定时任务
JDK定时器
理论基础
小顶堆
像下面的Timer和定时任务线程池,底层都是小顶堆的结构。
堆是特殊的树,满足下面两个条件就是一个小顶堆:
- 是一颗完全二叉树
- 堆中的某个节点的值总是不大于其父节点的值
插入元素(定时任务):插入尾部,逐步上浮(与父节点比较,进行交换)
删除堆顶元素(执行定时任务):将尾部(最大的元素)放到堆顶,逐步下沉(与子节点比较,进行交换)
时间轮算法
小顶堆只适合相近时间内的小量任务,当执行时间相差过大或任务量很大时,添加新任务或执行堆顶任务时堆化的性能很低。
像Quartz或者其他复杂的定时任务框架,底层更多地会使用时间轮算法。
链表+数组实现
while-true-sleep;遍历数组,每个下标建立一个链表,链表节点中存储任务,遍历到就取出执行。
比如数组的长度为24,每一个数组元素中存储执行任务的链表,相对小顶堆性能有了很大提升,但依然存在问题,比如想在每个月的1号执行任务就不好实现,不够灵活。
round型时间轮
任务上记录一个round值,遍历到便将round值减1,为0时取出执行。
比如数组的长度为24,每个数组元素中存储执行任务的链表,链表节点中除了存储任务,还存储了round值,比如明天的任务就可以设置round为1,当第二遍遍历到时便可取出执行。
存在问题:每次需要遍历所有的任务,效率较低
分层时间轮
使用多个不同时间维度的轮:
- 天轮:记录几点执行
- 月轮:记录几号执行
月轮中匹配当前日期,若存在任务,就到天轮中遍历任务执行,达到几号几点执行任务的需求。
像Linux中定时任务的cron表达式就是典型的分层时间轮
Timer
Timer类中有几个属性需要注意:
//小顶堆,存放timeTask
private final TaskQueue queue = new TaskQueue();
//任务执行线程;死循环不断检查是否有任务需要执行
private final TimerThread thread = new TimerThread(queue);
特点:
- 单线程执行任务,任务可能相互阻塞
- 运行时异常会导致timer线程终止
- 任务调度时基于绝对时间的,对系统时间敏感
使用实例:
public class TimeTest {
public static void main(String[] args) {
// 这里定时任务就已经启动了,但是队列中没有任务,所以一直等待
Timer timer = new Timer();
for (int i = 0; i < 2; i++) {
// 添加任务
// timer.schedule(new MyTimerTask("task" + i), 0, 2000);
timer.scheduleAtFixedRate(new MyTimerTask("task" + i), 0, 2000);
}
}
}
class MyTimerTask extends TimerTask {
private String name;
public MyTimerTask(String name) {
this.name = name;
}
@Override
public void run() {
try {
System.out.println(name + "执行时间:" + new Date());
Thread.sleep(1000);
System.out.println(name + "结束时间:" + new Date());
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
schedule与scheduleAtFixedRate异同:
相同点:
任务执行未超时,下次执行时间 = 上次执行开始时间 + period;
任务执行超时,下次执行时间 = 上次执行结束时间;
在任务执行未超时时,它们都是上次执行时间加上间隔时间,来执行下一次任务。而执行超时时,都是立马执行。
区别点:
schedule侧重保持间隔时间的稳定。
schedule 执行任务超时,第N个任务会在 N-1个任务执行完成后,不做period等待,立即启动执行;N任务执行未超时,N+1个任务会在N任务执行完成后,等待period,再执行。
即:schedule侧重时间间隔的稳定,错过了就错过了,后续按照新的节奏走。
scheduleAtFixedRate侧重保持执行频率的稳定。
scheduleAtFixedRate在任务执行超时后,不错period等待,立即执行下一个任务。并且后续任务会根据超时时长,不做period等待,立即执行后续的任务,直到追上设定的节奏后,再进行period等待执行后续任务。
即:scheduleAtFixedRate侧重的是频率的稳定,如果错过了,就取消period等待,努力追上设定好的节奏。
定时任务线程池
ScheduledThreadPoolExecutor:
-
使用多线程执行任务,不会相互阻塞
-
如果线程失活,会创建新线程执行任务。(线程抛异常,任务会被丢弃,需要做捕获处理)
-
DalayedWorkQueue:小顶堆,无界队列
-
在定时线程池中,最大线程数是没有意义的,核心线程数才有意义
-
执行时间距离当前时间越近的任务在队列的前面
-
用于添加ScheduleFutureTask(继承于FutureTask,实现RunnableScheduledFuture接口)
- 提供异步执行的能力,并且可以返回执行时间
-
线程池中的线程从DelayQueue中获取ScheduleFutureTask,然后执行任务
-
实现了Delayed接口,可以通过getDelay方法获取延迟时间
-
-
Leader-Follower模式
- 避免没必要的唤醒和阻塞的操作,节省资源
在Leader-follower线程模型中每个线程有三种模式,leader,follower, processing。
