


20191330雷清逸 学习笔记10
20191330 雷清逸 学习笔记10(第十二章)
一、知识点归纳以及自己最有收获的内容
知识点归纳
摘要
本章讨论了块设备I/O和缓冲区管理;解释了块设备I/O的原理和I/O缓冲的优点;论述了Unix的缓冲区管理算法,并指出了其不足之处;还利用信号量设计了新的缓冲区管理算法,以提高I/O缓冲区的缓存效率和性能;表明了简单的PV算法易于实现,缓存效果好,不存在死锁和饥饿问题;还提出了一个比较Unix缓冲区管理算法和PV算法性能的编程方案。编程项目还可以帮助读者更好地理解文件系统中的I/O操作。
最有收获的部分
- 有关块设备I/O缓冲区的相关知识
- 有关Unix I/O缓冲区管理算法的相关知识
- 有关新的I/O缓冲区管理算法的相关知识
- 有关PV算法的相关知识
块设备I/O缓冲区
- 读写普通文件的算法依赖于两个关键操作,即:get_block和put_block,这两个操作将磁盘块读写到内存缓冲区中。
- I/O缓冲的基本原理非常简单。文件系统使用一系列I/O缓冲区作为块设备的缓存内存。
- 在讨论缓冲区管理算法之前,我们先来介绍以下术语:定义一个bread(dev,blk)函数,它会返回一个包含有效数据的缓冲区(指针)。
BUFFER *BREAD(dev,blk)
{
BUFFER *bp = gerblk(dev,blk);
if (bp data valid)
return bp;
bp -> opcode = READ;
start_io(bp);
wait for I/O completion;
return bp;
}
从缓冲区读取数据后,进程通过brelse(bp)将缓冲区释放回缓冲区缓存。同理,定义一个write_block(dev,blv,data)函数,如:
write_block(dev,blk,data)
{
BUFFER *bp = bread(dev,blk);
write data to bp;
(synchronous write)? bwrite(bp) : dwrit(bp);
}
其中bwrite(bp)表示同步写入,dwrite(bp)表示延迟写入,如下文所示。
bwrite(BUFFER *bp){
bp -> opcode = WRITE;
start_io(bp);
wait for I/O completion;
brelse(bp);
}
dwrite(BUFFER *bp){
mark bp dirty for delay_write;
brelse(bp);
}
同步写入操作等待写操作完成。它用于顺序块或可移动块设备,对于随机访问设备,例如硬盘,所有的写操作都是延迟写操作。在延迟写操作中,dwrite(dp)将缓冲区标记为脏,并将其释放到缓冲区缓存中。
脏缓冲区只有在被重新分配到不同的磁盘块时才会被写入磁盘,此时缓冲区将被以下代码写入:
awrite(BUFFER *BP)
{
bp -> opcode = ASYNC;
start_io(bp);
}
awrit()会调用start_io在缓冲区开始I/O操作,但是不会等待操作完成。
物理块设备I/O:每个设备都有一个I/O队列,其中包含等待I/O操作的缓冲区。缓冲区上的start_io()操作如下:
start_io(BUFFER *bp)
{
enter bp into device I/O queue;
if (bp is first buffer in I/O queue)
issue I/O command for bp to device;
}
Unix I/O缓冲区管理算法
Unix缓冲区管理子系统由以下几部分组成。
(1)I/O缓冲区:内核中的一系列NBUF缓冲区用作缓冲区缓存。每个缓冲区用一个结构体表示。
缓冲区结构体由两部分组成:用于缓冲区管理的缓冲头部分和用于数据块的数据部分。
(2)设备表:每个块设备用一个设备表结构表示。
每个设备表都有一个dev_lise,包含当前分配给该设备的I/O缓冲区,还有一个io_queue,包含设备上等待I/O操作的缓冲区。
