[Python自学] day-9 (paramiko、SSH RSA、线程、GIL、互斥锁、信号量、事件、队列)
一、paramiko模块
(第三方模块,需安装依赖包)
paramiko模块基于SSH来连接远程主机并进行相关操作。
1.SSHClient
SSHClient:用于连接远程主机并执行基本命令。
import paramiko #创建SSH对象 ssh = paramiko.SSHClient() #允许连接不在know_hosts文件中的主机 ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) #当know_hosts文件中不存在远程服务器的公钥时,自动添加进去,类似于使用ssh出现询问时输入yes。 #连接服务器 ssh.connect(hostname='c1.salt.com',port=22,username='wupeiqi',password='passw0rd') #执行命令 stdin,stdout,stderr = ssh.exec_command('df') #获取命令结果 result = stdout.read()
2.SFTPClient
SFTPClient:用于基于SSH传输协议SFTP的客户端。
import paramiko transport = paramiko.Transport(('hostname',22)) #建立连接实例 transport.connect(username='wupeiqi',password='123') #建立连接 sftp = paramiko.SFTPClient.from_transport(transport) #获取SFTP实例 #将文件/tmp/location.py上传至远程服务器/tmp/test.py sftp.put('/tmp/location.py','/tmp/test.py') #将远程服务器文件remote_path 下载到本地 local_path sftp.get('remote_path','local_path') transport.close()
二、SSH秘钥RSA讲解
1.秘钥原理
为了实现无密码登录远程主机(比使用明文账号密码登录更加安全),使用RSA非对称秘钥。
公钥:公钥给远程主机
私钥:自己拿着
公钥和私钥成对出现。
例如A(10.0.0.31)--->B(10.0.0.41):
1.A主机要连接B主机,在A上使用ssh-keygen来生成一对秘钥对(其中包含一个私钥和一个公钥)。如下图:
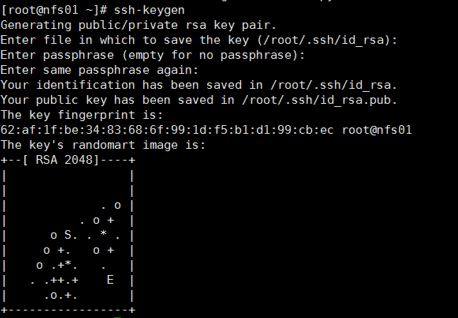
2.ssh-keygen生产了/root/.ssh/id_rsa和/root/.ssh/id_rsa.pub。前者是私钥,后者是公钥。
3.将公钥拷贝到远程主机某个用户下的~/.ssh/authorized_keys文件中。必须确保公钥拷贝过去后是一行(由于某些情况下的复制会导致变为多行,从而导致公钥不生效)。authorized_keys文件权限应该是600,即允许文件拥有者具有读写权限,其他用户都不能修改该文件。
4.尝试连接,无需密码
5.拷贝公钥,除了复制公钥以外。还可以使用命令 ssh-copy-id "-p22 user@hostname" 来自动将公钥拷贝到hostname主机的authorized_keys下。
2.使用秘钥的SSHClient
使用秘钥的SSHClient:
import paramiko private_key = paramiko.RSAKey.from_private_key_file('/home/auto/.ssh/id_rsa') #创建SSH对象 ssh = paramiko.SSHClient() #允许连接不在know_hosts文件中的主机 ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) #连接服务器 ssh.connect(hostname='c1.salt.com',port=22,username='wupeiqi',pkey=private_key) #执行命令 stdin,stdout,stderr = ssh.exec_command('df') #获取命令结果 result = stdout.read()
使用秘钥的SSHClient只需要在代码中读取本地私钥,然后在连接服务器时将password参数替换为key参数即可。
3.Windows生成秘钥
小技巧——使用Windows通过秘钥连接远程Linux主机:
