从RNN到Sequence2Sequence(一) RNN
RNN原理
一、RNN
RNN其实就是在时间上的一个循环,每次循环都会用到上一次计算的结果。
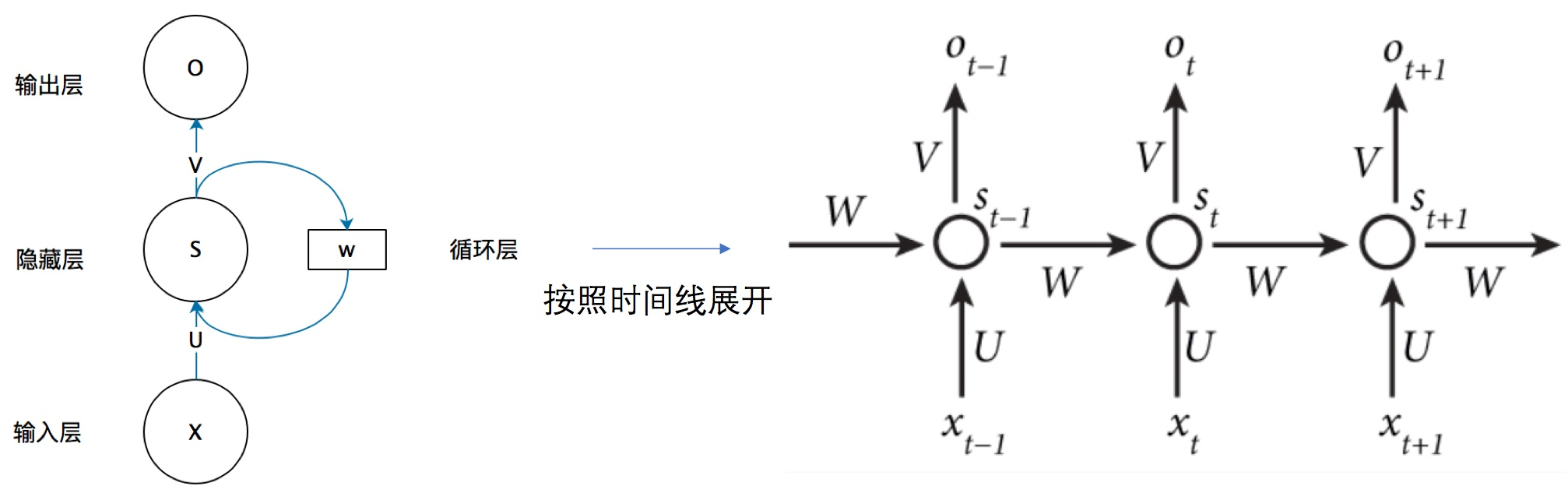
\(U\)是输入层到隐藏层的权重矩阵,\(V\) 是隐藏层到输出层的权重矩阵。\(s\)是一个向量,表示隐藏层的值,长度等于隐藏层神经节点的个数。
\(W\)是上一个时刻隐藏层的值传到这一时刻的权重矩阵。
这个网络在t时刻接收到输入\(x_t\)之后,隐藏层的值是\(s_t\) ,输出值是\(o_t\)。关键一点是, \(s_t\)的值不仅仅取决于\(x_t\),还取决于\(s_{t-1}\)。
优点:处理a sequence或者a timeseries of data points效果比普通的DNN要好。中间状态理论上维护了从开头到现在的所有信息。
缺点:不能处理long sequence/timeseries问题。原因是梯度消失,网络几乎不可训练。所以也只是理论上可以记忆任意长的序列。
二、双向循环神经网络
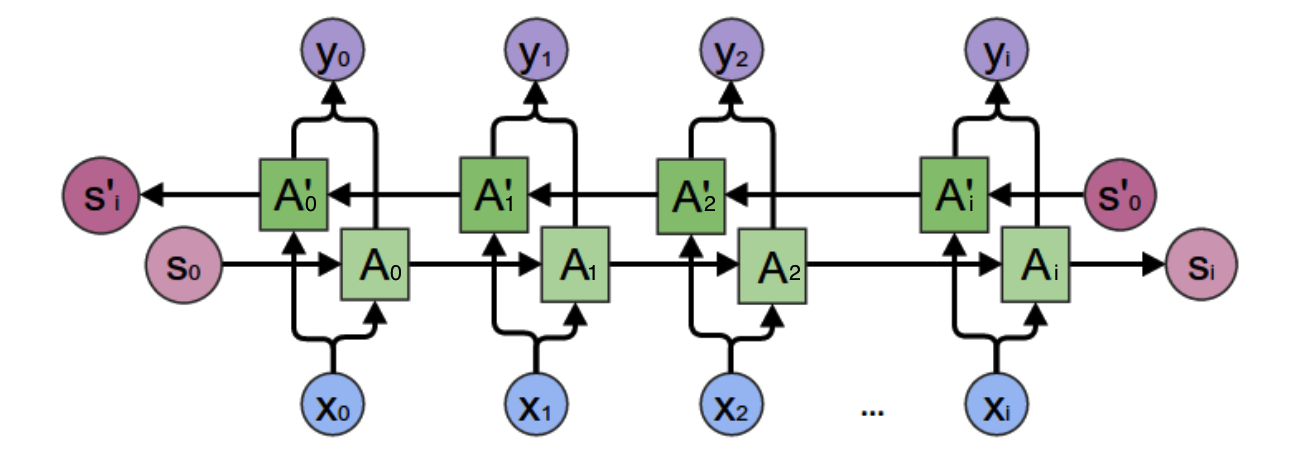
双向循环神经网络的隐藏层保存两个值:\(A\)参与正向计算,\(A'\)参与反向计算。最终的输出\(y\)取决于\(A\)和\(A'\)。
正向计算时,隐藏层的值\(s_t\)与\(s_{t-1}\)有关;反向计算时,隐藏层的值\(s_t'\)与\(s_{t+1}'\)有关。
三、深度循环神经网络
前面我们介绍的循环神经网络只有一个隐藏层,我们当然也可以堆叠两个以上的隐藏层,这样就得到了深度循环神经网络。
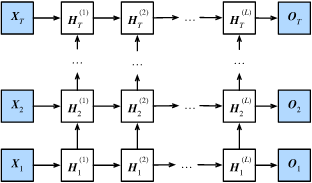
上图有\(L\)个隐藏层的深度循环神经网络,每个隐藏状态不断传递至当前层的下一时间步和当前时间步的下一层。
四、梯度消失和梯度爆炸
https://zhuanlan.zhihu.com/p/28687529
RNN实现垃圾邮件分类
数据集:UCI 的 ML 仓库中的 SMS 垃圾邮件收集数据集。http://archive.ics.uci.edu/ml/machine-learning-databases/00228/smsspamcollection.zip
原理:文本向量化后经过RNN得到输出,再经过softmax得到为0(垃圾邮件)和1(非垃圾邮件)的概率。
ps: ham 代表正常邮件。spam代表垃圾邮件。ham原意为火腿肉。spam为午餐肉。二战时候,美国士兵的粮食供给是以罐头的形式运输到前线的。制作这些罐头的商人在某些时期,使用了少量肉加其它东西制作午餐肉,为美国大兵所诟病,以spam代表垃圾邮件也大概如此了。
1.加载需要的库
import os
import re
import io
import requests
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from zipfile import ZipFile
from tensorflow.python.framework import ops
ops.reset_default_graph()
# Start a graph
sess = tf.Session()
2.设置RNN模型参数
epochs = 20 # 训练20轮
batch_size = 250 # 批量大小
max_sequence_length = 25 # 文本最大长度
rnn_size = 10 # 隐藏层大小为10
embedding_size = 50 # 嵌入维度
min_word_frequency = 10 # 最小词频,只考虑在词汇表中出现至少 10 次的单词
learning_rate = 0.0005 # 学习率