(3)缓冲区初始化:当系统启动时,所有I/O缓冲区都在空闲列表中,所有设备列表和I/O队列均为空。
(4)缓冲区列表:当缓冲区分配给(dev,blk)时,它会被插入设备表的dev_list中。
(5)Unix getblk/brelse算法
以下是关于Unix算法的一些具体说明。
(1)数据一致性:为了确保数据一致性,getblk一定不能给同一个(dev,blk)分配多个缓冲区。
(2)缓存效果:缓存效果可通过以下方法实现。释放的缓冲区保留在设备列表中,以便可能重用。标记为延迟写入的缓冲区不会立即产生I/O,并且可以重用。缓冲区会被释放到空闲列表的末尾,但分配是从空闲列表的前面开始的。
(3)临界区:设备中断处理程序可操作缓冲区列表,例如从设备表的I/O队列中删除bp,更改其状态并调用brelse(bp)。
Unix算法的缺点
(1)效率低下:该算法依赖于重试循环。
(2)缓存效果不可预知:在Unix算法中,每个释放的缓冲区都可被获取。
(3)可能会出现饥饿:Unix算法基于“自由经济”原则,即每个进程都有尝试的机会,但不能保证成功。
(4)该算法使用只适用于单处理器系统的休眠/唤醒操作。
新的I/O缓冲区管理算法
我们将展示一种用于I/O缓冲区管理的新算法。我们将在信号量上使用P/V来实现进程同步,而不是使用休眠/唤醒。信号量的主要优点是:
(1)计数信号量可用来表示可用资源的数量,例如:空闲缓冲区的数量。
(2)当多个进程等待一个资源时,信号量上的V操作只会释放只会释放一个等待进程,该进程不必重试,因为它保证拥有资源。
使用信号量的缓冲区管理算法
使用计数信号量上的P/V来设计满足以下要求的新的缓冲区管理算法:
(1)保证数据一致性。
(2)良好的缓存效果。
(3)高效率:没有重试循环,没有不必要的进程“唤醒”。
(4)无死锁和饥饿。
PV算法

接下来,我们要证明PV算法是正确的,并且满足要求。
(1)缓冲区唯一性:在getblk()中,如果有空闲缓冲区,则进程不会在(1)处等待,而是会搜索dev_list。
(2)无重试循环:进程重新执行while(1)循环的唯一位置是在(6)处,但这不是重试,因为进程正在不断地执行。
(3)无不必要唤醒:在getblk()中,进程可以在(1)处等待空闲缓冲区,也可以在(4)处等待所需的缓冲区。
(4)缓存效果:在Unix算法中,每个释放的缓冲区都可被获取。
(5)无死锁和饥饿:在getblk()中,信号量锁定顺序始终时单向的,即P(free),然后是P(bp),但决不会反过来,因此不会发生死锁。
二、问题与解决思路
问题:Linux/Unix中的块设备如何提高I/O效率?
答:磁盘高速缓存是内核利用内存提供的磁盘数据的缓存,提高不同进程读写同一份数据的效率,包含索引节点高速缓存,目录项高速缓存和页高速缓存等。现在磁盘通常使用RAID卡来提高磁盘的可用性和冗余能力,RAID卡通常都提供了硬件层面的读写缓存,并自带电池保证断电的情况下缓存数据不丢失。
扇区是块设备传递数据的最小单位,不允许传送少于一个扇区的数据,通常一个扇区的大小为512bytes。
块是VFS和文件系统传送数据的基本单位,块的大小必须是扇区的整数倍,最大不能超过一个页框,每个块在内核都有对应的块缓冲区,两者大小一致,读取数据时会将硬件读取的值来填充对应的块缓冲区,写入数据时从块缓冲区中的实际值来更新硬件对应的扇区。
段是ELF文件中的概念,同一个段的数据在磁盘上是连续的,但是对应的页框不一定是连续的,这种将相邻扇区的数据传递到非连续内存区的方式称为分散-聚合DMA传送。如果多个段的页框是相邻的且对应的数据块也是相邻的,则通用块层会将其合并成一个更大的内存区,称为物理段。一次分散-聚合DMA传送可能会涉及多个段的数据读取,块设备驱动程序必须支持。
通用块层是一个内核组件,他处理所有来自内核的对块设备的读写请求,其核心数据结构是bio,代表一个块,每启动一次新的I/O操作时,就会通过bio_alloc()函数由slab分配器分配一个新的bio结构,I/O操作时bio中的部分字段会实时更新。其提供的功能如下:
(1)将数据缓冲区放在高端内存区,仅当CPU访问其中的数据时,才将其映射到内核空间,访问结束后取消映射。