有两种方法:
1.由于Windows没有ssh-keygen,可以在CRT远程终端上生成一个RSA秘钥对来实现。
2.将一个可用的私钥复制到Windows中。例如在Linux A已经可以通过秘钥登录Linux B,那么我们可以复制Linux A主机中的私钥到Windows中。操作如下:
- 使用CRT登录Linux A,然后使用 sz ~/.ssh/id_rsa 命令,将私钥文件拷贝到Windows的默认路径下(该路径可在CRT中的选项->会话选项->终端->X/Y/Zmodem下修改)。该命令需要lrzsz程序的支持,使用yum install lrzsz -y安装。
- 在程序中导入该私钥:
private_key = paramiko.RSAKey.from_private_key_file('D:/ssh/id_rsa')
- 然后就可以在Windows中使用秘钥连接Linux远程主机了。
三、线程
1.线程概念
线程是什么:线程是操作系统能够进行运算调度的最小单位,是一串操作指令的集合。线程包含在进程中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程执行不同的任务。
进程是什么:进程是计算机进行资源调度的最小单位。一个程序以一个整体的形式暴露给操作系统管理,里面包含对各种资源的调度,内存的管理,网络接口等设备的调用等,对各种资源管理的集合,就可以称为进程。进程之间内存默认是不能互相访问的,除非通过消息、共享内存等进程间通讯机制。
- 进程要操作CPU,必要要先创建一个线程。
- CPU的一颗核心同时只能干一件事,CPU上下文的切换(时间片切换)可以让人感觉是同时在运行。
- 一个进程可以包含一个或多个线程,每个线程共享同一块内存区域,而进程之间是不同的内存区域。
进程和线程的区别:
- 线程共享内存区域,进程的内存是独立的。
- 线程直接访问进程的数据段,而多个进程(父进程和子进程)拥有各自的数据段拷贝。
- 线程之间(同一进程里的)可以直接交流数据,两个进程之间想交流数据必须通过一个中间代理,socket、消息队列或共享内存等。
- 新的线程很容易创建,新的进程则需要父进程来拷贝(克隆)。
- 一个线程可以控制同一进程里的其他线程,进程只能操作子进程。
- 对主线程的修改可能会影响到进程中其他线程的运行,但是对父进程的修改不会影响子进程(杀死父进程除外)。
- 线程启动速度快、进程启动速度满。
2.线程创建
Python中线程创建简单实例:
import threading import time def run(index,n): i = 0 while i<=n: print("Thread %s : " % index,i) time.sleep(0.5) i += 1 t1 = threading.Thread(target=run,args=(1,10,)) #创建一个线程,运行run(),参数为(1,10) t2 = threading.Thread(target=run,args=(2,10,)) t1.start() t2.start()
用类的形式创建线程:
#通过类的形式 class MyThread(threading.Thread): def __init__(self,name,num): super(MyThread,self).__init__() self.name = name self.num = num def run(self): i = 0 while i < self.num: print("Thread %s : %s" %(self.name,i)) time.sleep(0.5) i += 1 for i in range(50): #循环启动50个线程 t = MyThread("Leo{}".format(i),10) #创建线程 t.start() #启动线程 print("启动线程完毕")
注意:在上述代码中,50个线程启动完毕后,会直接执行 print("启动线程完毕") ,也就是主线程不等创建的线程执行完毕。
要等待某个线程执行完毕:
class MyThread(threading.Thread): def __init__(self,name,num): super(MyThread,self).__init__() self.name = name self.num = num def run(self): i = 0 while i < self.num: print("Thread %s : %s" %(self.name,i)) time.sleep(0.5) i += 1 t1 = MyThread("Leo",10) t2 = MyThread("jone",20) t1.start() t2.start() t1.join() #主线程等待t1执行完毕
