
创建sc,pv,pvc

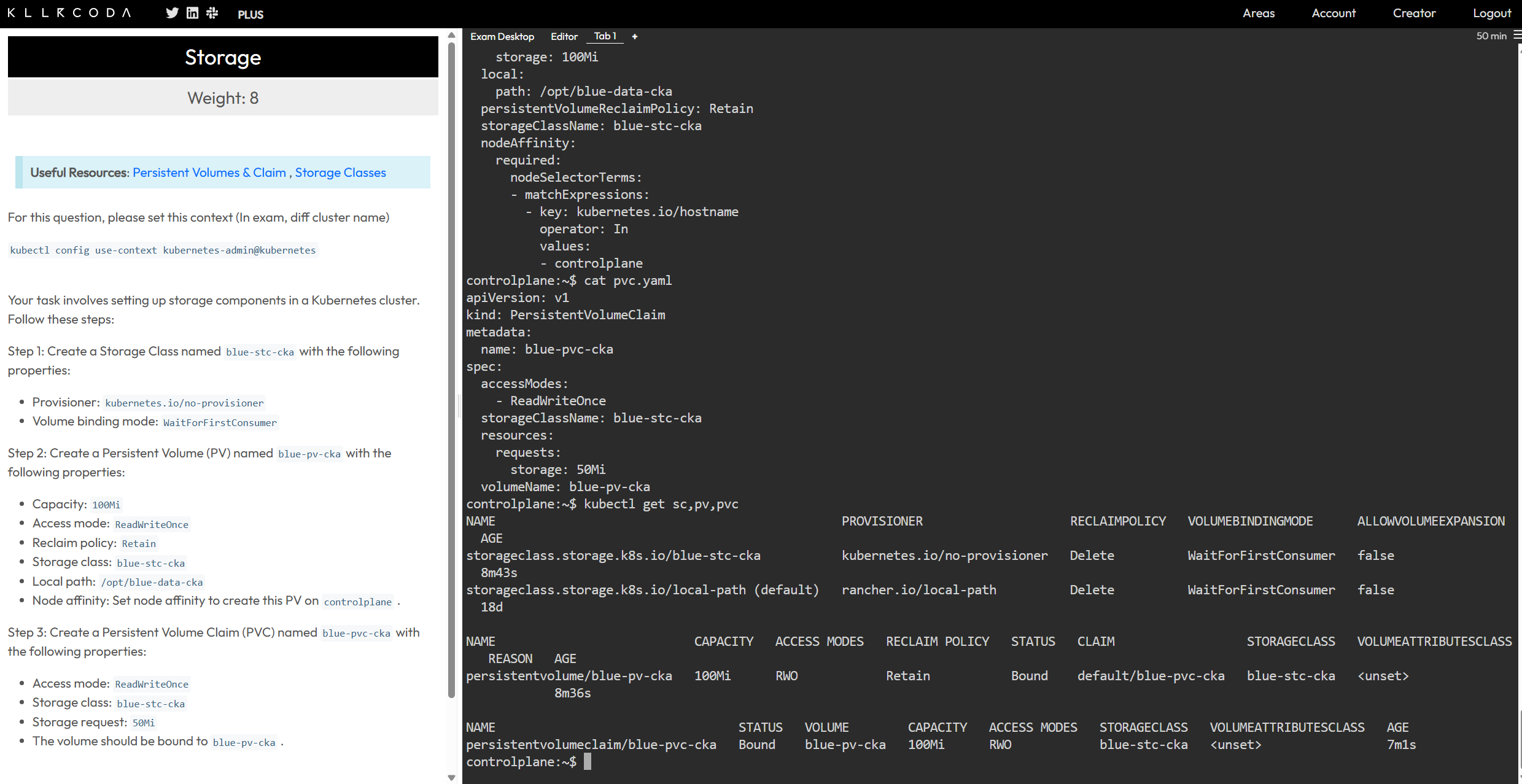
这道题得核心点我感觉再sc得这个volumebindingmode这个参数这里,我们需要注意得是,指定了WaitForFirstConsumer这个参数,意味这延迟绑定pv,意思就是他会等pod创建出来以后再决定绑定再那个节点。所以说上述得pvc里得volumename就没必要了。但是题目中明确要求了绑定,这可能是在考察:StorageClass 的匹配机制:PV 和 PVC 的 storageClassName 需一致。
WaitForFirstConsumer 的理解:正常情况下(无 volumeName),延迟绑定是本地存储的最佳实践。还有以一种解决方案就是直接指定pod得调度节点nodeselector就行,让pod和pv再同一节点就行。但是生产环境中这种存储是比较少见得,再测试环境中应该会常用,再彼得环境中我们尽量选择其他高效得存储策略。
这种基于 节点亲和性(Node Affinity) 和 延迟绑定(WaitForFirstConsumer) 的存储配置在生产环境中有非常实际的用途,主要适用于 本地存储(Local Storage) 和 特定硬件绑定的存储场景。以下是典型的应用场景和优势:
1. 本地存储(Local NVMe/SSD/高性能磁盘)
场景
- 某台节点(如 GPU 机器或高性能计算节点)配备了 本地 NVMe SSD,需要被 Pod 独占访问。
- 例如:
- 数据库(MySQL、PostgreSQL)需要低延迟磁盘。
- 大数据处理(Spark、Flink)的临时存储。
- AI 训练任务的缓存目录。
配置方式
- PV 定义:
apiVersion: v1 kind: PersistentVolume metadata: name: fast-local-pv spec: capacity: storage: 500Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Retain storageClassName: local-storage local: path: /mnt/ssd/data # 节点本地路径 nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - gpu-node-1 # 只能在这台机器上使用 - PVC 使用
WaitForFirstConsumer:apiVersion: v1 kind: PersistentVolumeClaim metadata: name: app-local-pvc spec: accessModes: - ReadWriteOnce storageClassName: local-storage resources: requests: storage: 200Gi # 不指定 volumeName,让调度器动态绑定
优势
- 高性能:本地 SSD 提供极低延迟(比网络存储如 EBS/Ceph 快 10-100 倍)。
- 资源隔离:避免网络存储的带宽争抢。