在Leader-follower线程模型一开始会创建一个线程池,并且会选取一个线程作为leader线程,leader线程负责监听网络请求,其它线程为follower处于waiting状态,当leader线程接受到一个请求后,会释放自己作为leader的权利,然后从follower线程中选择一个线程进行激活,然后激活的线程被选择为新的leader线程作为服务监听,然后老的leader则负责处理自己接受到的请求(现在老的leader线程状态变为了processing),处理完成后,状态从processing转换为follower
SingleThreadScheduledExecutor:
-
单线程的ScheduledThreadPoolExecutor
public static ScheduledExecutorService newSingleThreadScheduledExecutor() { return new DelegatedScheduledExecutorService (new ScheduledThreadPoolExecutor(1)); }
使用示例:
public class ScheduleThreadPoolTest {
public static void main(String[] args) {
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(1);
for (int i = 0; i < 2; i++) {
scheduledThreadPool.scheduleAtFixedRate(new MyTask("tesk-" + i), 0, 2, TimeUnit.SECONDS);
}
}
}
class MyTask implements Runnable {
private String name;
public MyTask(String name) {
this.name = name;
}
@Override
public void run() {
try {
System.out.println(name + "执行时间:" + new Date());
Thread.sleep(1000);
System.out.println(name + "结束时间:" + new Date());
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
//间隔是固定的,无论上一个任务是否完成
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,long initialDelay,long delay,TimeUnit unit);
//间隔是不固定的,其会在周期任务的上一个任务执行完成后再开始计时,并在指定时间间隔之后才开始执行任务
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,long initialDelay,long period,TimeUnit unit);
定时任务框架-Quartz
官网:Quartz Enterprise Job Scheduler (quartz-scheduler.org)
结构图:
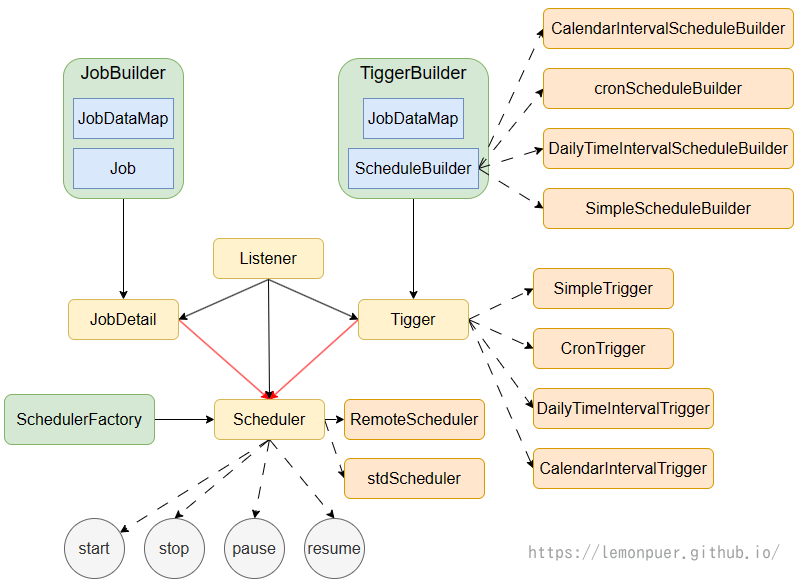
-
Job:封装为JobDetail设置属性
@DisallowConcurrentExecution:禁止并发地执行同一个job定义(JobDetail定义的)多个实例@PersistJobDataAfterExecution:持久化JobDetail中的JobDataMap(对Trigger中的DataMap无效)- 如果一个任务不是持久化的,则当没有触发器关联它时,Quartz会从scheduler中删除它
- 如果一个任务请求恢复,一般是该任务执行期间发生了系统奔溃或者其他关闭进程的操作,当服务再次启动的时候,会再次执行该任务,此时,
JobExercutionContext.isRecovering()会返回true
-
Trigger:触发器
-
优先级
- 同时触发的Trigger之间才会比较优先级
- 如果Trigger是可恢复的,在恢复后再调度时,优先级不变
-
misfire:错过触发-
判断条件:
- job到达触发时间时没有执行
- 被执行的延迟时间超过了Quartz配置的
misfire Threshold阈值
-
-
产生原因:
-
当job达到触发时间时,所有线程都被其他job占用,没有可用线程
- 再job需要触发的时间点,scheduler停止了
- job使用了
@DisallowConcurrentExecution注解,job不能并发执行,当达到了下一个job执行点时,上一个任务还未完成 - job指定了过去的开始执行时间,例如当前是8点,指定开始时间为7点
-
策略:默认都使用
MISFIRE_INSTRUCTION_SMART_POLICY;Quartz会根据Trigger的类型(SimpleTrigger或CronTrigger)和配置自动选择最合适的处理方式。-
SimpleTrigger:具体时间,指定间隔重复执行-
now*相关的策略,会立即执行第一个misfire的任务,同时会修改
startTime和repeatCount,导致会重新计算finalFireTime,打乱原计划 -
next*相关的策略,不会立即执行misfire的任务,补充执行
-
-
-
CronTrigger:cron表达式MISFIRE_INSTRUCTION_IGNORE_MISFIRE_POLICY:Trigger错过后忽略Misfire策略。例如当前时间是下午2点,而任务本应该在早上10点执行,Quartz框架会等待下一个触发时间,比如下午3点,然后执行任务。它不会考虑错过的10点触发时间,而是仅仅基于当前时间和下一个预定触发时间进行调度。MISFIRE_INSTRUCTION_FIRE_ONCE_NOW:Trigger错过后立即执行
MISFIRE_INSTRUCTION_DO_NOTHING:Trigger错过后不做任何处理
-
-
