
Pandas 入门
#生成对象
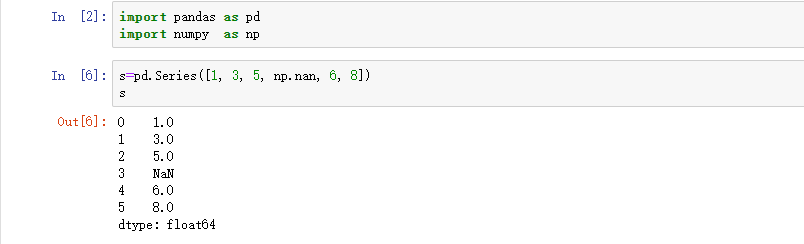
用值列表生成 Series 时,Pandas 默认自动生成整数索引:
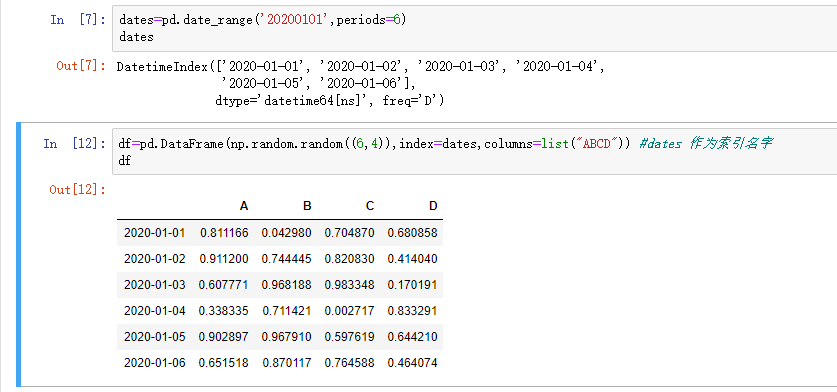
用含日期时间索引与标签的 NumPy 数组生成 DataFrame:
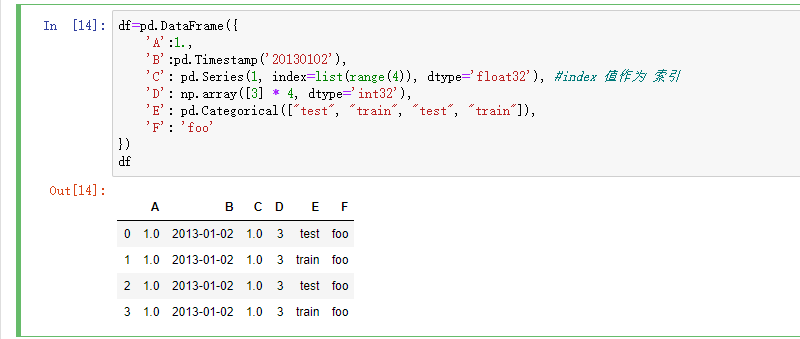
用 Series 字典对象生成 DataFrame:
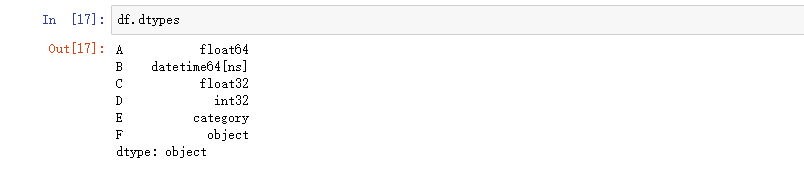
DataFrame 的列可以有不同数据类型。
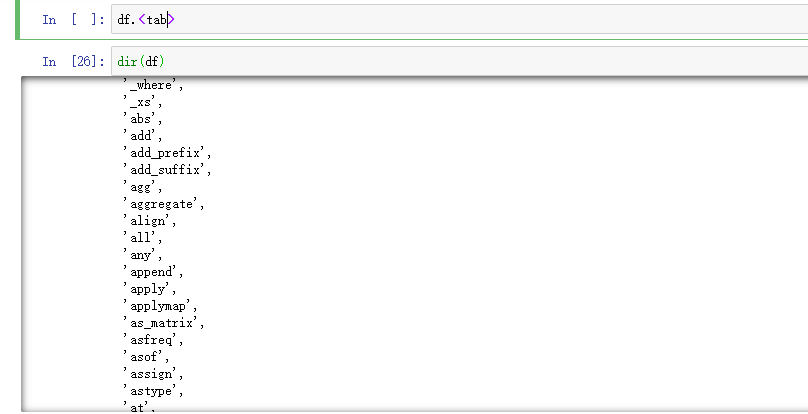
