

分布式和集群的概念和区别
分布式系统是当前比较热门的话题,说到分布式就不得不提集群和单机,如果要学习分布式就要先对他的概念和功能有所了解
一、单机
单机就是把做的系统部署到一台服务器上,,所有的请求业务都由这台服务器处理。显然,当业务增长到一定程度的时候,服务器的硬件会无法满足业务需求。很多人就会想到多部署几台服务器,这就是集群。
二、 集群
集群就是单机的多实例,在多个服务器上部署多个服务,每个服务就是一个节点,部署N个节点,处理业务的能力就提升 N倍(大约),这些节点的集合就叫做集群。
需要注意的一点是:集群中服务器提供的服务是等效的(无状态的)还是需要记录状态的,这对集群设计的影响非常大。
优点:操作简单,容易部署;
缺点:每个节点负载相同(耦合度高),每个具体业务的访问量可能差异很大,比如美团外卖美食外卖的访问量一定大于鲜花外卖的访问量,这就造成了资源浪费
三、分布式(微服务)
分布式结构就是将一个完整的系统,按照业务功能,拆分成一个个独立的子系统,在分布式结构中,每个子系统就被称为“服务”。这些子系统能够独立运行在web容器中,它们之间通过RPC方式通信。
优点:资源利用率高
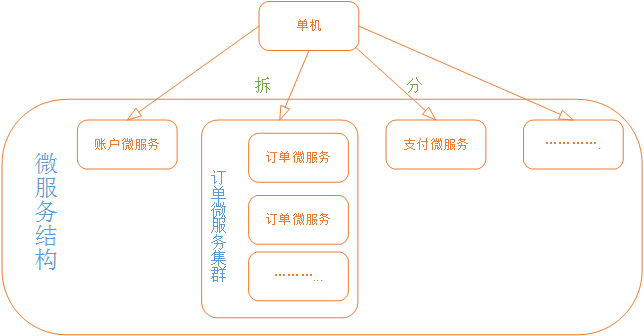
缺点:安全性低,如果一台服务器出现问题整个系统就会崩塌
去中心化(decentralized):没有主从的分布式
四、总结
所以好的设计应该是分布式和集群的结合,先分布式再集群,具体实现就是业务拆分成很多子业务,然后针对每个子业务进行集群部署,这样每个子业务如果出了问题,整个系统完全不会受影响。
微服务的设计是为了不因为某个模块的升级和BUG影响现有的系统业务。微服务与分布式的细微差别是,微服务的应用不一定是分散在多个服务器上,他也可以是同一个服务器。
优点:
- 系统之间的耦合度大大降低,可以独立开发、独立部署、独立测试,系统与系统之间的边界非常明确,排错也变得相当容易,开发效率大大提升。
- 系统之间的耦合度降低,从而系统更易于扩展。我们可以针对性地扩展某些服务,就是对子系统集群。例如双十一时,订单子系统、支付子系统需要集群,账户管理子系统不需要集群。
- 服务的复用性更高。比如,当我们将用户系统作为单独的服务后,该公司所有的产品都可以使用该系统作为用户系统,无需重复开发。
集群强调高可用,分布式强调多业务协作
集群倾向于物理概念,即多台机器组成一个集群。这多台机器是否有合作关系并不能保证,比如我们会说我们公司的一个规模为1000台机器的物理集群部署在昌平,但是这1000台机器可能是给公司内不同的平台提供服务,但是从物理角度,由于都部署在一起,在同一个机房,就可以称之为集群。
分布式倾向于逻辑概念,即多个节点或程序为了一个共同的目标,部署在一个或者多个物理机器上。举个例子,一台物理机上装了一个Nginx,它连接的两个Tomcat也在这台物理机上,但是这个Nginx代表的服务,就可以称之为分布式。当然,为了安全性,稳定性等原因,我们并不建议把分布式部署在一个物理节点上。
分布式其实就是将一个大项目的拆分出来,单独运行。
举个上面的例子。假设我们的访问量特别大。我们就可以做成分布式,跟 cdn 一样的机制。在北京,杭州,深圳三个地方都搭建一个一模一样的集群。离北京近的用户就访问北京的集群,离深圳近的就访问深圳这边的集群。这样就将我们网站给拆分 3 个区域了,各自独立。
单体架构
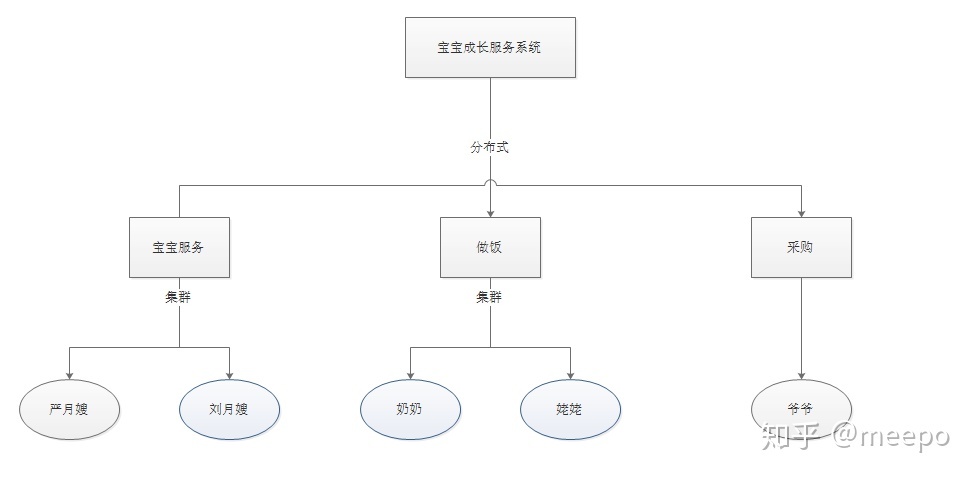
家里生小宝宝啦,由于自己没有照顾小宝宝的经验,所以请了位经验丰富的月嫂。 这位月嫂从买菜,到做饭,洗衣,拖地,喂奶,哄睡,洗澡,换纸尿裤,擦屁股,做排气操,夜间陪护,给奶妈做月子餐等等,全部都做。 这种叫做单体架构。