- 成本优化:无需额外购买共享存储。
2. 特定硬件绑定的存储(如 FPGA 加速卡配套存储)
场景
- 某些机器配备了 特殊硬件(如 FPGA 加速卡),其配套的存储只能在该节点使用。
- 例如:
- 视频转码服务的临时存储必须和 GPU/FPGA 在同一节点。
- 高频交易系统的内存盘(
/dev/shm)。
配置方式
- PV 绑定到特定节点:
nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: accelerator operator: In values: - fpga # 只有带 fpga 标签的节点能用 - Pod 必须调度到对应节点:
spec: nodeSelector: accelerator: fpga
优势
- 硬件与存储强绑定:确保计算和存储在同一台物理机,避免跨节点延迟。
- 避免数据迁移:FPGA 处理的数据直接写入本地,无需网络传输。
3. 边缘计算(Edge Computing)
场景
- 边缘节点(如工厂、车载设备)需要 本地持久化数据,但无法依赖云端存储。
- 例如:
- 物联网(IoT)设备的数据缓存。
- 离线环境的日志存储。
配置方式
- PV 仅绑定到边缘节点:
nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: node-role.kubernetes.io/edge operator: Exists # 只有边缘节点能用 - PVC 动态绑定:
storageClassName: edge-local-storage volumeBindingMode: WaitForFirstConsumer
优势
- 离线可用:不依赖网络存储。
- 低延迟:数据直接在边缘节点处理。
4. 关键注意事项
适用场景
✅ 适合:
- 需要 低延迟 或 高吞吐 的应用(如数据库、AI 训练)。
- 硬件绑定的存储(如 GPU 机器配套的 NVMe)。
- 边缘计算(本地持久化数据)。
❌ 不适合:
- 需要 跨节点迁移 的应用(如无状态服务)。
- 对 持久化要求不高 的临时存储(可用
emptyDir替代)。
总结
| 场景 | 存储类型 | Kubernetes 配置 | 优势 |
|---|---|---|---|
| 本地高性能存储 | NVMe/SSD | local + nodeAffinity |
超低延迟 |
| 硬件绑定存储 | FPGA/GPU 配套存储 | nodeSelector 匹配硬件标签 |
避免数据迁移 |
| 边缘计算 | 边缘节点本地磁盘 | WaitForFirstConsumer |
离线可用 |
核心思想
nodeAffinity+WaitForFirstConsumer确保存储和计算在最优位置绑定。- 避免网络存储瓶颈,最大化本地磁盘性能。
生产环境中,这种配置常见于 数据库、AI 训练、边缘计算 等对存储性能或位置敏感的场景。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号