Spark 内存管理模型详解
一、Spark 内存介绍
在执行 Spark 的应用程序时,Spark 集群会启动 Driver 和 Executor 两种JVM进程。
Driver 程序主要负责:
- 创建 Spark上下文;
- 提交 Spark作业(Job)并将 Job 转化为计算任务(Task)交给 Executor 计算;
- 协调各个 Executor 进程间任务调度。
Executor 程序主要负责:
- 在工作节点上执行具体的计算任务(Task),并将计算结果返回给 Driver;
- 为需要持久化的 RDD 提供存储功能。
由于 Driver 的内存管理相对来说较为简单,本文主要对 Executor 的内存管理进行分析,下文中的 Spark 内存均特指 Executor 的内存。
二、Executor 内存管理
Executor 进程作为一个 JVM 进程,其内存管理建立在 JVM 的内存管理之上,整个大致包含两种方式:堆内内存和堆外内存。
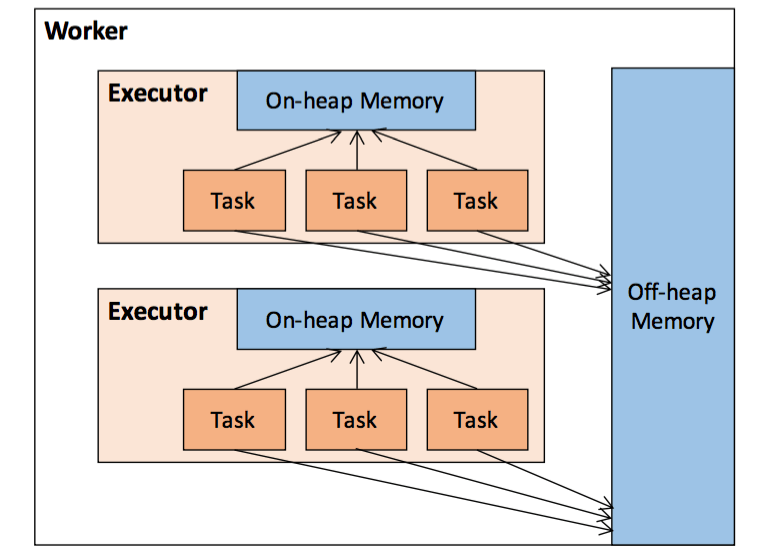
spark.memory.offHeap.enabled=true # 开启堆外内存 spark.memory.offHeap.size =1024 # 分配堆外内存的大小
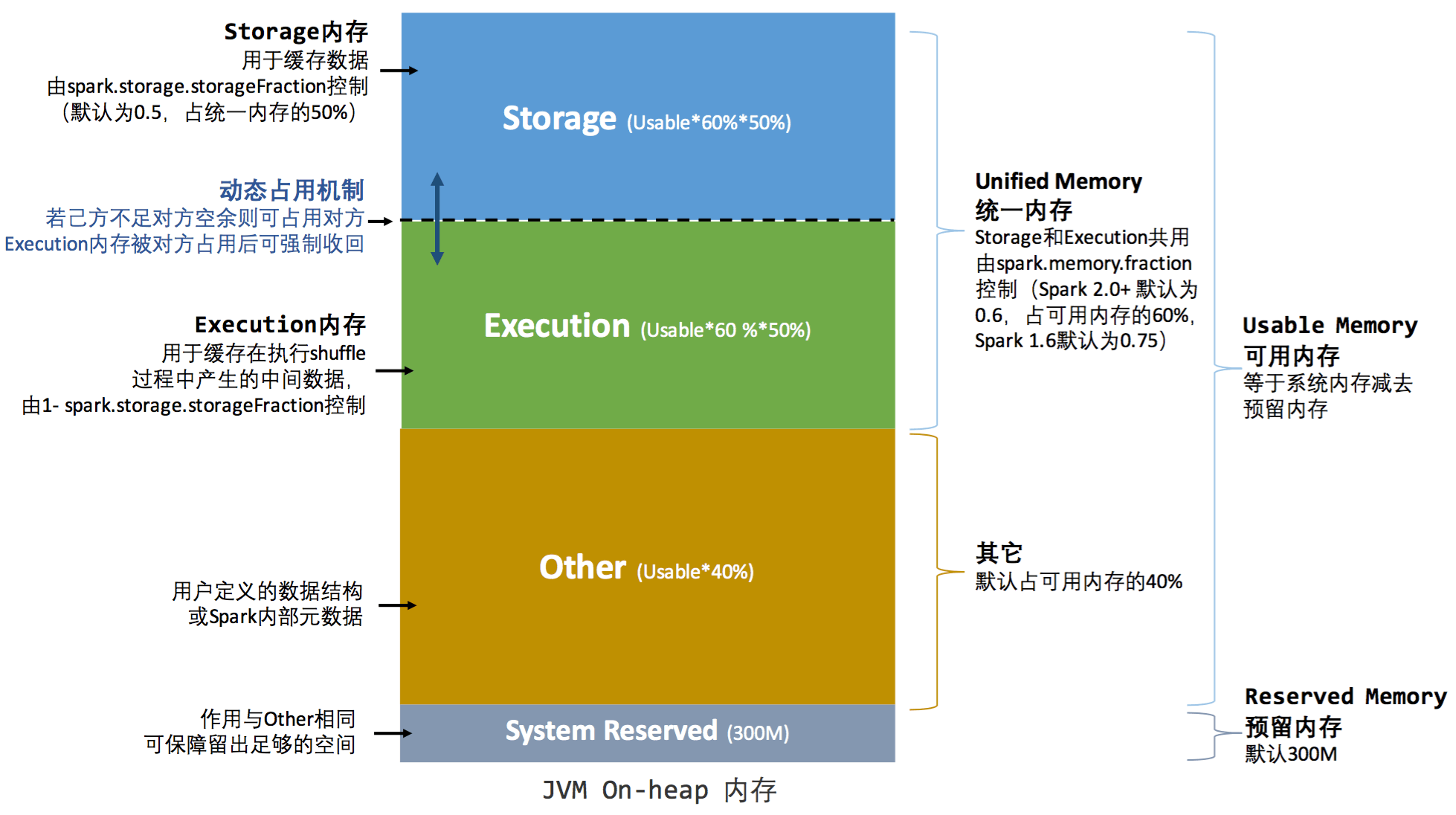
2.1 堆内内存
- Spark 在代码中 new 一个实例对象。
- JVM 从堆内内存分配空间,创建对象并返回对象饮用。
- Spark 保存该对象的引用,记录该对象占用的内存。
- Spark 记录该对象释放的内存,删除该对象的引用。
- 等待 JVM 的垃圾回收机制释放该对象占用的堆内内存。
- Storage 内存:主要用于存储 Spark 的 cache 数据,例如 RDD 的 cache,Broadcast 变量,Unroll 数据等。需要主要的是,unrolled 的数据如果内存不够,会存储在 driver 端。
- Execution 内存:用于存储 Spark task 执行过程中需要的对象,如 Shuffle、Join、Sort、Aggregation等计算过程中的临时数据。
- User 内存:分配 Spark Memory 剩余的内存,用户可以根据需要使用,可以存储 RDD transformations 需要的数据结构。
- Reserved 内存:这部分内存是预留给系统用的,固定不变。
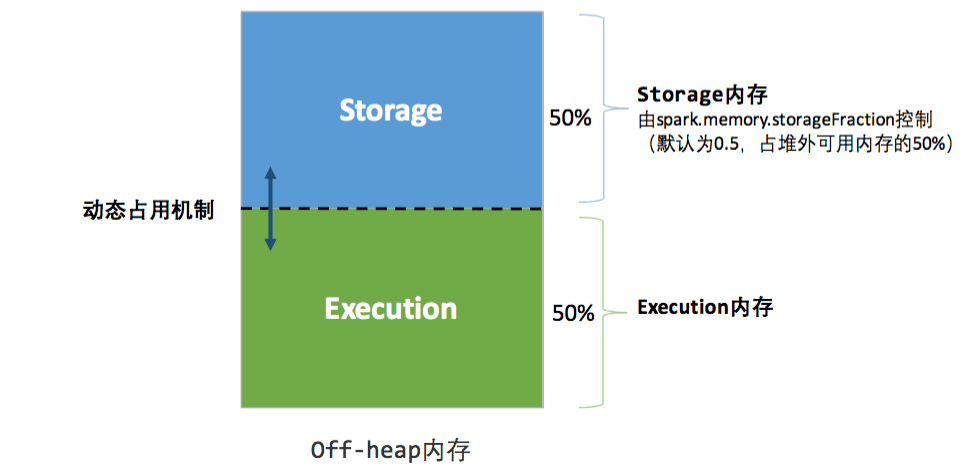
2.2 堆外内存
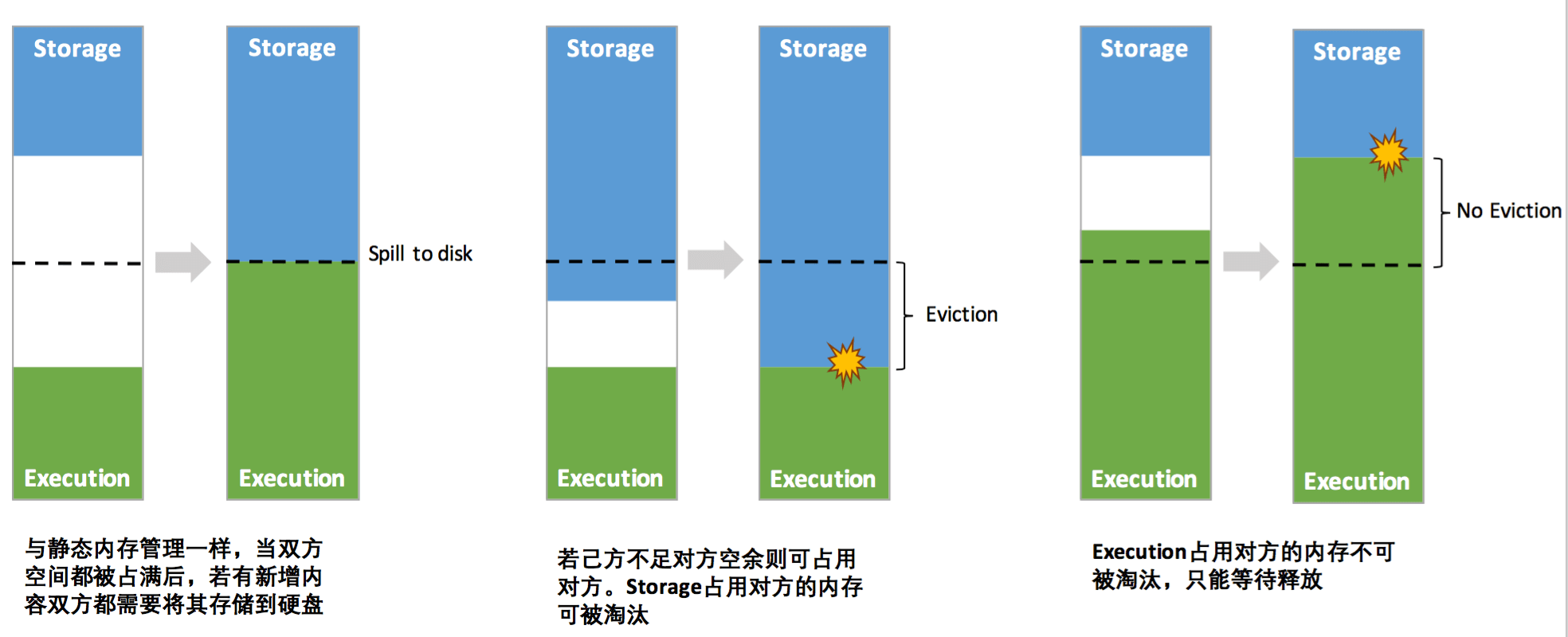
三、统一内存管理机制
- 双方空间都不足时,则存储到硬盘;如己方空间不足而对方空余时,可借用对方的空间;(存储空间不足是指不足以放下一个完整的 Block)。
- 执行内存的空间被对方占用后,可让对方将占用的部分存储转存到硬盘,然后“归还”借用的空间。
