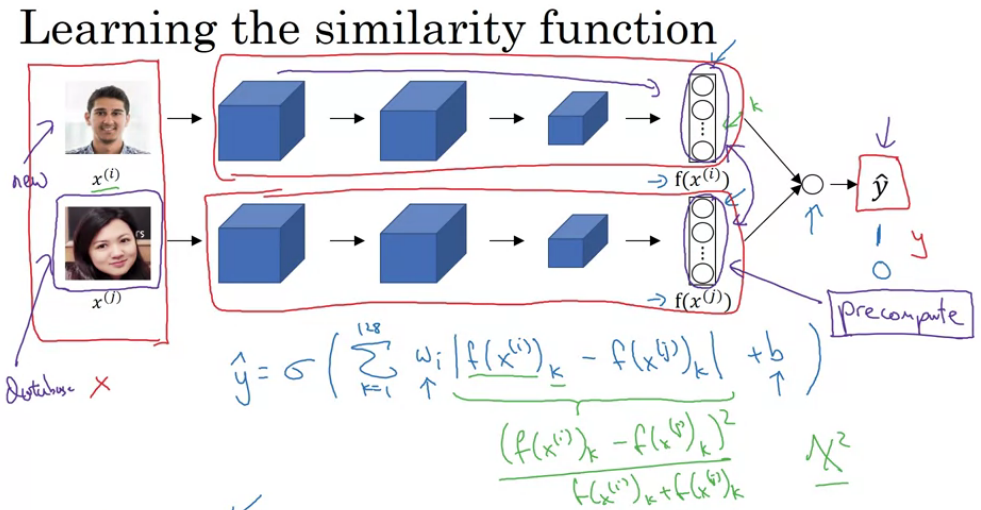
4.5 面部验证及二分类
face verification 可以直接作为二分类问题进行学习;基于Siamese 网络架构的二分类问题,用不同的照片对,去训练NN,训练Siamese网络参数
Neural Style Tranfer
4.6 神经网络风格转换
贴给图片,展示

4.7 深度卷积网络学习了什么?
举例说明 layer 1 学习了相对简单的特征,例如边缘,特别颜色的阴影;深层的units看得更宽的区域,得到更宏观的特征
[Zeiler and Fergus.,2013, Visualizing and understanding convolutional networks]

4.8 损失函数

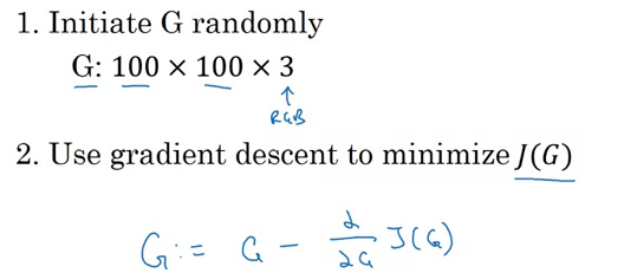
4.9 内容损失函数
用不太深不太浅的hidden layer 层计算

[Gatys et al.,2015. A neural algorithm of artistic style]
4.10 风格损失函数
风格定义为不同激活通道直接的相关系数,

怎么解释? 例如某个channel表示竖直的边缘检测,另一个channel表示橙色色调 ,它们不相关则意味着竖直边缘没啥橙色;
style matrix - 不同channel的相同位置点相乘
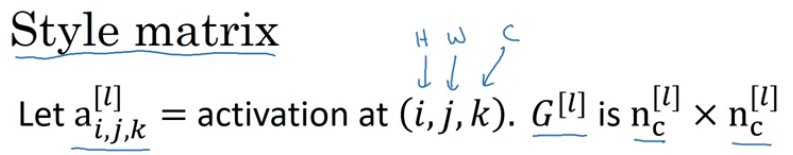
![]()
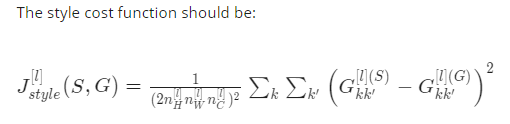
如果用多几层hidden layers来计算style cost function 效果会更好点。底层捕捉简单点的底层特征,高层点的捕捉高层特征
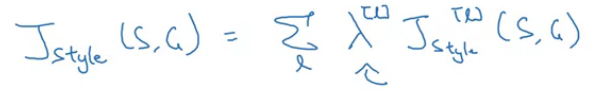
总的cost function为:
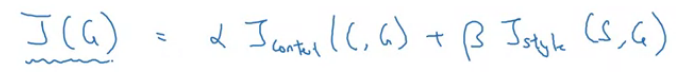
4.11 一维及三维
1D: 信号处理
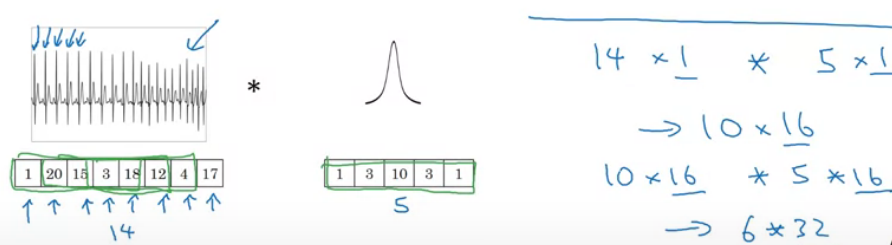
3D - 可以在医学CT三维建模,电影数据(不同帧在电影中按时间顺序的排列)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号