

实验4.Hadoop的思想与原理
1.用图与自己的话,简要描述Hadoop起源与发展阶段。
Hadoop是道格·卡丁(Doug Cutting)创建的,Hadoop起源于开源网络搜索引擎Apache Nutch,后者本身也是Lucene项目的一部分。Nutch项目面世后,面对数据量巨大的网页显示出了架构的灵活性不够。当时正好借鉴了谷歌分布式文件系统,做出了自己的开源系统NDFS分布式文件系统。第二年谷歌又发表了论文介绍了MapReduce系统,Nutch开发人员也开发出了MapReduce系统。随后NDFS和MapReduce命名为Hadoop,成为了Apache顶级项目。
2.用图与自己的话,简要描述名称节点、数据节点的主要功能及相互关系。
~名称节点:负责管理分布式文件系统的命名空间,记录每个文件中各个块所在的数据节点的位置信息;
~数据节点:是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者名称节点的调度来进行数据的存储和检索,并向名称节点定期发送自己所存储的块的列表。
~在名称节点启动时,因为EditLog 要小很多。每次执行写操作之后,且在向客户端发送成功代码之前,edits文件都需要同步更新。为了防止Editl og过大的问题,引入了数据节点。
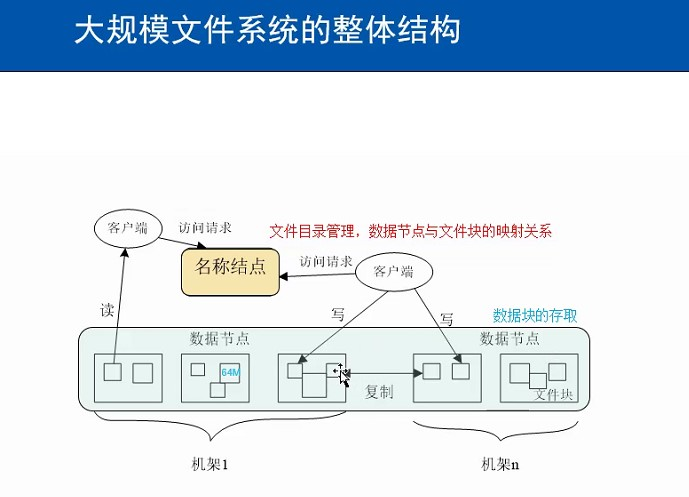
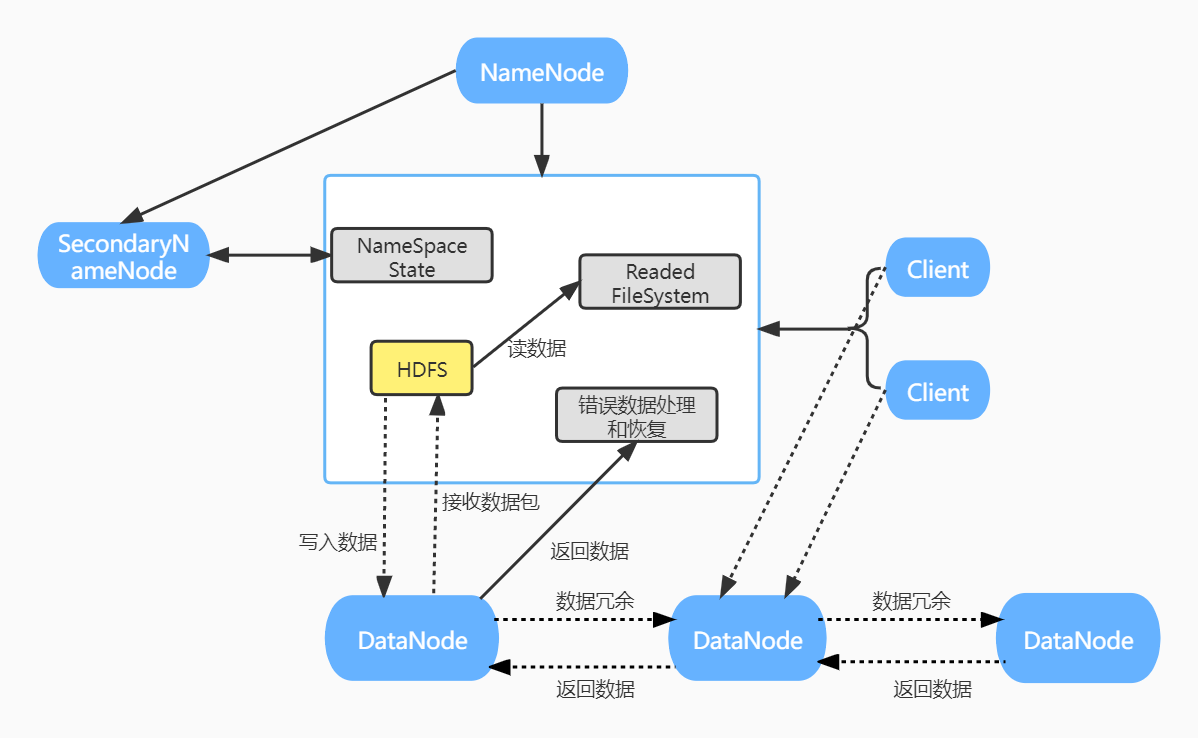
3.分别从以下这些方面,梳理清楚HDFS的 结构与运行流程,以图的形式描述。
- 客户端与HDFS
- 客户端读
- 客户端写
- 数据结点与集群
- 数据结点与名称结点
- 名称结点与第二名称结点
- 数据结点与数据结点
- 数据冗余
- 数据存取策略
- 数据错误与恢复
![]()
4.梳理HBase的结构与运行流程,以用图与自己的话进行简要描述,图中包括以下内容:
- Master主服务器的功能
- Region服务器的功能。
- Zookeeper协同的功能.
- Client客户端的请求流程
- 四者之间的相系关系
- 与HDFS的关联

(1)Master主服务器的功能
管理用户对Table表的增、删、改、查操作;
管理HRegion服务器的负载均衡,调整HRegion分布;
(2)Region服务器的功能
HRegion部分由很多的HRegion组成,存储的是实际的数据。每一个HRegion又由很多的Store组成,每一个Store存储的实际上是一个列簇(ColumnFamily)下的数据。
(3)Zookeeper协同的功能