dropout_keep_prob = tf.placeholder(tf.float32)
3. 样本和标签占位符
x输入将是一个大小为[None, max_sequence_length]的占位符,它将是根据文本消息允许的最大字长的批量大小。
y -output 占位符一个 0 或 1 的整数:
x_data = tf.placeholder(tf.int32, [None, max_sequence_length])
y_output = tf.placeholder(tf.int32, [None])
为x输入数据创建嵌入矩阵和嵌入查找操作。one-hot编码转换为嵌入维度为50的向量。
embedding_mat = tf.Variable(tf.random_uniform([vocab_size, embedding_size], -1.0, 1.0))
embedding_output = tf.nn.embedding_lookup(embedding_mat, x_data)
4.模型创建
4.1 cell
cell = tf.nn.rnn_cell.BasicRNNCell(num_units=rnn_size) # 隐藏层神经元个数=rnn_size
BasicRNNCell 即为图一所示RNN网络。
4.2 输出
在此处接收输入样本,得到神经网络的输出\(O\)
output, state = tf.nn.dynamic_rnn(cell, embedding_output, dtype=tf.float32)
output = tf.nn.dropout(output, dropout_keep_prob)
dynamic_rnn方法返回一个元组(output,state)
outputs:output很容易理解,就是每个cell会有一个输出。shape 为 [batch_size,文本长度,output_size]
states:states表示最终的状态,也就是序列中最后一个cell输出的状态。一般情况下states的形状为 [batch_size, output_size ]。
4.3 输出变换
output = tf.transpose(output, [1, 0, 2])
last = tf.gather(output, int(output.get_shape()[0]) - 1)
关于last,此output 为 (25个时间步的输出,batch,输出的形状10)。 tf.gather(output,24),即只取25个时间步中的最后一步,默认这一步包含了前面所有步骤的信息。
4.4 经过sottmax得到类别
weight = tf.Variable(tf.truncated_normal([rnn_size, 2], stddev=0.1))
bias = tf.Variable(tf.constant(0.1, shape=[2]))
logits_out = tf.nn.softmax(tf.matmul(last, weight) + bias)
5、定义损失函数和优化器
当使用 TensorFlow 中的sparse_softmax函数时,目标必须是整数索引(类型为int),并且 logits 必须是浮点数:
losses = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits_out, labels=y_output)
loss = tf.reduce_mean(losses)
optimizer = tf.train.RMSPropOptimizer(learning_rate)
train_step = optimizer.minimize(loss)
