Clickhouse 核心概念
参考 核心概念
Table Parts
Part 是磁盘上存储表部分数据的物理文件(或目录)。这与分区不同,分区是使用分区键创建的表数据的逻辑划分。MergeTree 引擎系列中每个表的数据都是以不可变的 data parts 保存。
下图展示了一个 data part 的产生过程:
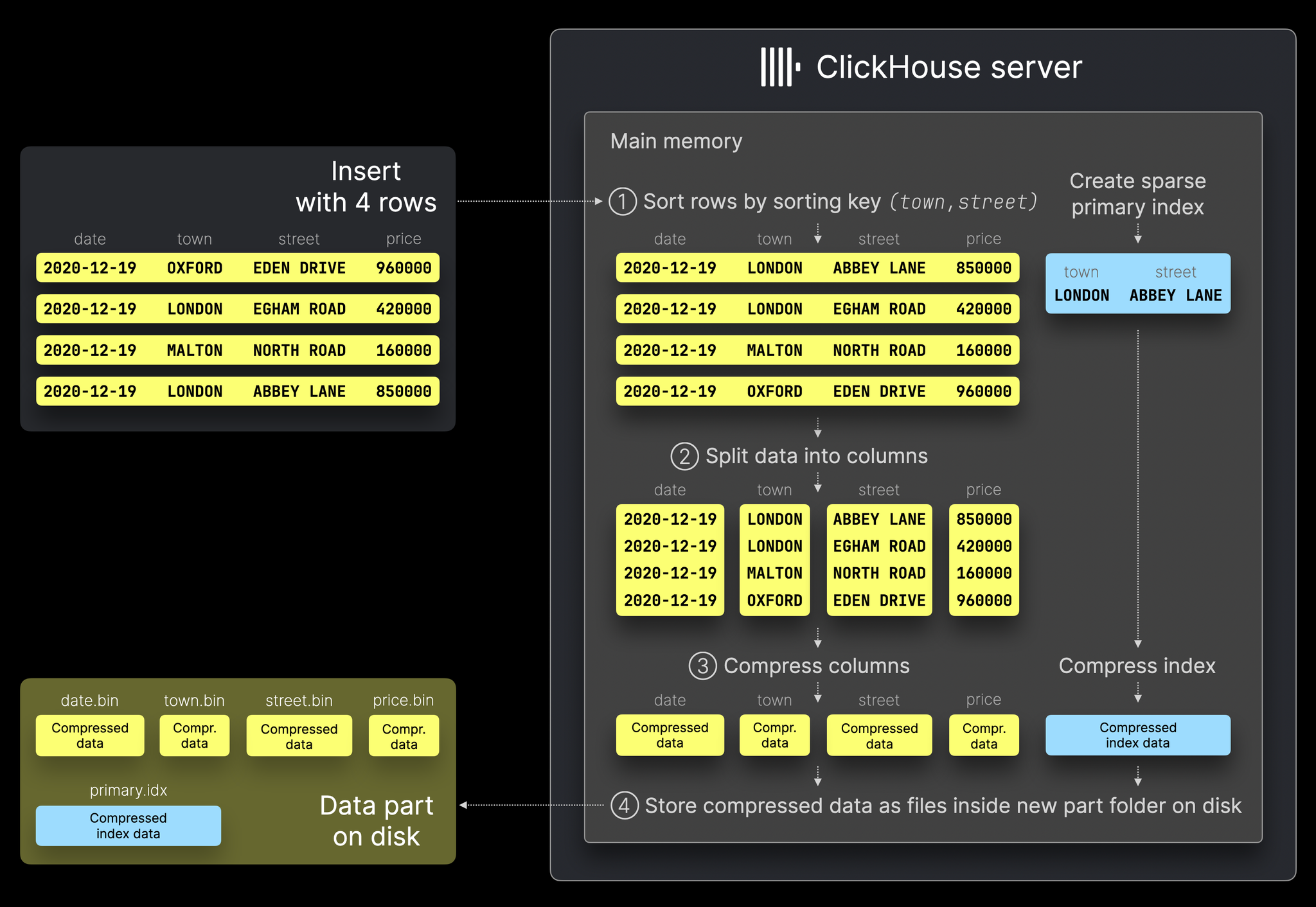
data part 的产生经历4个步骤:
① 排序:根据表格的排序键对行进行排序在 ClickHouse 中,排序键定义了磁盘上行的物理顺序。如果不指定主键,ClickHouse 就会使用排序键作为主键。如果同时指定两个主键,主键必须是排序键的前缀。 (town, street) ,并为排序行生成稀疏主索引。
② 分割:将排序后的数据拆分成列。
③ 压缩:对每一列进行压缩。
④ 写入磁盘:压缩列以二进制列文件形式保存在代表插入数据部分的新目录中。稀疏主索引也会被压缩并保存在同一目录中。
问题1. Part 目录下有哪些文件?