集群:
什么都做,一个月嫂怎么够呢,肯定忙不过来呀,那就请两个月嫂吧,这叫做集群。
高可用:
有一个月嫂过生日,想请假回去和亲戚打一天麻将。如果只有一个月嫂,她走了,就叫做服务中断了。 但是因为做了集群,有两个月嫂,走了一个,另一个还是能用,虽然相比较吃力一些,但是毕竟还是能用的,这个现象叫做高可用。
分布式:
一个月嫂,一个月的费用基本上都要1万多,还有房贷,还有车贷,生活费用还高,实在是请不起两位啊,那就还是请一位吧。 可是事情那么多,她实在忙不过来,怎么办呢? 那就把爷爷请过来买菜,把奶奶请过来做饭。 这样服务本来仅仅是由月嫂一人提供的,变成了和宝宝相关的由月嫂负责,采购由爷爷负责,餐饮由奶奶负责。 这就叫做分布式了。
低耦合:
做宝宝服务的月嫂去打麻将了,不影响做饭的奶奶。 做采购的爷爷去喝酒了,也不影响月嫂的宝宝服务,这叫做低耦合。
高内聚:
和宝宝相关的事情都是月嫂在做,月嫂兑奶方式快慢,只会影响自己,对爷爷和奶奶的服务没影响. 这叫做高内聚。
集群+分布式:
奶奶一个人做饭,做久了也烦啊,也累啊,也想打麻将呀。 那么就把姥姥也请过来吧。 这样做饭这个服务,就由奶奶和姥姥这个集群来承担啦。她们俩,谁想去汗蒸了,都有另一位继续提供做饭服务。 这就叫做集群+分布式。
- 集群中的多个服务器都在做相同的事情,并不能缩短处理一件事情的时间。
- 而分布式呢,是把事情拆开,多个服务器分头做事,可以缩短时间。
分布式可繁也可以简,最简单的分布式就是大家最常用的,在负载均衡服务器后加一堆web服务器,然后在上面搞一个缓存服务器来保存临时状态,后面共享一个数据库,其实很多号称分布式专家的人也就停留于此,大致结构如下图所示:
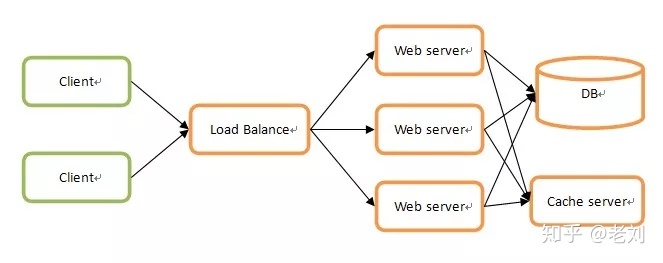
这种环境下真正进行分布式的只是web server而已,并且web server之间没有任何联系,所以结构和实现都非常简单。
有些情况下,对分布式的需求就没这么简单,在每个环节上都有分布式的需求,比如Load Balance、DB、Cache和文件等等,并且当分布式节点之间有关联时,还得考虑之间的通讯,另外,节点非常多的时候,得有监控和管理来支撑。
这样看起来,分布式是一个非常庞大的体系,只不过你可以根据具体需求进行适当地裁剪。按照最完备的分布式体系来看,可以由以下模块组成:
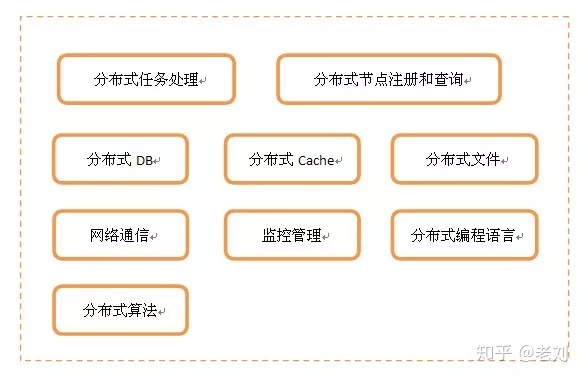
- 分布式任务处理服务:负责具体的业务逻辑处理
- 分布式节点注册和查询:负责管理所有分布式节点的命名和物理信息的注册与查询,是节点之间联系的桥梁
- 分布式DB:分布式结构化数据存取
- 分布式Cache:分布式缓存数据(非持久化)存取
- 分布式文件:分布式文件存取
- 网络通信:节点之间的网络数据通信
- 监控管理:搜集、监控和诊断所有节点运行状态
- 分布式编程语言:用于分布式环境下的专有编程语言,比如Elang、Scala
- 分布式算法:为解决分布式环境下一些特有问题的算法,比如解决一致性问题的Paxos算法
因此,若要深入研究云计算和分布式,就得深入研究以上领域,而这些领域每一块的水都很深,都需要很底层的知识和技术来支撑,所以说,对于想提升技术的开发者来说,以分布式来作为切入点是非常好的,可以以此为线索,探索计算机世界的各个角落。
看了很多回答感觉大多数都是在讲无状态节点集群,观点就是放相同内容的机器构成集群。这个比较好理解
