
java零散知识点
1.进程与线程的区别
a.进程是执行着的应用程序,是程序的一种动态形式,是CPU、内存等资源占用的基本单位,而且进程之间相互独立,通信比较困难,进程在执行过程中,包含比较固定的入口,执行顺序,出口;
b.线程是进程内部的一个执行序列,隶属于某个进程,一个进程可以有多个线程,线程不能占有CPU、内存等资源,而且线程之间共享一块内存区域,通信比较方便,线程的入口执行顺序这些过程
被应用程序所控制。
2.创建线程的方式
继承Thread类;
实现Runnable接口;
应用程序可以使用Executor框架来创建线程池;
实现Callable接口
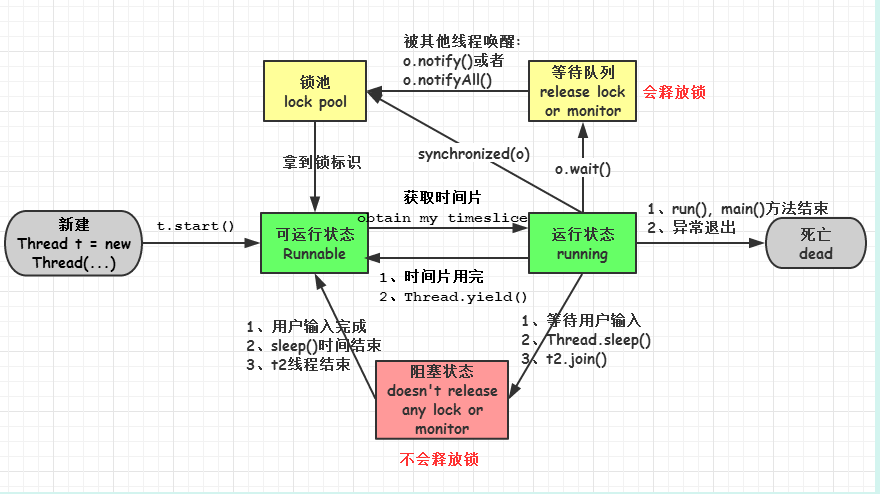
3.线程的几种可用状态
- 新建( new ):新创建了一个线程对象。
- 可运行( runnable ):线程对象创建后,其他线程(比如 main 线程)调用了该对象的start ()方法。该状态的线程位于可运行线程池中,等待被线程调度选中,获取cpu的使用权。
- 运行( running ):可运行状态( runnable )的线程获得了cpu时间片( timeslice ),执行程序代码。
- 阻塞( block ):阻塞状态是指线程因为某种原因放弃了cpu使用权,也即让出了cpu timeslice ,暂时停止运行。直到线程进入可运行( runnable )状态,才有机会再次获得 cpu timeslice 转到运行( running )状态。阻塞的情况分三种:
(一). 等待阻塞:运行( running )的线程执行 o.wait ()方法,JVM会把该线程放入等待队列( waitting queue )中。
(二). 同步阻塞:运行( running )的线程在获取对象的同步锁时,若该同步锁被别的线程占用,则 JVM 会把该线程放入锁池( lock pool )中。
(三). 其他阻塞: 运行( running )的线程执行Thread.sleep ( long ms )或 t.join ()方法,或者发出了 I/O 请求时,JVM会把该线程置为阻塞状态。当 sleep ()状态超时、join()等待线程终止或者超时、或者I/O 处 理完毕时,线程重新转入可运行( runnable )状态。
- 死亡( dead ):线程run()、 main() 方法执行结束,或者因异常退出了run()方法,则该线程结束生命周期。死亡的线程不可再次复生。
![]()
- 4. 同步方法和同步代码块的区别是什么?
-
为何使用同步?
java允许多线程并发控制,当多个线程同时操作一个可共享的资源变量时(增删改查),将会导致数据的不准确,相互之间产生冲突,因此加入同步锁以避免在该线程没有完成操作之前,被其他线程的调用,从而保证了该变量的唯一性和准确性。区别
- 同步方法默认用this或者当前类class对象作为锁;
- 同步代码块可以选择以什么来加锁,比同步方法要更细颗粒度,我们可以选择只同步会发生同步问题的部分代码而不是整个方法;
- 同步方法使用关键字 synchronized修饰方法,而同步代码块主要是修饰需要进行同步的代码,用synchronized(object){代码内容}进行修饰;
- 同步也可以修饰静态方法,此时的锁对象为类的字节码文件对象
5.什么是死锁(deadlock)?
