


python3.x爬取美团信息
在之前的文章中,笔者有提到,我们要在实践中去学习python,笔者有天就想着要不要爬点东西呢,跃跃欲试的节奏啊,想来想去,想到美团了,那么首先笔 者想给自己确定一个目标,就是我要爬什么样的数据,我要爬美团的哪些东西。笔者首先确定了笔者想要爬去的界 面,http://bj.meituan.com/。就是美团网在北京的团购首页,获取首页的团购,团购项目的介绍,团购售价,销量。
1.首先确定要用的模块,<1.>urrlib,os,re三个模块,
2.要想获得数据,并且一一对应起来,那么用到循环的嵌套(一开始卡壳,后来咨询得到启发),
3.获取网页的所有数据,爬去下来
4.分析这些想要或许的模块怎么找出来,
5.找出相对于的正则来匹配,
6.获取数据,并且找到对应的数值
7.利用循环,并且配合字典的使用,将数据完整的获取下来,
8.保存到相应的文档中
9.关闭文档,
10.提示数据保存成功,结束爬去。
由于这是第一次采取这么多的信息,之前只是爬个图片啥的,所以笔者还是十分小心的去审查每一个元素,在这里推荐利用火狐浏览器,感觉是真的好用使用Firebug插件审查元素。
查看元素后,可以获得这个网站的编码形式是utf-8,这对于我们爬取数据也是关键的。
在一开始呢,笔者还打开了一款软件,fiddler,抓包
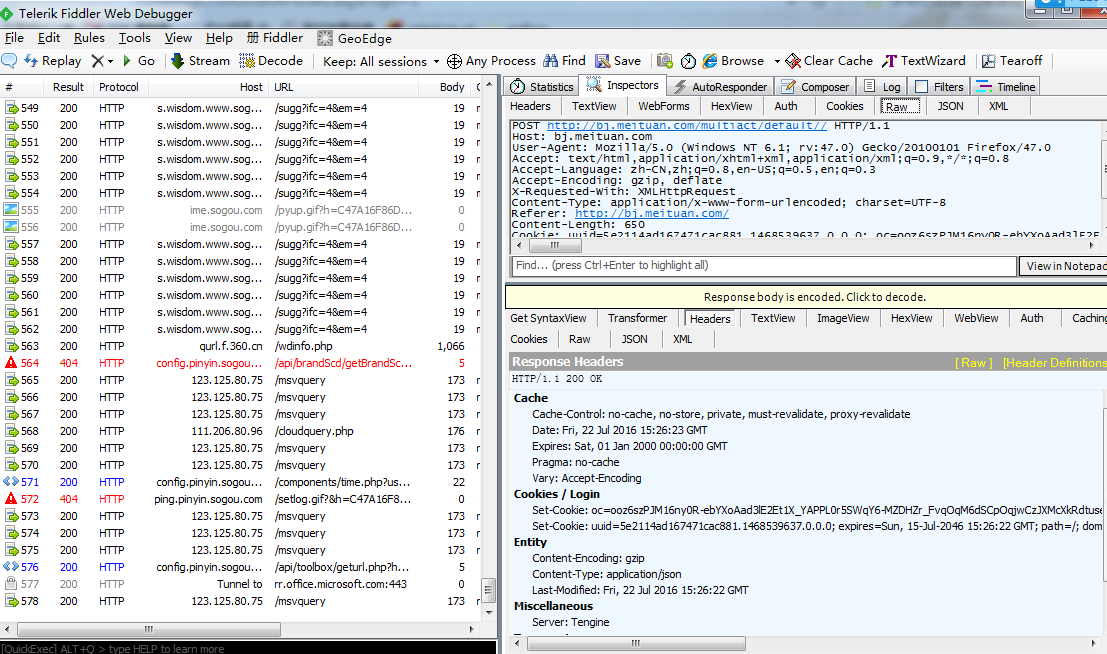
这些信息还是很多的,由于笔者截图的时候碰到了网络的原因,但是笔者还是找到了自己想要的信息,这样可以在自己的代码中加入伪装浏览器的信息,那么接下来要做的事情就是定位我们想要找的数据。
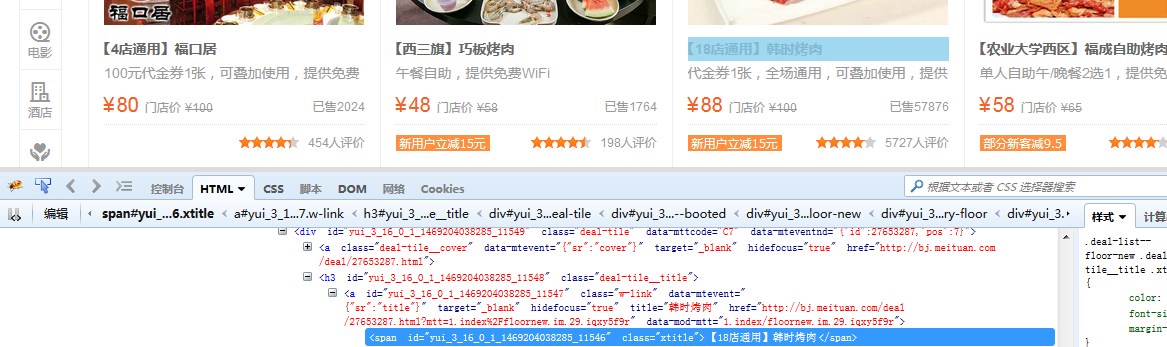
分析首页的团购信息,我们可以根据多个来确认这个信息的唯一标识符,<span>标签中并且有class="xtitle"< /span>中间文字,那么我们的正则表达式就出来了,r'<span
class="xtitle">(.+?)</span>'(正则太难,笔者一个个试出来的)
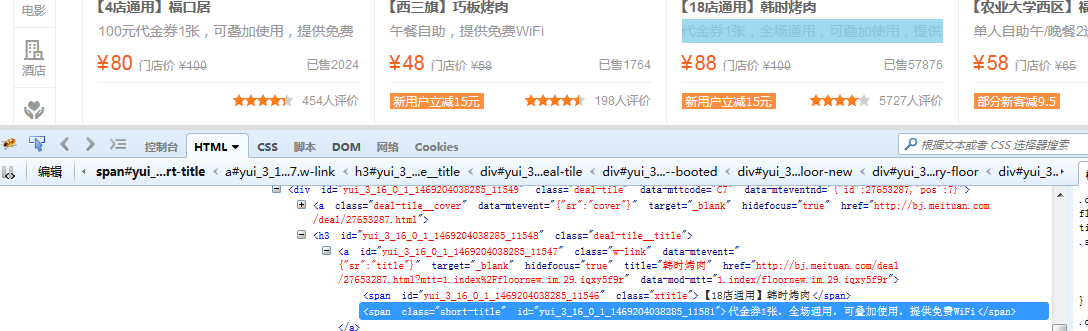
描述也是<span>标签并且 class="short-title",</span>的文字,那么很快就匹配到了,正则出来了,r'class="short-title">(.+)</span>'
后面的就是依次类推。完成这个,那么我们就开始写我们的爬虫程序,导入我们想要用的模块,定义我们想要用的变量。爬去,匹配,然后循环得出来我们的结果,写入文档。代码如下
#作者:雷子
#qq:952943386