- 存储内存的空间被对方占用后,无法让对方“归还”,因为需要考虑到 Shuffle 过程中很多因素,实现起来较为复杂。
四、Spark 内存参数
4.1 统一内存管理参数
参数:spark.memory.fraction 含义:用于执行和存储的部分(堆空间-300MB)。值越低,溢出和缓存数据逐出的频率就越高。此配置的目的是为稀疏的,异常大的记录留出用于内部元数据,用户数据结构和大小估计不精确的内存。建议将其保留为默认值。 默认值:0.6 (Spark 1.6 默认为 0.75,Spark 2.0+ 默认为 0.6) 参数:spark.memory.storageFraction 含义:可以逐出的存储内存量,以spark.memory.fraction预留的区域大小的一部分表示。数值越高,则可用于执行的工作内存就越少,任务可能会更频繁地溢出到磁盘上. 建议将其保留为默认值。 默认值:0.5 参数:spark.memory.offHeap.enabled 含义:如果为true,Spark将尝试将堆外内存用于某些操作。如果启用了堆外内存使用,则spark.memory.offHeap.size必须为正。 默认值:false 参数:spark.memory.offHeap.size 含义:可用于堆外分配的绝对内存量(以字节为单位)。此设置对堆内存使用没有影响,因此,如果执行者的总内存消耗必须在某个硬限制内,那么请确保相应地缩小JVM堆大小。当spark.memory.offHeap.enabled=true时,必须将此值设置为正值. 默认值:0 参数:spark.memory.useLegacyMode 含义:是否启用Spark 1.5及之前版本中使用的旧版内存管理模式。传统模式将堆空间严格划分为固定大小的区域,如果未调整应用程序,则可能导致过多的溢出. 除非已启用,否则不会读取以下不推荐使用的内存分数配置: spark.shuffle.memoryFraction、spark.storage.memoryFraction、spark.storage.unrollFraction 默认值:false 参数:spark.shuffle.memoryFraction 含义:(不建议使用)仅在启用spark.memory.useLegacyMode读。在 shuffle 期间用于聚合和协同分组的Java堆的分数。在任何给定时间,用于随机播放的所有内存映射的集合大小都受到此限制的限制,超出此限制,内容将开始溢出到磁盘。如果经常发生泄漏,请考虑以spark.storage.memoryFraction为代价增加此值. 默认值:0.2 参数:spark.storage.memoryFraction 含义:(不建议使用)仅在启用spark.memory.useLegacyMode读。用于Spark的内存缓存的Java堆的分数。这不应大于JVM中对象的"旧"代,默认情况下,该对象的堆大小为0.6,但是如果您配置自己的旧代大小,则可以增加它。 默认值:0.6 参数:spark.storage.unrollFraction 含义:(不建议使用)仅在启用spark.memory.useLegacyMode读。spark.storage.memoryFraction分数,用于展开内存中的块。当没有足够的可用存储空间来完全展开新块时,通过删除现有块来动态分配该块。 默认值:0.2
