Presto 运行机制简介
一、Presto 执行过程
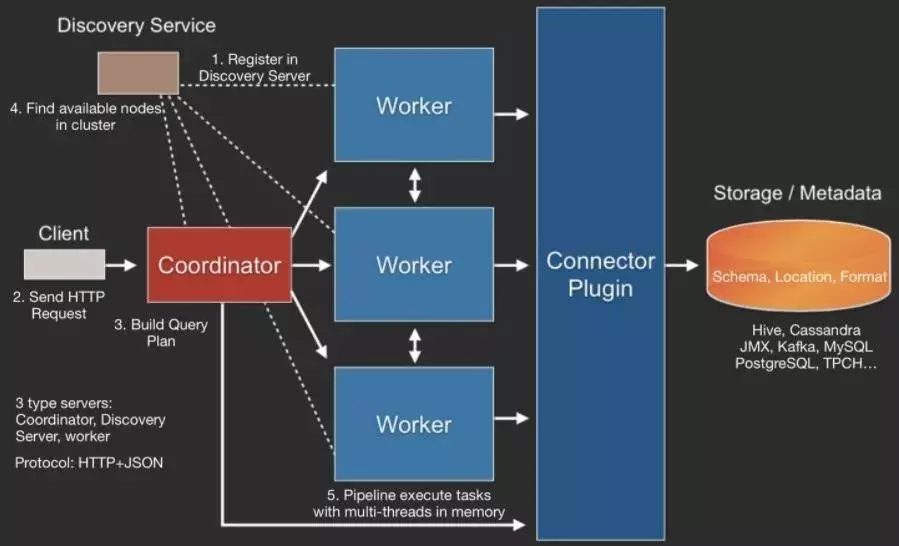
Presto 执行流程图
Presto 查询引擎是一个 Master-Slave 架构,主要包括:
- Client:提交数据操作的窗口
- Coordinator:负责解析 SQL 语句,生成执行计划,分发执行任务给 Worker 节点执行。
- Discovery Server:通常内嵌于 Coordinator 节点中,用于发现 Worker 节点,存储可用 Server(即 Worker)列表开。
- Connector Plugin:连接 Storag 元数据连接信息,支持 Hive、Kafka、MySQL 等数据源,可自定义。
- Worker 节点:负责实际执行查询任务,负责与 HDFS 交互读取数据。
查询流程如下:
- Client 使用 HTTP 协议发送一个 query 请求。
- 通过 Discovery Server 发现可用的 Server。
- Coordinator 构建查询计划(通过 Anltr3 解析为 AST(抽象语法树),然后通过 Connector 获取原始数据的 Metadata 信息,生成分发计划和执行计划)。
- Coordinator 向 Worker 发送任务。
- Worker 通过 Connector 插件读取数据。
- Worker 在内存里执行任务(Worker 是纯内存型计算引擎)。
- Worker 将数据返回给 Coordinator,汇总之后再响应客户端。
二、Presto不足
通过 Presto 执行流程的架构,可以看出 Presto 在查询上也存在一些不足:
- 没有容错能力,当一个 query 分发到多个 Worker 去执行时,当有一个 Worker 因为各种原因查询失败,Master 感知到之后,整个 query 也会失败。
- 内存限制,由于 Presto 是纯内存计算,所以当内存不够时,Presto 并不会将结果 dump 到磁盘上,所以查询也就失败了。
- 并行查询,因为所有的 task 都是并行执行,如果其中一台 Worker 因为各种原因查询很慢,那么整个 query 就会变得很慢。
- 并发限制,因为全内存操作+内存限制,能同时处理的数据量有限,因而导致并发能力不足。
【参考资料】

 浙公网安备 33010602011771号
浙公网安备 33010602011771号