分别在主线程中子线程中打印线程信息:
class MyThread(threading.Thread): def __init__(self,name,num): super(MyThread,self).__init__() self.name = name self.num = num def run(self): i = 0 while i < self.num: print("Thread %s : %s" %(self.name,i)) time.sleep(0.5) i += 1 print("Thread %s : " % (self.name),threading.current_thread()) t1 = MyThread("Leo",10) #在run中打印<MyThread(Leo, started 112644)> t2 = MyThread("jone",20) #在run中打印<MyThread(jone, started 112644)> t1.start() t2.start() t1.join() print("Current_Thread : ",threading.current_thread()) #打印<_MainThread(MainThread, started 113488)>
分别在主线程和子线程中使用threading.current_thread()可以打印出线程信息,主线程默认线程名为MainThread,子线程中我们用Leo和jone覆盖了self.name(默认为Thread-idx,idx为1~n),所以打印的线程名分别为Leo和jone。子线程的线程名可以使用threading.current_thread().getname()来获取。
查询当前存活的线程数量:
print("%s" % (threading.active_count())) #打印当前存活的线程总数,包含主线程。
2.守护线程
守护线程相关知识:
一般情况下:1.主线程中有join,则主线程要等待join的子线程执行完毕后才往下执行。2.主线程没有join,则主线程与子线程并行执行,主线程把最后一句执行完毕后,仍然要等待所有子线程执行完毕后才会结束程序(进程)。
守护线程:将子线程变为守护线程后,主线程一旦执行完毕,不管守护线程时候执行完毕,程序直接结束。如果同时存在一般子线程和守护线程,则主线程只会等待一般的子线程执行完毕,而不会管守护线程是否执行完毕。
将子线程设置为守护线程:
import time import threading def run(str): i = 0 while True: print("%s" % i) time.sleep(0.3) i = i+1 t = threading.Thread(target=run,args=('t-%s',)) t.setDaemon(True) #设置t为守护线程 t.start() #开始执行 time.sleep(5) #主线程休眠5秒,看守护线程是否结束
上述代码中,t.setDaemon(True)必须在t.start()前,否则报错 RuntimeError: cannot set daemon status of active thread
四、GIL全局解释器锁
每一核CPU只能同时执行一个线程(任务),多核的话可以同时执行多个任务。但是在Python中,不管多少核的CPU,都相当于只有一核在执行任务。
GIL只存在在Cpyhton解释器中,Jpython是运行在java虚拟机上的,底层是java自己实现的线程。Pypy也没有GIL。
如图:
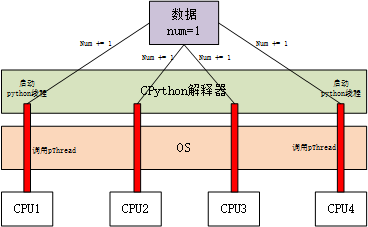
假设有数据num=1,python启动4个线程,并且都运行 num+=1 。
GIL机制运行过程如下:
1.Python启动4个python线程。
2.每个python线程底层调用的是C语言的pThread,也即每一个python线程对应一个C线程。
3.python解释器如果将num传递给4个C线程,然后由CPU执行加1操作,最终每一个线程返回的数据都是2,这样是不行的。
4.为了正确得到结果,只能使4个线程有先后的执行加1操作,但是python解释器是调用的pThread,调用过后无法干涉C线程中的执行过程,所以没办法在C线程层面达到先后加1的效果。