IPython支持 tab 键自动补全列名与公共属性(也可以使用dir列出)。下面是部分可自动补全的属性:
#查看数据
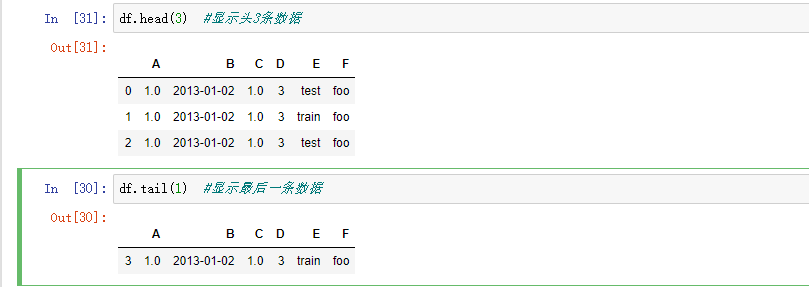
查看Dataframe的头部和尾部数据
显示索引与列名:

df.to_numpy() 输出底层的numpy对象

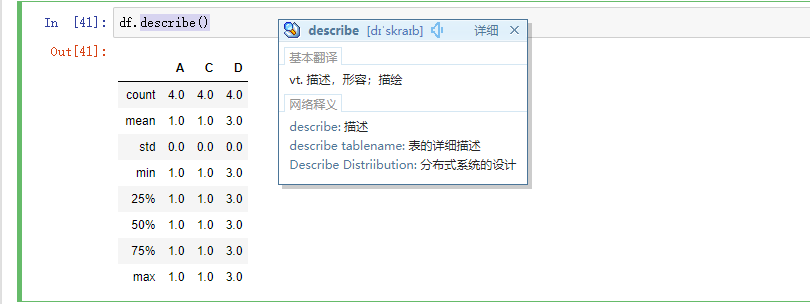
describe()可以快速查看数据的统计摘要:
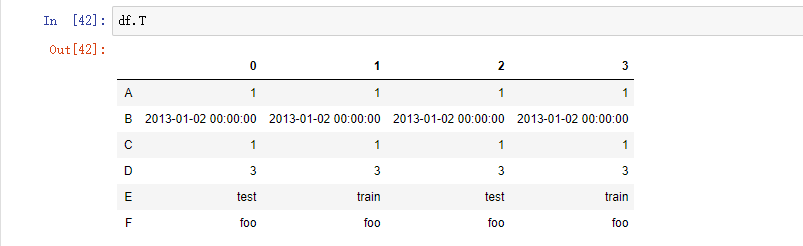
转置数据:可以理解为行列交换