4.2 内存参数示例
spark-submit \ --master yarn \ --deploy-mode client \ --executor-memory 18g \ --queue root.exquery \ --class org.apache.spark.examples.SparkPi \ /opt/cloudera/parcels/CDH/lib/spark/examples/lib/spark-examples-1.6.0-cdh5.14.4-hadoop2.6.0-cdh5.14.4.jar \ 100
Spark UI 页面显示的内存情况:

可以看出,Storage Memory 的可用内存是 10 GB,这个数咋来的呢?根据前面的内存规则,可以得出以下计算:
systemMemory = spark.executor.memory reservedMemory = 300MB usableMemory = systemMemory - reservedMemory StorageMemory= usableMemory * spark.memory.fraction * spark.memory.storageFraction
代入数据,可以得出以下结果:
systemMemory = 18Gb = 19327352832 字节 reservedMemory = 300MB = 300 * 1024 * 1024 = 314572800 usableMemory = systemMemory - reservedMemory = 19327352832 - 314572800 = 19012780032 StorageMemory= usableMemory * spark.memory.fraction * spark.memory.storageFraction = 19012780032 * 0.6 * 0.5 = 5703834009.6 = 5.312109375GB
结果和 Spark UI 界面展示的 10GB 差不多有一般的差距,这是因为 Spark UI 上显示的 Storage Memory 可用内存其实等于 Storage 内存和 Execution 内存之和,也就是 usableMemory * spark.memory.fraction。
StorageMemory= usableMemory * spark.memory.fraction * spark.memory.storageFraction = 19012780032 * 0.6 / (1024 * 1024 * 1024) = 10.62421 GB