(2)通过零-复制模式将数据缓冲区直接映射到进程用户态地址空间内,避免磁盘数据从内核空间拷贝到用户空间。
(3)管理逻辑卷和磁盘分区,发挥大部分新磁盘控制器的高级特性。
通用块层收到IO请求后会将其对某个磁盘分区的请求转换成对整块磁盘的部分扇区的请求而忽略磁盘分区的存在,然后将IO请求传给I/O调度程序做适当的合并处理。
I/O调度层也是一个内核组件,用于对通用块层发出的I/O请求做适当的合并处理,即对相邻的几个扇区的数据请求合并成一个请求,减少读写数据过程中磁头移动的耗时,从而提高磁盘I/O效率。块设备待处理的I/O请求用request数据结构表示,每个请求可能包含一个或者多个bio结构,I/O调度层的合并操作就是把bio结构加入一个已经存在的合适的request结构中,块设备驱动程序处理request时会逐一遍历处理所有的bio结构。每个块设备都维护自己的I/O请求队列,I/O调度针对单个I/O请求队列。请求队列的数据结构为request_queue,实质上就是一个双向链表,元素就是request结构,元素排序的顺序由I/O调度算法确定。每个请求队列都有一个允许处理的最大请求数,默认情况下最多有128个读请求和128个写请求,如果请求队列满了则添加I/O请求的进程会被阻塞。块设备驱动程序会周期的(通常是3ms)从请求队列中取出一个待处理的request结构,然后发送合适的命令给设备控制器完成数据读写请求。
内核提供了四种I/O调度算法,预期算法,最后期限算法,CFQ完全公平队列算法和Noop算法,默认情况为预期算法,可通过内核参数elevator进行再设置。系统管理员也可通过sysfs特殊文件系统动态的调整某个块设备的I/O调度算法。预期算法是最复杂的,演变自最后期限算法,该算法维护四个队列,两个最后期限排序队列和两个扇区排序队列,两种队列包含的读写请求是一样的,默认情况是优先处理扇区排序队列,当最后期限队列中某个请求超时了则优先处理该请求,从请求被传给I/O调度算法开始计时,读请求默认超时时间是125ms,写请求默认超时时间是250ms,这样处理是为了避免扇区排序的请求因排序靠后而饿死。
块设备驱动程序是Linux块子系统中的最底层组件,从I/O调度中获取待处理请求,然后发送合适的命令给磁盘控制器完成数据读写请求。一个块设备驱动程序可能处理多个块设备,每个磁盘分区都被看做是一个单独的块设备,块设备用block_device结构表示。当内核收到一个打开内核块设备文件的请求时,会通过bdev特殊文件系统判断内存中是否存在对应的块设备描述符,如果存在则更新,否则创建一个新的描述符。
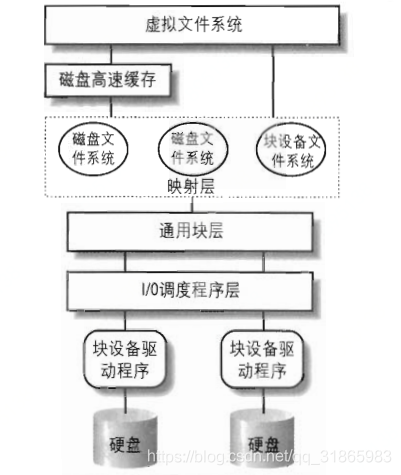
以read()系统调用为例,从应用程序执行系统调用到底层磁盘读取数据执行的过程如下图:
三、实践内容与截图,代码链接
- 在c语言编程中我们常会遇到和scanf()相关的缓冲区的问题。
- 比较常见的是使用scanf获取字符时常常读取到的不是想要的字符,如下面的一段代码:
#include<stdio.h>
int main(){
int choice;
char c;
scanf("%d",&choice);
scanf("%c",&c);
printf("你的第%d个选择是%c",choice,c);
printf("right");
}
实验截图如下:
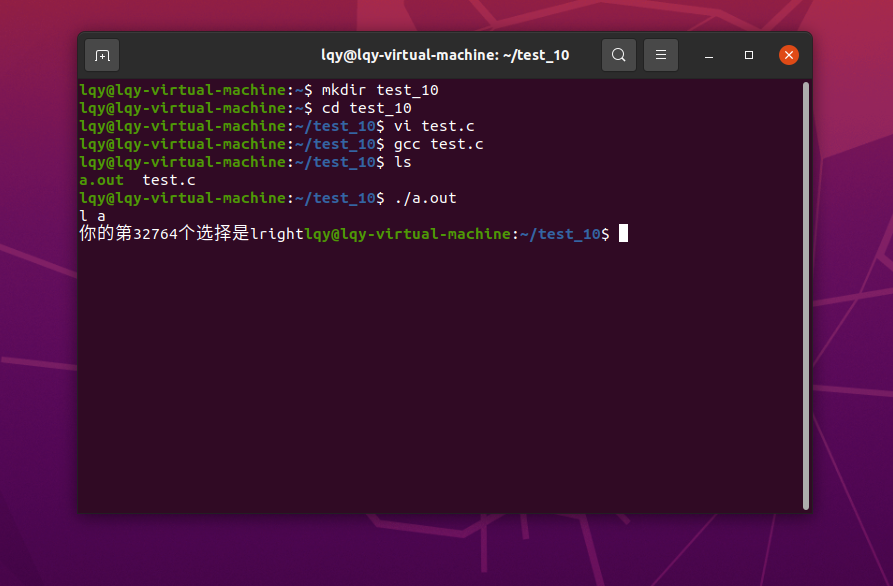
都没有得到想输出的结果,这是因为scanf读取字符时把空格,换行符等全部当成了字符处理,存在缓冲区队列。有时候不小心点了空格或换行就会导致运行结果与预期不一样。
想要避免只需要在读取字符时清空缓冲区队列或者用其他变量去存放空格或换行符。
如:
fflush(stdin); //在每次使用scanf接收字符时,清空输入缓冲区
setbuf(stdin,NULL);//将输入缓冲区禁用
while(buf=getchar())!=EOF&&buf!='\n');//用其他变量接收垃圾数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号