所谓死锁是指多个进 程因竞争资源而造成的一种僵局(互相等待),若无外力作用,这些进程都将无法向前推进。死锁产生的4个必要条件:
- 互斥条件:进程要求对所分配的资源(如打印机)进行排他性控制,即在一段时间内某 资源仅为一个进程所占有。此时若有其他进程请求该资源,则请求进程只能等待。
- 不剥夺条件:进程所获得的资源在未使用完毕之前,不能被其他进程强行夺走,即只能 由获得该资源的进程自己来释放(只能是主动释放)。
- 请求和保持条件:进程已经保持了至少一个资源,但又提出了新的资源请求,而该资源 已被其他进程占有,此时请求进程被阻塞,但对自己已获得的资源保持不放。
- 循环等待条件:存在一种进程资源的循环等待链,链中每一个进程已获得的资源同时被链中下一个进程所请求。
7.什么是迭代器(Iterator)?
Iterator接口提供了很多对集合元素进行迭代的方法。每一个集合类都包含了可以返回迭代器实例的
迭代方法。迭代器可以在迭代的过程中删除底层集合的元素,但是不可以直接调用集合的
remove(Object Obj)删除,可以通过迭代器的remove()方法删除。
8.Iterator和ListIterator的区别是什么?
下面列出了他们的区别:
- Iterator可用来遍历Set和List集合,但是ListIterator只能用来遍历List。
- Iterator对集合只能是前向遍历,ListIterator既可以前向也可以后向。
- ListIterator实现了Iterator接口,并包含其他的功能,比如:增加元素,替换元素,获取前一个和后一个元素的索引,等等。
9.快速失败(fail-fast)和安全失败(fail-safe)的区别是什么?
Iterator的安全失败是基于对底层集合做拷贝,因此,它不受源集合上修改的影响。java.util包下面的所有的集合类都是快速失败的,而java.util.concurrent包下面的所有的类都是安全失败的。快速失败的迭代器会抛出ConcurrentModificationException异常,而安全失败的迭代器永远不会抛出这样的异常。
Java中的HashMap的工作原理是什么?
Java中的HashMap是以键值对(key-value)的形式存储元素的。HashMap需要一个hash函数,它使用hashCode()和equals()方法来向集合/从集合添加和检索元素。当调用put()方法的时候,HashMap会计算key的hash值,然后把键值对存储在集合中合适的索引上。如果key已经存在了,value会被更新成新值。HashMap的一些重要的特性是它的容量(capacity),负载因子(load factor)和扩容极限。
Comparable和Comparator接口是干什么的?列出它们的区别。
Java提供了只包含一个compareTo()方法的Comparable接口。这个方法可以个给两个对象排序。具体来说,它返回负数,0,正数来表明已经存在的对象小于,等于,大于输入对象。
Java提供了包含compare()和equals()两个方法的Comparator接口。compare()方法用来给两个输入参数排序,返回负数,0,正数表明第一个参数是小于,等于,大于第二个参数。equals()方法需要一个对象作为参数,它用来决定输入参数是否和comparator相等。只有当输入参数也是一个comparator并且输入参数和当前comparator的排序结果是相同的时候,这个方法才返回true。
接:https://www.nowcoder.com/questionTerminal/99f7d1f4f8374e419a6d6924d35d9530
来源:牛客网
Comparable & Comparator 都是用来实现集合中元素的比较、排序的,只是 Comparable是在集合内部定义的方法实现的排序,Comparator 是在集合外部实现的排序,所以,如想实现排序,就需要在集合外定义 Comparator 接口的方法或在集合内实现 Comparable 接口的方法。 Comparator位于包java.util下,而Comparable位于包 java.lang下 Comparable 是一个对象本身就已经支持自比较所需要实现的接口(如 String、Integer 自己就可以完成比较大小操作,已经实现了Comparable接口) 自定义的类要在加入list容器中后能够排序,可以实现Comparable接口,在用Collections类的sort方法排序时,如果不指定Comparator,那么就以自然顺序排序, 这里的自然顺序就是实现Comparable接口设定的排序方式。 而 Comparator 是一个专用的比较器,当这个对象不支持自比较或者自比较函数不能满足你的要求时,你可以写一个比较器来完成两个对象之间大小的比较。 可以说一个是自已完成比较,一个是外部程序实现比较的差别而已。 用 Comparator 是策略模式(strategy design pattern),就是不改变对象自身,而用一个策略对象(strategy object)来改变它的行为。 比如:你想对整数采用绝对值大小来排序,Integer 是不符合要求的,你不需要去修改 Integer 类(实际上你也不能这么做)去改变它的排序行为,只要使用一个实现了 Comparator 接口的对象来实现控制它的排序就行了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号