zookeeper是hbase集群的"协调器"。由于zookeeper的轻量级特性,因此我们可以将多个hbase集群共用一个zookeeper集群,以节约大量的服务器.
(4)Client客户端的请求流程
Client请求Zookeeper确定meta表所在的RegionServer所在的地址,接着根据Rowkey找到数据所归属的RegionServer;用户提交put或delete请求时HbaseClient会将put或delete请求添加到本地buffer中,符合一定条件会通过异步批量提交服务器处理。
(5)与HDFS的关联
HDFS是GFS的一种实现,他的完整名字是分布式文件系统,类似于FAT32,NTFS,是一种文件格式,是底层的,Hadoop HDFS为HBase提供了高可靠性的底层存储支持。
HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统
5.理解并描述Hbase表与Region与HDFS的关系。
HBase是一个分布式的、面向列的开源数据库,Hbase是Hadoop database即Hadoop数据库。HBase的数据通常存储在HDFS上。HDFS为HBase提供了高可靠性的底层存储支持。
每张表一开始只有一个 Region,但是随着数据的插入,HBase 会根据一定的规则将表进行水平拆分,形成两个 Region。 当表中的行越来越多时,就会产生越来越多的 Region,而这些 Region 无法存储到一台机器上时,则可将其分布存储到多台机器上。
6.理解并描述Hbase的三级寻址。
客户端首先访问Zookeeper,获取-ROOT-表的位置信息>>>>访问-ROOT-表,获取.META.表的文位置信息>>>>访问.META.表,找到所需的Region位于哪个服务器,然后到该服务器读取数据。
7.假设.META.表的每行(一个映射条目)在内存中大约占用1KB,并且每个Region限制为2GB,通过HBase的三级寻址方式,理论上Hbase的数据表最大有多大?
理论上Hbase的数据表最大为:(2GB/1KB)×(2GB/1KB)=242 Region
8.MapReduce的架构,各部分的功能,以及和集群其他组件的关系。
9.MapReduce的工作过程,用自己词频统计的例子,将split, map, partition,sort,spill,fetch,merge reduce整个过程梳理并用图形表达出来。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号