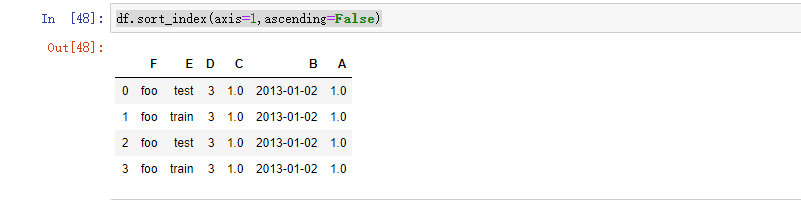
按轴排序:
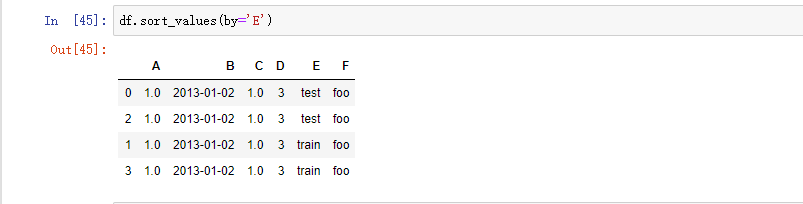
按值排序:
获取数据
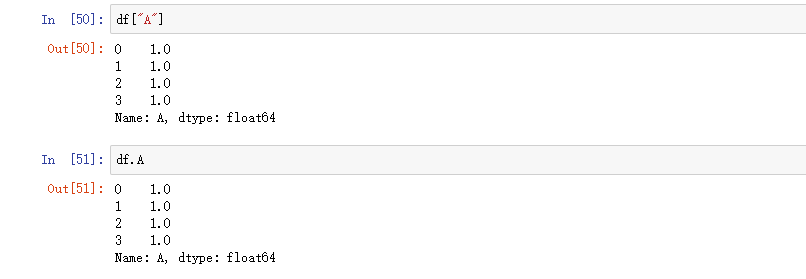
选择单列,产生 Series,与 df.A 等效:
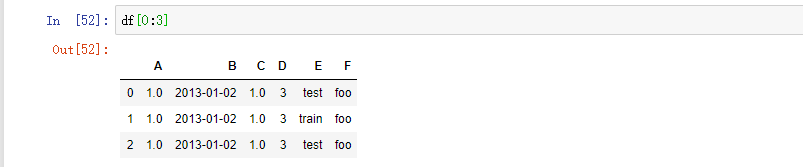
用 [ ] 切片行:
按标签选择
用标签提取一行数据:
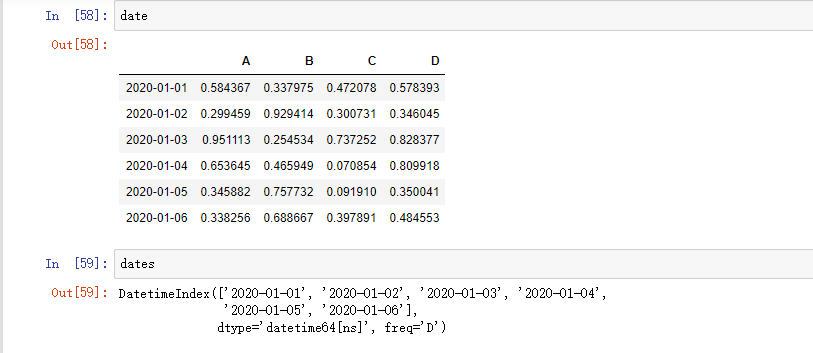

用标签选择多列数据:

用标签切片,包含行与列结束点:

提取标量值:

快速访问标量,与上述方法等效:

按位置选择
用整数位置选择:
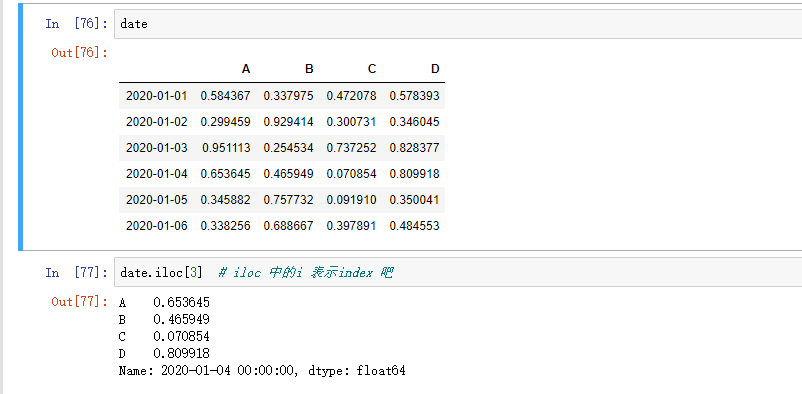
类似 NumPy / Python,用整数切片:

显式整行切片:
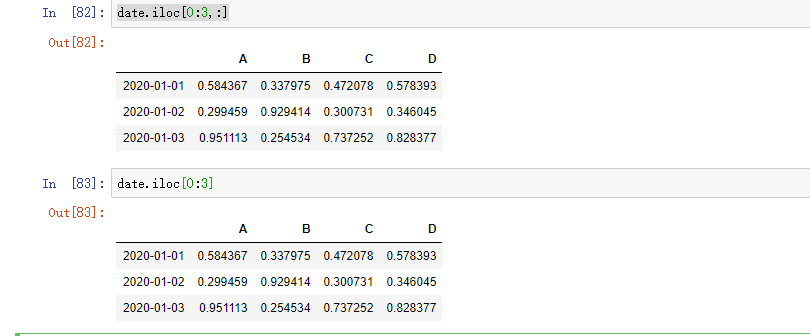
显式提取值:
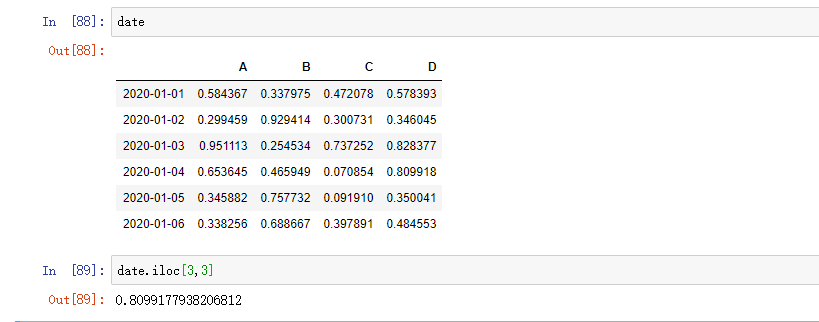
快速访问标量,与上述方法等效:

布尔索引
用单列的值选择数据:
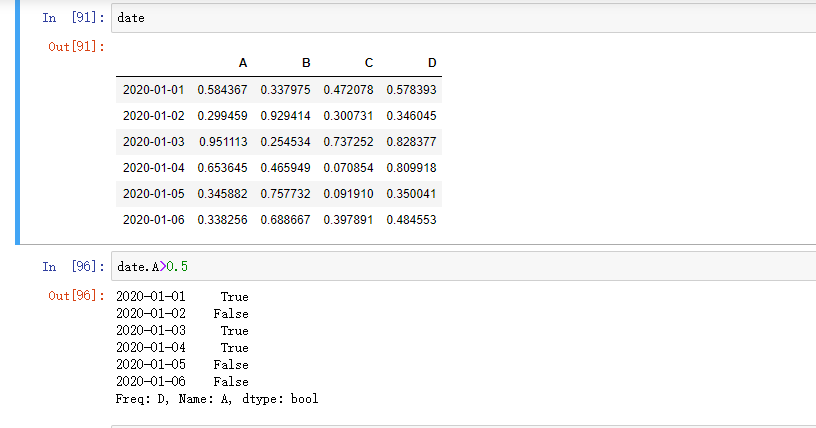
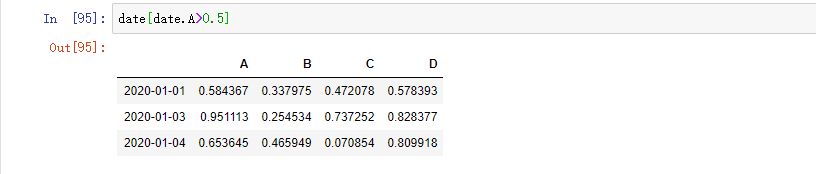
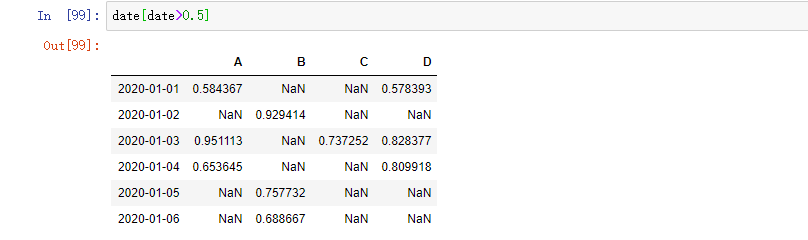