- 列数据文件 [column_name].bin
- 列标记文件 [column_name].mrk2
- 主索引文件 primary.idx
- 分区文件 partition.dat 存储该 Part 属于哪个分区(partition)的值
- 排序键 sorting.key
- 校验文件 checksums.txt 包含该 Part 目录下所有文件的校验和,用于确保数据的完整性和正确性。
- 计数文件 count.txt 一个简单的文本文件,记录了这个 Part 中包含多少行数据。
- 其他元数据文件 columns.txt(列定义),default_compression_codec.txt 等
问题2. Partition 与 Part 的关系?
- 每一个逻辑分区(Partition)会对应磁盘数据目录下的一个或多个 Part 目录。
- 在同一个分区下的所有 Parts,它们的目录名中会包含同一个分区名称。
Part Merges
后台 merge 任务会定期合并较小的 part 直到达到可配置的压缩大小上限(通常150 GB),被合并的 Parts 标记为不活跃,并在可配置的时间间隔后删除。
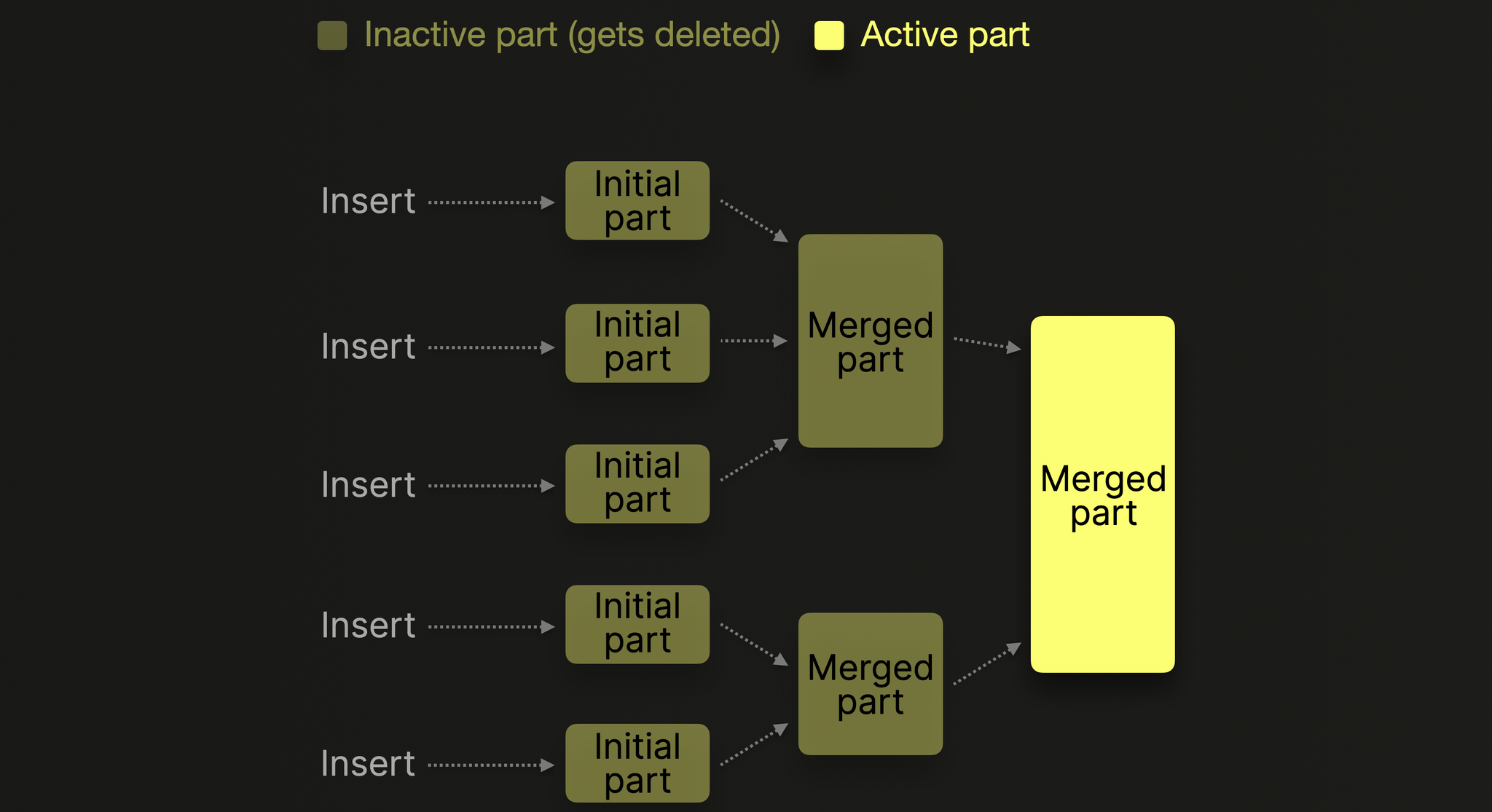
Table partitions
Partition 用于将 data parts 分组为有组织的逻辑单元。
示例:
CREATE TABLE uk.uk_price_paid_simple_partitioned
(
date Date,
town LowCardinality(String),
street LowCardinality(String),
price UInt32
)
ENGINE = MergeTree
ORDER BY (town, street)
PARTITION BY toStartOfMonth(date);
每当向表中插入一组行时,ClickHouse 为插入行中每个唯一的分区键值创建一个新的 data part。

注:
① ClickHouse 服务器首先根据分区键值 toStartOfMonth(date),将上图中包含 4 行的插入示例中的行进行拆分。然后,对于每个已识别的分区,通过执行几个连续步骤(①排序;②拆分为列;③压缩;④写入磁盘),对行进行常规处理。
② 启用分区后,ClickHouse 会自动为每个 data part 创建 MinMax 索引。这些索引是针对分区键表达式中使用的每个列生成的文件,其中包含该列在 data part 内的最小值和最大值。
③ 启用分区后,ClickHouse 只能合并分区内的数据部分,而不能跨分区合并。
Table partition 的应用
1. 自动删除旧数据,使主表中只保留最近 12 个月的数据
满足 TTL 条件的整个分区( table parts 的集合)将被丢弃,从而使清理操作更有效率。
CREATE TABLE uk.uk_price_paid_simple_partitioned
(
date Date,
town LowCardinality(String),
street LowCardinality(String),
price UInt32
)
ENGINE = MergeTree
PARTITION BY toStartOfMonth(date)