# 精确度函数,以便我们可以比较测试和训练集上的算法
accuracy = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(logits_out, 1), tf.cast(y_output, tf.int64)), tf.float32))
6、训练过程
init = tf.global_variables_initializer()
sess.run(init)
train_loss = []
test_loss = []
train_accuracy = []
test_accuracy = []
# Start training
for epoch in range(epochs):
# Shuffle training data
shuffled_ix = np.random.permutation(np.arange(len(x_train)))
x_train = x_train[shuffled_ix]
y_train = y_train[shuffled_ix]
num_batches = int(len(x_train)/batch_size) + 1
for i in range(num_batches):
# Select train data
min_ix = i * batch_size
max_ix = np.min([len(x_train), ((i+1) * batch_size)])
x_train_batch = x_train[min_ix:max_ix]
y_train_batch = y_train[min_ix:max_ix]
# Run train step
train_dict = {x_data: x_train_batch, y_output: y_train_batch, dropout_keep_prob:0.5}
sess.run(train_step, feed_dict=train_dict)
# Run loss and accuracy for training
temp_train_loss, temp_train_acc = sess.run([loss, accuracy], feed_dict=train_dict)
train_loss.append(temp_train_loss)
train_accuracy.append(temp_train_acc)
# Run Eval Step
test_dict = {x_data: x_test, y_output: y_test, dropout_keep_prob:1.0}
temp_test_loss, temp_test_acc = sess.run([loss, accuracy], feed_dict=test_dict)
test_loss.append(temp_test_loss)
test_accuracy.append(temp_test_acc)
print('Epoch: {}, Test Loss: {:.2}, Test Acc: {:.2}'.format(epoch+1, temp_test_loss, temp_test_acc))
参考资料
- 零基础入门深度学习(5) - 循环神经网络
https://zybuluo.com/hanbingtao/note/541458 - RNN梯度消失和爆炸的原因
https://zhuanlan.zhihu.com/p/28687529 - 为垃圾邮件预测实现 RNN
https://wizardforcel.gitbooks.io/tf-ml-cookbook-2e-zh/content/70.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号