calendar:设置排除时间段
-
-
Scheduler:调度器,基于Trigger的设定执行Job
-
SchedulerFactory:
- 创建Scheduler
- DirectSchedulerFactory:在代码中定制Scheduler
- StdSchedulerFactory:读取classPah下的
quartz.properties文件来实例化Scheduler
-
JobStore:存储运行时信息,包括Trigger、Schduler、JobDetail、业务锁等
-
RAMJobStore(内存实现)
-
JobStoreTX(JDBC,事务由Quartz管理)
-
JobStoreCMT(JDBC,使用容器事务)
-
ClusteredJobStore(集群实现)
-
TerracottaJobStore(Terracotta中间件)
-
-
ThreadPool
- SimpleThreadPool
- 自定义线程池
-
-
JobDataMap:保存任务实例的状态信息
- JobDetail:默认旨在Job被添加到调度程序(任务执行计划表)scheduler的时候,存储一次关于该任务的状态信息数据,可以使用注解
@PersistJobDataAfterExecution注解标明在一个任务执行完毕之后就存储一次 - Trigger:任务被多个触发器引用的时候,根据不同的触发时机,可以提供不同的输入条件
- JobDetail:默认旨在Job被添加到调度程序(任务执行计划表)scheduler的时候,存储一次关于该任务的状态信息数据,可以使用注解
简单使用:
@PersistJobDataAfterExecution
public class MyJob implements Job {
private String name;
public void setName(String name) {
this.name = name;
}
@Override
public void execute(JobExecutionContext context) throws JobExecutionException {
// 判断是否是恢复执行的任务
boolean recovering = context.isRecovering();
// 获取各自存储的数据
JobDataMap jobDataMap = context.getJobDetail().getJobDataMap();
JobDataMap triggerMap = context.getTrigger().getJobDataMap();
JobDataMap mergedMap = context.getMergedJobDataMap();
// 框架自动调用set方法,结果为 trigger
System.out.println("name:" + name);
// 1
System.out.println("jobDataMap:" + jobDataMap.get("count"));
jobDataMap.put("count", jobDataMap.getIntValue("count") + 1);
// 2
System.out.println("mergedMap:" + mergedMap.get("count"));
}
}
public class quartzTest {
public static void main(String[] args) throws SchedulerException {
// 创建一个HolidayCalendar对象,定义假期日期(1月1日)
HolidayCalendar holidayCalendar = new HolidayCalendar();
Calendar christmas = new GregorianCalendar();
// 1月
christmas.set(Calendar.MONTH, Calendar.JANUARY);
// 1日
christmas.set(Calendar.DAY_OF_MONTH, 1);
holidayCalendar.addExcludedDate(christmas.getTime());
JobDetail jobDetail = JobBuilder.newJob(MyJob.class)
.withIdentity("job1", "group1")
// 存储数据
.usingJobData("job", "jobDetail")
.usingJobData("name", "jobDetail")
.usingJobData("count", 1)
.build();
// 创建触发器
Trigger trigger = TriggerBuilder.newTrigger()
.withIdentity("trigger1", "trigger1")
.usingJobData("trigger", "trigger")
.usingJobData("name", "trigger")
.usingJobData("count", 2)
// 设置触发器的启动时间
.startNow()
// 设置启动策略
.withSchedule(SimpleScheduleBuilder.simpleSchedule()
// 设置延迟时间
.withIntervalInSeconds(2)
// 设置一直重复执行
.repeatForever())
.modifiedByCalendar("holidayCalendar")
.build();
// StdSchedulerFactory使用配置文件创建调度器;这里使用默认的
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
// 注册Trigger和JobDetail到Scheduler
scheduler.scheduleJob(jobDetail, trigger);