ORDER BY (town, street)
TTL date + INTERVAL 12 MONTH DELETE;
2. 将旧数据转移到更具成本效益的存储层
CREATE TABLE uk.uk_price_paid_simple_partitioned
(
date Date,
town LowCardinality(String),
street LowCardinality(String),
price UInt32
)
ENGINE = MergeTree
PARTITION BY toStartOfMonth(date)
ORDER BY (town, street)
TTL date + INTERVAL 12 MONTH TO VOLUME 'slow_but_cheap';
另参考 存储层实现热/温/冷架构
3. 优化查询效率
分区可以帮助提高查询性能,但这在很大程度上取决于访问模式。如果查询只针对几个分区(最好是一个),性能可能会有所提高。通常,只有当分区键不在主键中,并且要通过它进行筛选时,这种方法才有用。
示例:
SELECT MAX(price) AS highest_price
FROM uk.uk_price_paid_simple_partitioned
WHERE date >= '2020-12-01'
AND date <= '2020-12-31'
AND town = 'LONDON';
ClickHouse 通过应用一系列剪枝技术来处理该查询,以避免评估不相关的数据:
① 分区剪枝 :MinMax 索引用于忽略逻辑上无法匹配查询对表分区键中使用的列的筛选的整个分区(parts 集合)。
② Granule 剪枝 :对于经过步骤①后剩余的数据部分,使用其主索引来忽略那些在逻辑上不可能匹配查询中表主键所涉及列的过滤条件的 granule(行块)。

Primary Indexes
ClickHouse 将数据以列式文件的形式存储在磁盘上,这些列数据文件通常以 .bin 为扩展名,每个列对应一个文件。数据会按照主键进行排序并压缩。在处理过程中,每一列的数据被逻辑地划分为称为 granules 的单元,每个 granule 默认包含最多 8192 行数据,这是 ClickHouse 查询执行时读取的最小数据单位。
这种 granule 结构支持了主索引的稀疏性:ClickHouse 并非为每一行建立索引,而是为每个 granule 存储一个索引项,通常记录该 granule 中第一行的主键值。因此,主索引是稀疏的,它不指向单个行,而是标识可能包含匹配查询数据的 granules。由于其稀疏性,主索引体积很小,可以完全驻留在内存中,从而能够通过二分查找快速定位相关 granules,显著加速在主键上带有查询谓词的过滤操作。
列文件

主索引文件

通过主索引加速查询的过程:
① 示例查询包含针对两个主键列的谓词条件:town = 'LONDON' 且 street = 'OXFORD STREET'。
② 为加速查询,ClickHouse 会将表的主索引加载到内存中。
③ 接着扫描索引条目,识别可能包含匹配数据的 granule。
④ 随后,这些可能相关的 granule 连同查询所需其他列对应的 granule 一起被加载到内存中进行处理。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号