#邮箱:leileili126@163.com
#欢迎大家来点评,有问题可以进行沟通
import urllib.request
import os
import re
file=open(r'meituancde.txt','w')
url="http://bj.meituan.com/"
headers={"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X
10.10; rv:47.0) Gecko/20100101 Firefox/47.0"}
req=urllib.request.Request(url,headers=headers)
response = urllib.request.urlopen(req)
html = response.read().decode("utf-8")
title_reg=r'<span
class="xtitle">(.+?)</span>' #匹配团购
jianjie_reg=r'class="short-title">(.+)</span>' #匹配团购简介
sellnum_reg=r'<strong class="num">(.+)</strong>' #销售的数量
pire_reg=r'<strong>(.+)</strong>' #团购的售价
title_list = re.findall(title_reg,html)
jianjie_list=re.findall(jianjie_reg,html)
sellnum_list=re.findall(sellnum_reg,html)
pire_list=re.findall(pire_reg,html)
meitu={}
i = 0
for title in title_list:
meitu['团购'] =title_list[i]
for jianjie in jianjie_list:
meitu['简介']=jianjie_list[i]
for sellum in sellnum_list:
meitu['销量']=sellnum_list[i]
for pire in
pire_list:
meitu['美团售价']=pire_list[i]
i+=1
print(meitu)
if len(meitu) !=0:
file.write(str(meitu))
file.write("\n")
file.close
print("写入正确")
代码 百度云

 浙公网安备 33010602011771号
浙公网安备 33010602011771号