// 将HolidayCalendar关联到Scheduler
/*
name(名称):Calendar 对象指定的唯一标识符。
calendar(日历):用于定义排除特定日期和时间的规则。
replace(替换):设置为 true,新的 Calendar 对象将替换掉已存在的。
为 false,如果同名的 Calendar 对象已经存在,将会抛出 ObjectAlreadyExistsException 异常。
updateTriggers(更新触发器):设置为 true,那么与 Calendar 相关联的所有 Trigger 对象(使用 modifiedByCalendar(name) 方法关联的 Trigger)将会被更新,以反映新的 Calendar 规则。
如果设置为 false,只有在新建 Trigger 时才会使用新的 Calendar 规则,已存在的 Trigger 不会受到影响。
*/
scheduler.addCalendar("holidayCalendar", holidayCalendar, false, false);
// 启动
scheduler.start();
}
}
整合SpringBoot
依赖:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.6.3</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-autoconfigure</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-quartz</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
</dependencies>
数据库建表脚本:
DROP TABLE IF EXISTS QRTZ_FIRED_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_PAUSED_TRIGGER_GRPS;
DROP TABLE IF EXISTS QRTZ_SCHEDULER_STATE;
DROP TABLE IF EXISTS QRTZ_LOCKS;
DROP TABLE IF EXISTS QRTZ_SIMPLE_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_SIMPROP_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_CRON_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_BLOB_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_JOB_DETAILS;
DROP TABLE IF EXISTS QRTZ_CALENDARS;
CREATE TABLE QRTZ_JOB_DETAILS
(
SCHED_NAME VARCHAR(120) NOT NULL,
JOB_NAME VARCHAR(200) NOT NULL,
JOB_GROUP VARCHAR(200) NOT NULL,
DESCRIPTION VARCHAR(250) NULL,
JOB_CLASS_NAME VARCHAR(250) NOT NULL,
IS_DURABLE VARCHAR(1) NOT NULL,
IS_NONCONCURRENT VARCHAR(1) NOT NULL,
IS_UPDATE_DATA VARCHAR(1) NOT NULL,
REQUESTS_RECOVERY VARCHAR(1) NOT NULL,
JOB_DATA BLOB NULL,
PRIMARY KEY (SCHED_NAME,JOB_NAME,JOB_GROUP)
);
CREATE TABLE QRTZ_TRIGGERS
(
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
JOB_NAME VARCHAR(200) NOT NULL,
JOB_GROUP VARCHAR(200) NOT NULL,
DESCRIPTION VARCHAR(250) NULL,
NEXT_FIRE_TIME BIGINT(13) NULL,
PREV_FIRE_TIME BIGINT(13) NULL,
PRIORITY INTEGER NULL,
TRIGGER_STATE VARCHAR(16) NOT NULL,
TRIGGER_TYPE VARCHAR(8) NOT NULL,
START_TIME BIGINT(13) NOT NULL,
END_TIME BIGINT(13) NULL,
CALENDAR_NAME VARCHAR(200) NULL,
MISFIRE_INSTR SMALLINT(2) NULL,
JOB_DATA BLOB NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,JOB_NAME,JOB_GROUP)
REFERENCES QRTZ_JOB_DETAILS(SCHED_NAME,JOB_NAME,JOB_GROUP)
);
CREATE TABLE QRTZ_SIMPLE_TRIGGERS
(
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
REPEAT_COUNT BIGINT(7) NOT NULL,
REPEAT_INTERVAL BIGINT(12) NOT NULL,
TIMES_TRIGGERED BIGINT(10) NOT NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
);
CREATE TABLE QRTZ_CRON_TRIGGERS
(
