linux配置hadoop伪集群
准备:使用版本 hadoop-2.8.1.tar.gz jdk-8u131-linux-x64.tar.gz
上传至opt路径下,解压压缩包
tar -zxvf 压缩包
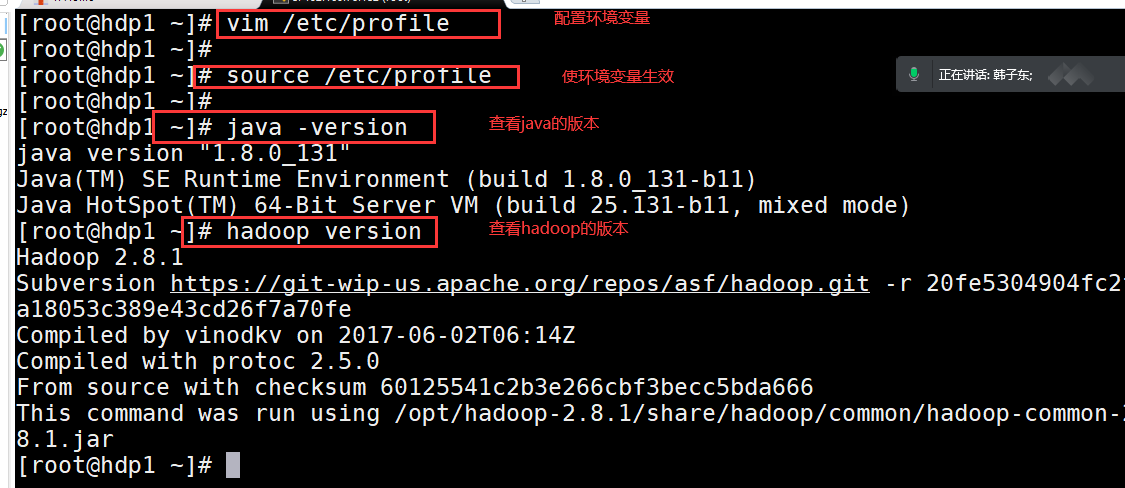
配置环境变量 vim /etc/profile 将下面内容添加到底部,配置完成后输入source /etc/profile 使配置文件生效
export JAVA_HOME=/opt/jdk1.8.0_131 export HADOOP_HOME=/opt/hadoop-2.8.1 export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
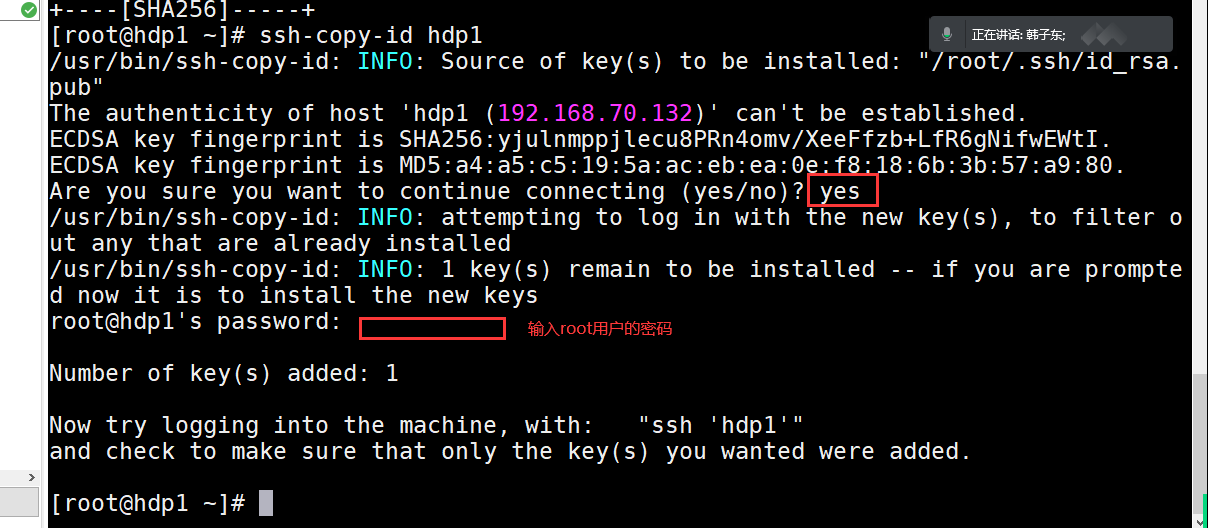
设置免密登录
ssh-keygen -t rsa
ssh-copy-id hdp1 ( hdp1 为虚拟机名称) 或者 cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
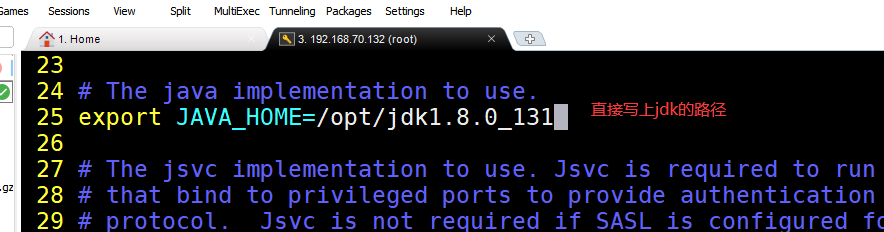
进入hadoop的配置文件目录下 cd /opt/hadoop-2.8.1/etc/hadoop
在core-site.xml中粘贴
<!-- 指定HADOOP所使用的文件系统,hdfs的namenode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hdp1:8020</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录,hadoop的工作目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/hadoop-2.8.1/tmp</value>
</property>
<!-- 支持hiveserver2 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
在hdfs-site.xml中粘贴
<!--指定hdfs副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
mv mapred-site.xml.template mapred-site.xml
在mapred-site.xml 中粘贴
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hdp1:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hdp1:19888</value>
</property>
在yarn-site.xml中配置
<!-- 指定yarn的ResourceManager的地址-->
<property>
<name>yarn.resoucemanager.hostname</name>
<value>hdp1</value>
</property>
<!-- reducer获取数据的方式,数据调度机制(分组等操作) -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 内存优化防止内存溢出 -->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx1024m</value>
</property>
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hdp1:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
格式化hadoop
hadoop namenode -format
hadoop的启动和关闭 ,在任意位置都可以
启动hadoop
start-dfs.sh
关闭hadoop
stop-dfs.sh
jps查看进程,如下图则启动成功
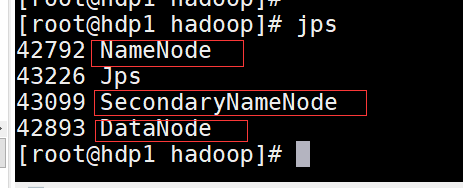
我有一杯酒,足以慰风尘。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号