但是对于有状态节点而言,比如Redis Cluster,各个节点间存储的内容是不一样的,我们也称为集群。而像Etcd、Zookeeper各个节点又是分为主从节点,各个节点数据是一样的,也叫集群,像RabbitMQ的普通集群模式类似RedisCluster,各个MQ存各自的消息,镜像集群模式又像Etcd、Zookeeper各个节点存相同的消息
这个回答比较认同 https://www.zhihu.com/question/20004877/answer/568581790
分布式是指通过网络连接的多个组件,通过交换信息协作而形成的系统。而集群,是指同一种组件的多个实例,形成的逻辑上的整体。这样理解的话应该就不用纠结是不是一样的数据的问题了。
集群主要分成三大类 (高可用集群, 负载均衡集群,科学计算集群)
高可用集群( High Availability Cluster)
负载均衡集群(Load Balance Cluster)
科学计算集群(High Performance Computing Cluster)

Client把一些数据放到Memcached中,省的每次都是数据库查,如果只有一个Memcached,那一旦请求压力大了,Memcached很快就忙不过来(虽然Memcached是多线程),而且一旦Memcached挂了,那就没有缓存可以用了,全部请求都会走数据库,数据库的压力会骤然增加!
所以我们加多了两个Memcached节点,形成Memcached集群:
Memcached集群实现了开头提到的两个特性:
- 高吞吐量:通过负载均衡算法(通常是借助一致性Hash和虚拟节点),我们把Client的请求均匀分配到三台Memcached服务器上,不至于只让一台Memcached疲于处理全部请求。Memcached集群也是每个节点各司其职,每个节点负责一小部分请求,共同实现缓存这个功能
- 高可用:一旦一台Memcached节点挂了,比如说Memcached1,那借助一致性Hash算法和它的虚拟节点机制,我们可以将原本发给Client的Memcached1的请求均匀分配到Memcached2和3上,缓存功能依旧可用。
有人说,请求会被分布到各个Memcached节点,这不就是分布式吗?
严格来说,这只能算是“分布的”(distributed),正如Memcached官网的介绍说的:
memcached is a high-performance, distributed memory object caching system
总结:
分布式不一定就是不同的组件,同一个组件也可以,关键在于是否通过交换信息的方式进行协作。比如说Zookeeper的节点都是对等的,但它自己就构成一个分布式系统。
也就是说,分布式是指通过网络连接的多个组件,通过交换信息协作而形成的系统。而集群,是指同一种组件的多个实例,形成的逻辑上的整体。
可以看出这两个概念并不完全冲突,分布式系统也可以是一个集群,例子就是前面说的zookeeper等,它的特征是服务之间会互相通信协作。是分布式系统不是集群的情况,就是多个不同组件构成的系统;是集群不是分布式系统的情况,比如多个经过负载均衡的HTTP服务器,它们之间不会互相通信,如果不带上负载均衡的部分的话,一般不叫做分布式系统。
还有其它一些走分布式架构后常见的要解决的技术问题:
(一)、分布式会话
(二)、分布式锁
(三)、分布式事务
(四)、分布式搜索
(五)、分布式缓存
(六)、分布式消息队列
(七)、统一配置中心
(八)、分布式存储,数据库分库分表
(九)、限流、熔断、降级等。
以上这些问题,往深了说,每一个点都需要可能 N 篇文章来详细阐述,这里没法逐一展开,后面我们会继续通过一些文章,聊一聊这些分布式架构下的各种技术问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号