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
CRON_EXPRESSION VARCHAR(200) NOT NULL,
TIME_ZONE_ID VARCHAR(80),
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
);
CREATE TABLE QRTZ_SIMPROP_TRIGGERS
(
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
STR_PROP_1 VARCHAR(512) NULL,
STR_PROP_2 VARCHAR(512) NULL,
STR_PROP_3 VARCHAR(512) NULL,
INT_PROP_1 INT NULL,
INT_PROP_2 INT NULL,
LONG_PROP_1 BIGINT NULL,
LONG_PROP_2 BIGINT NULL,
DEC_PROP_1 NUMERIC(13,4) NULL,
DEC_PROP_2 NUMERIC(13,4) NULL,
BOOL_PROP_1 VARCHAR(1) NULL,
BOOL_PROP_2 VARCHAR(1) NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
);
CREATE TABLE QRTZ_BLOB_TRIGGERS
(
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
BLOB_DATA BLOB NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
);
CREATE TABLE QRTZ_CALENDARS
(
SCHED_NAME VARCHAR(120) NOT NULL,
CALENDAR_NAME VARCHAR(200) NOT NULL,
CALENDAR BLOB NOT NULL,
PRIMARY KEY (SCHED_NAME,CALENDAR_NAME)
);
CREATE TABLE QRTZ_PAUSED_TRIGGER_GRPS
(
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_GROUP)
);
CREATE TABLE QRTZ_FIRED_TRIGGERS
(
SCHED_NAME VARCHAR(120) NOT NULL,
ENTRY_ID VARCHAR(95) NOT NULL,
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
INSTANCE_NAME VARCHAR(200) NOT NULL,
FIRED_TIME BIGINT(13) NOT NULL,
SCHED_TIME BIGINT(13) NOT NULL,
PRIORITY INTEGER NOT NULL,
STATE VARCHAR(16) NOT NULL,
JOB_NAME VARCHAR(200) NULL,
JOB_GROUP VARCHAR(200) NULL,
IS_NONCONCURRENT VARCHAR(1) NULL,
REQUESTS_RECOVERY VARCHAR(1) NULL,
PRIMARY KEY (SCHED_NAME,ENTRY_ID)
);
CREATE TABLE QRTZ_SCHEDULER_STATE
(
SCHED_NAME VARCHAR(120) NOT NULL,
INSTANCE_NAME VARCHAR(200) NOT NULL,
LAST_CHECKIN_TIME BIGINT(13) NOT NULL,
CHECKIN_INTERVAL BIGINT(13) NOT NULL,
PRIMARY KEY (SCHED_NAME,INSTANCE_NAME)
);
CREATE TABLE QRTZ_LOCKS
(
SCHED_NAME VARCHAR(120) NOT NULL,
LOCK_NAME VARCHAR(40) NOT NULL,
PRIMARY KEY (SCHED_NAME,LOCK_NAME)
);
commit;
来自官方下载的包中,路径为:quartz-2.3.0-SNAPSHOT\src\org\quartz\impl\jdbcjobstore
配置文件:
#============================================================================
# 1. 基本配置
#============================================================================
# 调度标识名,集群中每一个实例都必须使用相同的名称。
# 可以为任意字符串,对于scheduler来说此值没有任何意义,但是可以区分同一系统中多个不同的实例。
# 如果使用了集群的功能,就必须对每一个实例使用相同的名称,这样使这些实例“逻辑上”是同一个scheduler。
org.quartz.scheduler.instanceName = SERVICEX-SCHEDULER-INSTANCE
# ID设置为自动获取,每一个实例不能相同。
# 可以为任意字符串,如果使用了集群的功能,SCHEDULER实例的值必须唯一,可以使用AUTO自动生成。
org.quartz.scheduler.instanceId = AUTO
# 默认值为false
org.quartz.scheduler.rmi.export = false
# 默认值为false
org.quartz.scheduler.rmi.proxy = false