5.所以,python线程只能通过GIL,即全局解释器锁。每个python线程要执行前都要先申请一个GIL Lock,获取到Lock后才能进行运算。例如1号线程先执行num+=1,返回num结果为2,然后第二个python线程再申请lock,再将num=2执行加1。
6.(只在Python2.x,Python已优化)在5中所述情况下,有可能出现一个线程执行加1操作还未完成,就被解释器要求释放lock(解释器每n条指令就需要切换线程),此时加1操作还未完成,工作状态被保存(即上下文),然后另一个线程成功执行了加1操作,num变成2。此时前面那个未完成的线程重新申请了lock,然后从先前保存的上下文还是执行,上下文中的num还是为1,假设这次执行加1成功了, 那么num变为2,这个结果是错误的,num经过了两个线程成功加1,结果应该为3。参照下面的图。
6.python的这种机制,看起来像是多线程并行执行,但是实际上同时只有一个线程在运行。
7.但是,4个加1操作虽然是类似串行运行,但每次加1可能是运行在不同的CPU上的,对应的也是4个C线程,只是线程总体有运算先后顺序罢了。
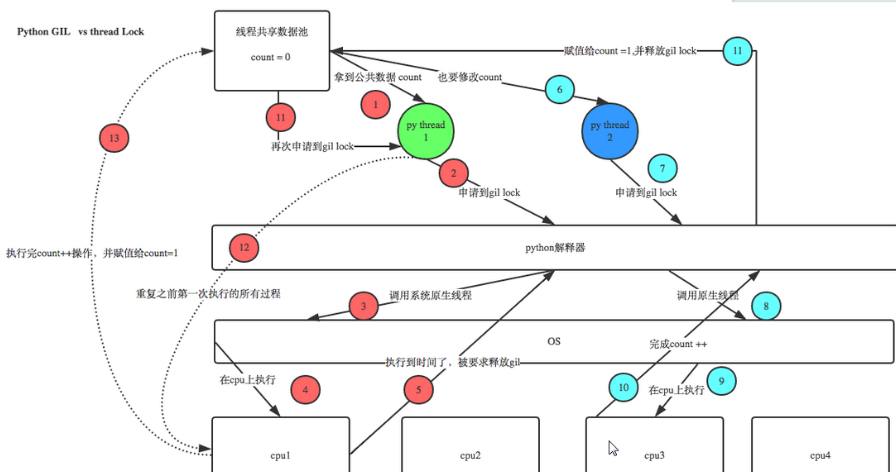
(上述所说的多线程操作一个数据时可能会出现错误,在Python2.x中需要使用 用户数据锁来对数据进行加锁,从而避免运算出错。而在Python3.x中,解释器做了优化,加不加数据锁运算都不会出错。)
五、锁
1.互斥锁
import threading num = 0 lock = threading.Lock() #创建锁 def run(n): lock.acquire() #获取一把锁 global num num += 1 #执行加1操作 lock.release() #释放锁 t_objs = [] for i in range(100): t = threading.Thread(target=run,args=("t",)) t.start() t_objs.append(t) for t in t_objs: t.join() print("num:",num)
2.递归锁:RLock
当出现程序中多层数据锁的时候,使用threading.Lock普通锁,可能会出现程序死锁,即程序无法返回,例如以下代码:
import threading num,num2 = 0,0 lock = threading.Lock() #创建锁 def run1(): lock.acquire() #run1 获取一把锁 global num num += 1 lock.release() #run1 释放锁 def run2(): lock.acquire() #run2 获取一把锁 global num2 num2 += 1 lock.release() #run2 释放锁 def run3(): lock.acquire() #run3 获取一把锁 run1() run2() lock.release() #run3 释放锁 t_objs = [] for i in range(10): t = threading.Thread(target=run3) t.start() while threading.active_count() != 1: #还有子线程在运行,则打印当前线程数 print(threading.active_count()) else: print("---all threads done---") #如果子线程都已经执行完毕,则打印done print("num = %s , num2 = %s" % (num,num2)) #打印num和num2的值
为了避免出现死锁,只需要将threading.Lock()修改为threading.RLock()即可,也即使用递归锁。原理是在使用锁的时候采用了一个字典来保存每一扇门对应的钥匙,这样就不会像普通Lock一样将钥匙弄混,导致死锁。
六、信号量
信号量:
使用方法类似互斥锁,如下代码:
semaphores = threading.BoundedSemaphore(5) #表示可以同时允许5个线程 def run(): semaphores.acquire() time.sleep(2) semaphores.release()
可以用在什么地方:例如socket服务器对每个请求都会创建一个Python线程来处理,默认Python是没有限制请求对应的线程数量的。我们可以通过使用信号量来限制线程的数量,从而保证服务器性能。
七、事件
线程间如何交互数据?