选择 DataFrame 里满足条件的值:
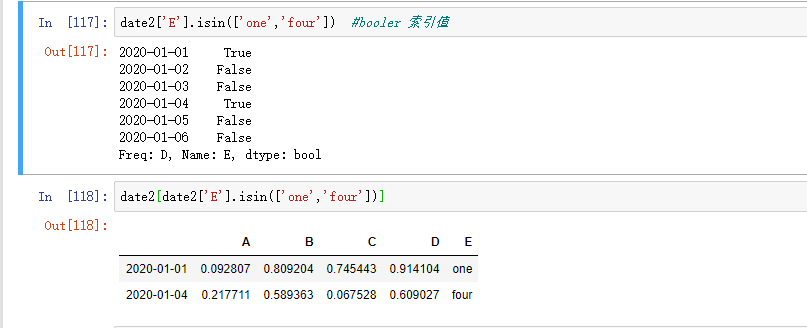
用 isin() 筛选:
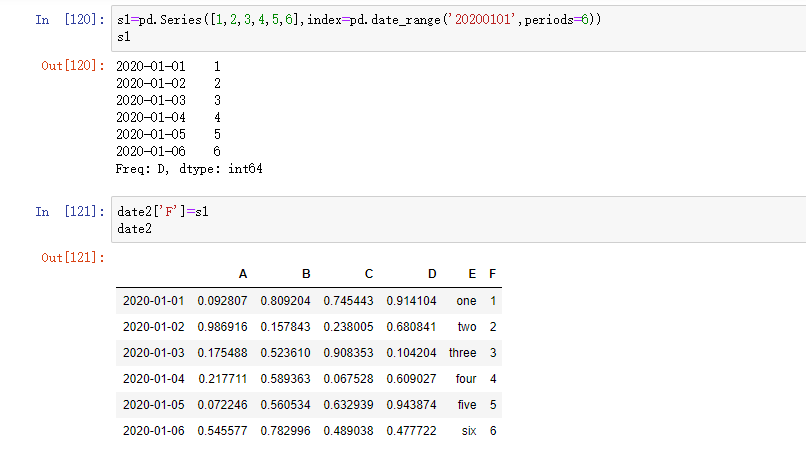
赋值
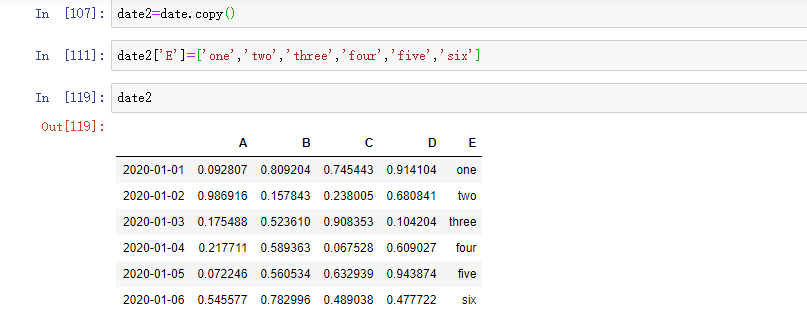
用索引自动对齐新增列的数据:
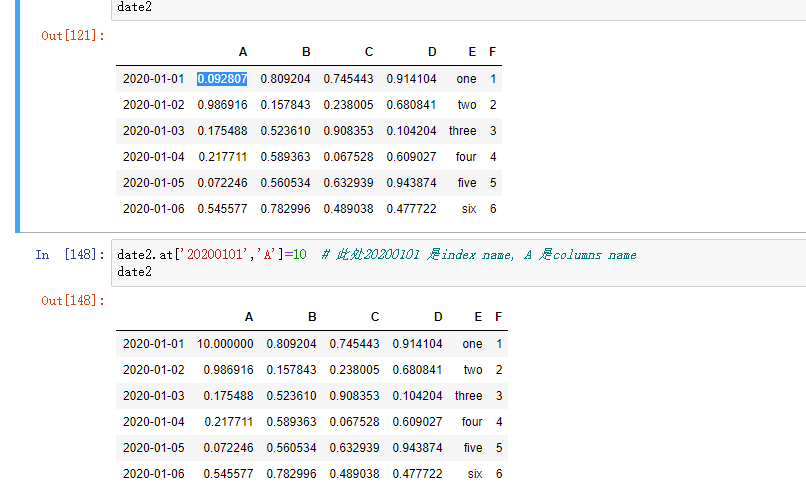
按标签赋值:
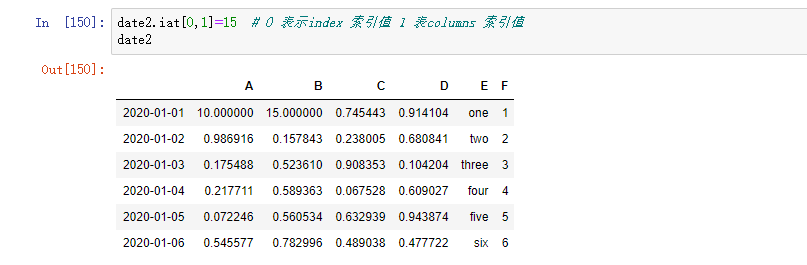
按位置赋值:
按 NumPy 数组赋值:
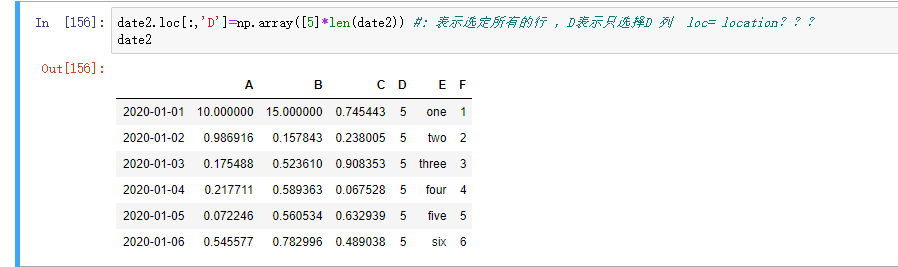