# 默认false,若是在执行Job之前Quartz开启UserTransaction,此属性应该为true。 Job执行完毕,JobDataMap更新完(如果是StatefulJob)事务就会提交。
# 可以在JOB类上使用 @ExecuteInJTATransaction注解,以便在各自的JOB上决定是否开启JTA事务。
org.quartz.scheduler.wrapJobExecutionInUserTransaction = false
# 一个SCHEDULER节点允许接收的TRIGGER的最大数,默认是1。值越大定时任务执行的越多,代价是集群节点之间的不均衡。
org.quartz.scheduler.batchTriggerAcquisitionMaxCount=1
#============================================================================
# 2. 调度器线程池配置
#============================================================================
# 线程池的实现类,一般使用SimpleThreadPool即可满足需求
org.quartz.threadPool.class = org.quartz.simpl.SimpleThreadPool
# 指定线程数无默认值,至少为1,指定该值后线程数量不会动态增加。
org.quartz.threadPool.threadCount = 5
# 线程的优先级(最大为java.lang.Thread.MAX_PRIORITY 10,最小为Thread.MIN_PRIORITY 1,默认为5)
org.quartz.threadPool.threadPriority = 5
# 加载任务代码的ClassLoader是否从外部继承
org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread = true
# 是否设置调度器线程为守护线程
org.quartz.scheduler.makeSchedulerThreadDaemon = true
#============================================================================
# 3. 作业存储配置
#============================================================================
# JDBC的存储方式
org.quartz.jobStore.class=org.springframework.scheduling.quartz.LocalDataSourceJobStore
# 数据库驱动,类似于Hibernate的dialect,用于处理DB之间的差异,StdJDBCDelegate能满足大部分的DB的使用。
org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.PostgreSQLDelegate
# 是否加入集群,当有多个Quartz实例在用同一套数据库时,必须设置为true。
org.quartz.jobStore.isClustered = true
# 检查集群节点状态的频率, 默认值是 15000(即15秒)
# 只用于设置了isClustered为true的时,才需要设置该项,用于实例上报信息给集群中的其他实例,这个值的大小会影响到侦测失败实例的敏捷度。
org.quartz.jobStore.clusterCheckinInterval = 5000
# 这是JobStore能处理的错过触发的TRIGGER的最大数量。处理太多则很快就会导致数据库中的表被锁定够长的时间,这样则会妨碍别的(还未错过触发)TRIGGER执行的性能。
org.quartz.jobStore.maxMisfiresToHandleAtATime = 1
org.quartz.jobStore.txIsolationLevelSerializable = true
# 设置这个参数为true会告诉Quartz从数据源获取连接后不要调用它的setAutoCommit(false)方法,大部分情况下驱动都要求调用setAutoCommit(false)。
org.quartz.jobStore.dontSetAutoCommitFalse = false
# 这必须是一个从LOCKS表查询一行并对这行记录加锁的SQL。假设没有设置,默认值如下。{0}会在运行期间被配置的TABLE_PREFIX所代替。
org.quartz.jobStore.selectWithLockSQL=SELECT * FROM {0}LOCKS WHERE LOCK_NAME = ? FOR UPDATE
# 设置调度引擎对触发器超时的忍耐时间 (单位毫秒)
org.quartz.jobStore.misfireThreshold = 12000
# 表的前缀,默认QRTZ_
org.quartz.jobStore.tablePrefix = QRTZ_
SpringBoot在2.5.6版本之后就删除了关于Quartz相关的依赖;在2.5.6及之前版本:
org.quartz.jobStore.class=org.quartz.impl.jdbcjobstore.JobStoreTX
SpringBoot只需要配置数据源即可。
配置类:
@Configuration
public class SchedulerConfig {
@Autowired
private DataSource dataSource;
@Bean
public Scheduler scheduler() throws IOException {
return schedulerFactoryBean().getScheduler();
}
@Bean
public SchedulerFactoryBean schedulerFactoryBean() throws IOException {