这个结果和 Spark UI 上看到的结果还是有点出入,为什么呢?这是因为虽然我们设置了 --executor-memory 18g,但是 Spark 的 Executor 端通过 Runtime.getRuntime.maxMemory 拿到的内存其实没这么大,只有 17179869184 字节,所以 systemMemory = 17179869184,然后计算的数据如下:
systemMemory = 17179869184 字节 reservedMemory = 300MB = 300 * 1024 * 1024 = 314572800 usableMemory = systemMemory - reservedMemory = 17179869184 - 314572800 = 16865296384 StorageMemory= usableMemory * spark.memory.fraction = 16865296384 * 0.6 /(1024 * 1024 * 1024) = 9.42421 GB
我们通过将上面的 16865296384 * 0.6 字节除于 1024 * 1024 * 1024 转换成 9.42421875 GB,和 UI 上显示的还是对不上,这是因为 Spark UI 是通过除于 1000 * 1000 * 1000 将字节转换成 GB,如下:
systemMemory = 17179869184 字节 reservedMemory = 300MB = 300 * 1024 * 1024 = 314572800 usableMemory = systemMemory - reservedMemory = 17179869184 - 314572800 = 16865296384 StorageMemory= usableMemory * spark.memory.fraction = 16865296384 * 0.6 字节 = 16865296384 * 0.6 / (1000 * 1000 * 1000) = 10.1GB
systemMemory 内存之所以为 17179869184(可以通过方法 Runtime.getRuntime.maxMemory( ) 获得该值),是因为内存分配池的堆部分分为 Eden,Survivor 和 Tenured 三部分空间,而这里面一共包含了两个 Survivor 区域,而这两个 Survivor 区域在任何时候我们只能用到其中一个,所以我们可以使用下面的公式进行描述:
ExecutorMemory = Eden + 2 * Survivor + Tenured Runtime.getRuntime.maxMemory = Eden + Survivor + Tenured
上面的 17179869184 字节可能因为 GC 配置不一样得到的数据不一样,但是上面的计算公式是一样的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号