scala 中的集合类
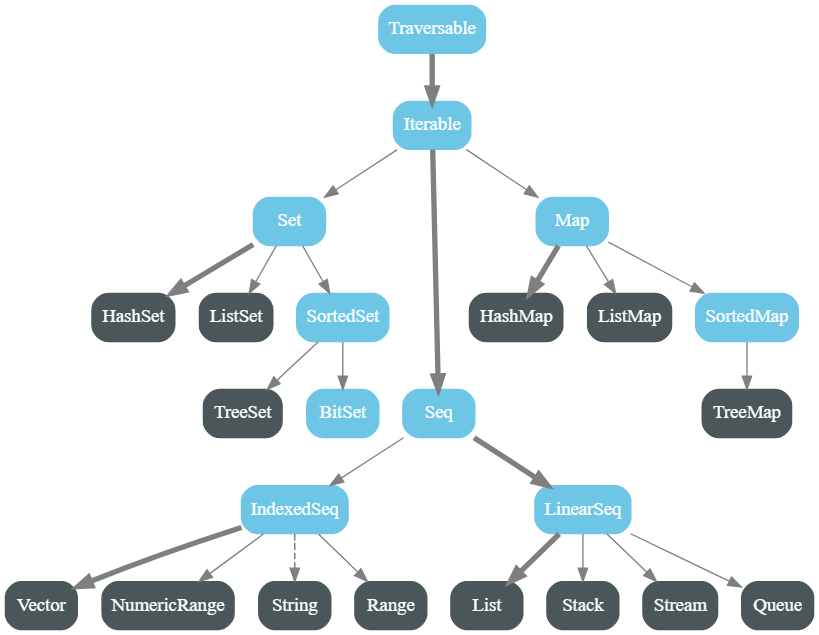
集合最重要的继承路线 —— Traversable -> Iterable -> Seq -> LinerSeq -> List
Traversable 中的公有方法:
| 分类 | 方法 |
| 相加操作 | ++ |
| 大小信息 | isEmpty,nonEmpty,size和hasDefiniteSize |
| 元素测试 | exists,forall和count |
| 元素检索 | head,last,headOption,lastOption和find |
| 转换操作 | toArray,toList,toIterable,toSeq,toIndexedSeq,toStream,toSet,和toMap |
| 构建新容器 | map, flatMap, collect, foldLeft,foldRight,/:,:\,reduceLeft |
| 子容器检索(返回子容器) | tail,init,slice,take,drop,takeWhilte,dropWhile,filter,filteNot和withFilter |
| 子容器拆分 | splitAt,span,partition和groupBy |
Iterable 中的公用方法
| 抽象方法 | xs.iterator |
| 其他迭代器 | xs grouped size,xs sliding size |
| 子容器(Subcollection) | xs takeRight n,xs dropRight n |
| 拉链方法(Zippers) | xs zip ys,xs zipAll (ys, x, y),xs.zip WithIndex |
| 比对 | xs sameElements ys |
序列 Seq
Seq trait用于表示序列。所谓序列,指的是一类具有一定长度的可迭代访问的对象。
序列的操作有以下几种,如下表所示:
- 索引和长度的操作 apply、isDefinedAt、length、indices,及lengthCompare。序列的apply操作用于索引访问;因此,Seq[T]类型的序列也是一个以单个Int(索引下标)为参数、返回值类型为T的偏函数。换言之,Seq[T]继承自Partial Function[Int, T]。序列各元素的索引下标从0开始计数,最大索引下标为序列长度减一。序列的length方法是collection的size方法的别名。lengthCompare方法可以比较两个序列的长度,即便其中一个序列长度无限也可以处理。
- 索引检索操作(indexOf、lastIndexOf、indexofSlice、lastIndexOfSlice、indexWhere、lastIndexWhere、segmentLength、prefixLength)用于返回等于给定值或满足某个谓词的元素的索引。
- 加法运算(+:,:+,padTo)用于在序列的前面或者后面添加一个元素并作为新序列返回。
- 更新操作(updated,patch)用于替换原序列的某些元素并作为一个新序列返回。
- 排序操作(sorted, sortWith, sortBy)根据不同的条件对序列元素进行排序。
- 反转操作(reverse, reverseIterator, reverseMap)用于将序列中的元素以相反的顺序排列。
- 比较(startsWith, endsWith, contains, containsSlice, corresponds)用于对两个序列进行比较,或者在序列中查找某个元素。
- 多集操作(intersect, diff, union, distinct)用于对两个序列中的元素进行类似集合的操作,或者删除重复元素。
如果一个序列是可变的,它提供了另一种更新序列中的元素的,但有副作用的update方法,Scala中常有这样的语法,如seq(idx) = elem。它只是seq.update(idx, elem)的简写,所以update 提供了方便的赋值语法。应注意update 和updated之间的差异。update 再原来基础上更改序列中的元素,并且仅适用于可变序列。而updated 适用于所有的序列,它总是返回一个新序列,而不会修改原序列。
Seq 具有两个子特征(subtrait) LinearSeq 和 IndexedSeq。它们不添加任何新的操作,但都提供不同的性能特点:线性序列具有高效的 head 和 tail 操作,而索引序列具有高效的apply, length, 和 (如果可变) update操作。
常用线性序列有 scala.collection.immutable.List和scala.collection.immutable.Stream。常用索引序列有 scala.Array scala.collection.mutable.ArrayBuffer。Vector 类提供一个在索引访问和线性访问之间有趣的折中。它同时具有高效的恒定时间的索引开销,和恒定时间的线性访问开销。正因为如此,对于混合访问模式,vector是一个很好的基础。
缓冲器
Buffers是可变序列一个重要的种类。它们不仅允许更新现有的元素,而且允许元素的插入、移除和在buffer尾部高效地添加新元素。buffer 支持的主要新方法有:用于在尾部添加元素的 += 和 ++=;用于在前方添加元素的+=: 和 ++=: ;用于插入元素的 insert和insertAll;以及用于删除元素的 remove 和 -=。如下表所示。
ListBuffer和ArrayBuffer是常用的buffer实现 。顾名思义,ListBuffer依赖列表(List),支持高效地将它的元素转换成列表。而ArrayBuffer依赖数组(Array),能快速地转换成数组。
映射
当你使用可变容器作为一个 hashmap 的键时,这将是一个潜在的陷阱
scala> import collection.mutable.{HashMap, ArrayBuffer}
import collection.mutable.{HashMap, ArrayBuffer}
scala> val buf = ArrayBuffer(1, 2, 3)
buf: scala.collection.mutable.ArrayBuffer[Int] =
ArrayBuffer(1, 2, 3)
scala> val map = HashMap(buf -> 3)
map: scala.collection.mutable.HashMap[scala.collection。
mutable.ArrayBuffer[Int],Int] = Map((ArrayBuffer(1, 2, 3),3))
scala> map(buf)
res13: Int = 3
scala> buf(0) += 1
scala> map(buf)
java.util.NoSuchElementException: key not found:
ArrayBuffer(2, 2, 3)
在这个例子中,由于数组xs的散列码已经在倒数第二行发生了改变,最后一行的选择操作将很有可能失败。因此,基于散列码的查找函数将会查找另一个位置,而不是xs所存储的位置。
233
https://www.scala-lang.org/files/archive/api/current/scala/collection/immutable/Iterable.html
https://docs.scala-lang.org/overviews/collections/introduction.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号