例如一个线程模拟红绿灯,每一段时间修改红绿灯状态。另外多个线程模拟汽车,每两秒扫描一下红绿灯,红灯停绿灯行。
我们可以使用一个全局变量来代表红绿灯,然后在红绿灯线程中修改,在汽车线程中查询:
import time redLight = False #红绿灯状态,全局变量 def run(): #线程方法 global redLight #使用全局变量 counter = 1 #红绿灯时间计数 while True: if redLight: print("目前是 : 绿灯 ",counter) else: print("目前是 : 红灯 ",counter) if counter % 30 == 0: #红灯30秒 redLight = True elif counter % 50 == 0: #绿灯20秒 redLight = False counter = 0 counter += 1 time.sleep(1) run()
使用事件来实现:
event = threading.Event()
event.set() #设置绿灯
event.clear() #清除绿灯(设置红灯)
event.wait() #等待设置绿灯(即等红灯)
import time import threading event = threading.Event() #创建一个事件 def run1(): #线程方法 counter = 1 #红绿灯时间计数 while True: print(counter) if counter % 30 == 0: #红灯30秒 event.set() #事件set,表示Ture print("绿灯亮") elif counter % 50 == 0: #绿灯20秒 event.clear() #事件clear,表示False counter = 0 print("红灯亮") counter += 1 time.sleep(1) def run2(): while True: if event.is_set(): #如果event是set,那就是绿灯 print("绿灯,通过") else: print("红灯,等待") event.wait() #否则是红灯,则使用event.wait等待set time.sleep(5) t_redlight = threading.Thread(target=run1) t_car = threading.Thread(target=run2) t_redlight.start() t_car.start()
八、队列queue
FIFO:先进先出
LIFO:后进先出
1.普通queue
先进先出:
import queue q = queue.Queue() #定义个队列 queue.Queue(maxsize=100):最多放100个数据 q.put("d1") #放入一个数据 q.put("d2") q.put("d3") q.put("d4") print(q.qsize()) #打印队列中数据的数量 print(q.get()) #打印q2 print(q.get()) #打印q1
当queue中没有数据时,使用get()会阻塞:
import queue myQueue = queue.Queue() myQueue.put("Hello") myQueue.put("World") print(myQueue.get()) print(myQueue.get()) print(myQueue.get()) #这一次运行myQueue.get()程序会阻塞
如果不想程序阻塞可以使用get_nowait(),但是会抛异常:
import queue myQueue = queue.Queue() myQueue.put("Hello") myQueue.put("World") print(myQueue.get()) print(myQueue.get()) print(myQueue.get_nowait()) #如果queue中没有数据,使用get_nowait()会抛异常"queue.Empty"
get_nowait()相当于get(block=False)。也可以使用get(timeout=2)来设置阻塞时间。
我们可以使用try except来捕获异常,就说明queue中已经没有数据了:
import queue myQueue = queue.Queue() myQueue.put("Hello") myQueue.put("World") while True: try: print(myQueue.get_nowait()) except queue.Empty: #捕获异常 print("Queue get member err") break
2.LifoQueue
后进先出队列:
import queue myQueue = queue.LifoQueue() myQueue.put("Hello") myQueue.put("World") print(myQueue.get()) #输出World print(myQueue.get()) #输出Hello
3.PriorityQueue
PriorityQueue,数据可带优先级的队列:
import queue myQueue = queue.PriorityQueue() myQueue.put((-1,"Hello")) myQueue.put((9,"World")) myQueue.put((100,"Love")) myQueue.put((-9,"Good")) myQueue.put((87,"You")) print(myQueue.get()) #(-9, 'Good') print(myQueue.get()) #(-1, 'Hello') print(myQueue.get()) #(9, 'World') print(myQueue.get()) #(87, 'You') print(myQueue.get()) #(100, 'Love')
把优先级和数据存放为一个元组,然后作为参数传递给队列。get数据的时候,会根据元组的第一个数据(优先级)排序取出。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号