SchedulerFactoryBean factoryBean = new SchedulerFactoryBean();
factoryBean.setSchedulerName("MyScheduler");
factoryBean.setDataSource(dataSource);
// 设置配置文件
PropertiesFactoryBean propertiesFactoryBean = new PropertiesFactoryBean();
propertiesFactoryBean.setLocation(new ClassPathResource("/spring-quartz.properties"));
propertiesFactoryBean.afterPropertiesSet();
factoryBean.setQuartzProperties(propertiesFactoryBean.getObject());
factoryBean.setTaskExecutor(schedulerThreadPool());
//设置延迟时间
factoryBean.setStartupDelay(0);
return factoryBean;
}
@Bean
public Executor schedulerThreadPool() {
//ThreadPoolTaskExecutor是Spring框架提供的一个线程池实现,通常用于管理任务的执行。
ThreadPoolTaskExecutor threadPool = new ThreadPoolTaskExecutor();
// 设置线程数为虚拟机可用的处理器数
threadPool.setCorePoolSize(Runtime.getRuntime().availableProcessors());
threadPool.setMaxPoolSize(Runtime.getRuntime().availableProcessors());
threadPool.setQueueCapacity(Runtime.getRuntime().availableProcessors());
return threadPool;
}
}
设置监听器,在SpringBoot启动时启动调度器:
@Component
public class StartApplicationListener implements ApplicationListener<ContextClosedEvent> {
@Autowired
private Scheduler scheduler;
@Override
public void onApplicationEvent(ContextClosedEvent event) {
TriggerKey triggerKey = TriggerKey.triggerKey("trigger1", "trigger1");
try {
Trigger trigger = scheduler.getTrigger(triggerKey);
if (Objects.isNull(trigger)) {
trigger = TriggerBuilder.newTrigger()
.withIdentity(triggerKey)
.withSchedule(CronScheduleBuilder.cronSchedule("0/2 * * * * ? "))
.build();
JobDetail jobDetail = JobBuilder.newJob(MyQuartzJob.class)
.withIdentity("job1", "group1")
.build();
scheduler.scheduleJob(jobDetail, trigger);
scheduler.start();
}
} catch (SchedulerException e) {
throw new RuntimeException(e);
}
}
}
cron表达式最好还是用在线工具生成,手打容易漏空格
public class MyQuartzJob extends QuartzJobBean {
@Override
protected void executeInternal(JobExecutionContext context) throws JobExecutionException {
System.out.println("现在的时间是:" + new Date());
}
}
常用简单实现
使用两个注解便可以基本满足我们定时任务的需求:
- @Scheduled
- @EnableScheduling
实例:
@EnableScheduling
@SpringBootApplication
public class MyRun {
public static void main(String[] args) {
SpringApplication.run(MyRun.class, args);
}
}
@Service
public class MyService {
@Scheduled(fixedRate = 1000)
public void test(){
System.out.println("Hello!");
}
}
@Scheduled的用法非常灵活,以下是一些使用示例:
@Scheduled(fixedRate = 60000): 每60秒执行一次。
@Scheduled(fixedDelay = 60000): 当前次任务执行完成后,延迟60秒后执行下一次任务。
@Scheduled(initialDelay = 10000, fixedRate = 60000): 首次延迟10秒,之后每60秒执行一次。
@Scheduled(cron = "0 * * * * ?"): 使用Cron表达式来定义更复杂的定时任务规则。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号