用 where 条件赋值:
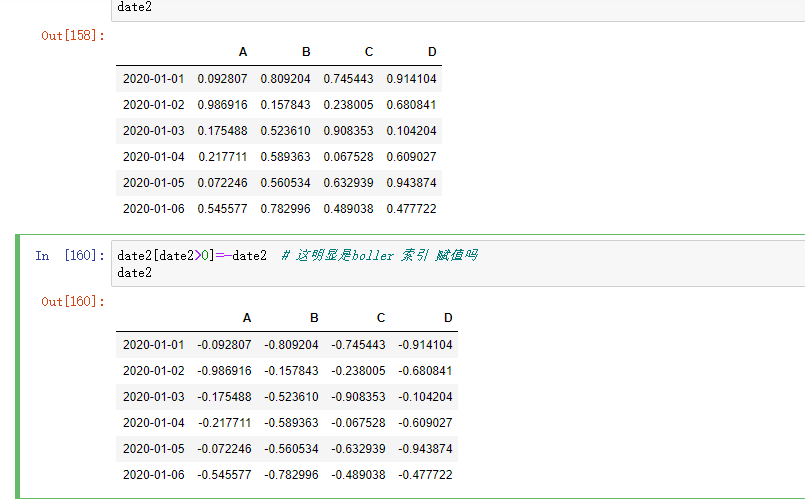
缺失值
Pandas 主要用 np.nan 表示缺失数据。 计算时,默认不包含空值
重建索引(reindex)可以更改、添加、删除指定轴的索引,并返回数据副本,即不更改原数据。
删除所有含缺失值的行:

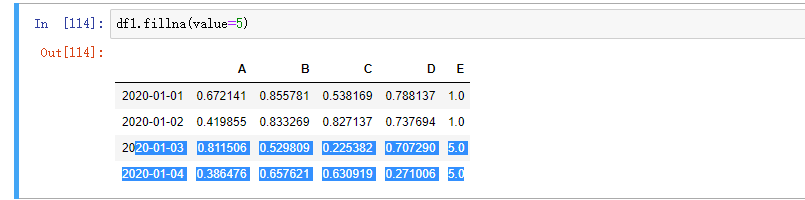
填充缺失值:
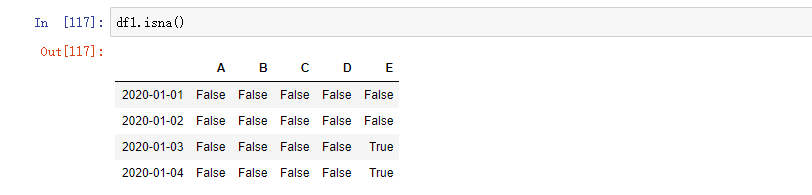
提取 nan 值的布尔掩码:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号