

Pandas模块补充与Matplotlib模块(上)
-
pandas其他操作补充
-
pandas实战案例
-
可视化模块之matplotlib
详情
-
pandas其他操作补充
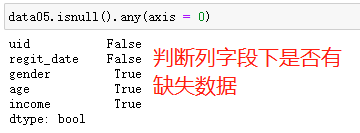
缺失值处理
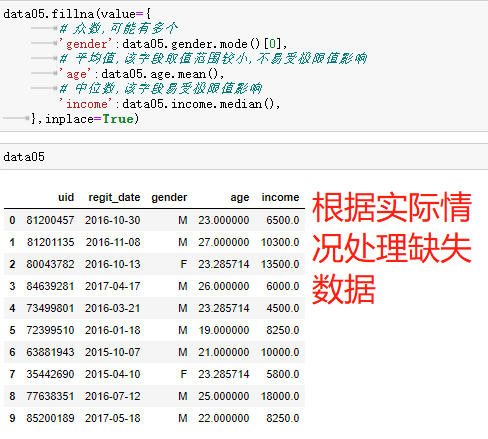
# 缺失值的识别与处理主要怕围绕以下三个方法进行 1.df.isnull() 2.df.fillna() 3.df.dropna() # 处理流程 1.读取文件 data05 = pd.read_excel(r'data_test05.xlsx') 2.先查看开始几行数据 data05.head() 3.判断每项数据是否有缺失 data05.isnull() 判断列字段下是否有缺失数据 data05.isnull().any(axis = 0) 4.计算各列数据的缺失比例 data05.isnull().sum(axis = 0)/data05.shape[0] # 处理方法 5.常规处理方式 (1)删除缺失数据(如缺失数据比例足够小,可删) data05.dropna() (2)将所有缺失值填充为指定值(一般不推荐) data05.fillna(value=0) '''针对不同的缺失值需要采用合理的填充手段''' 6.特殊处理方式 data05.fillna(value={ # 众数,可能有多个 'gender':data05.gender.mode()[0], # 平均值,该字段取值范围较小,不易受极限值影响 'age':data05.age.mean(), # 中位数,该字段易受极限值影响 'income':data05.income.median(), },inplace=True)



数据汇总
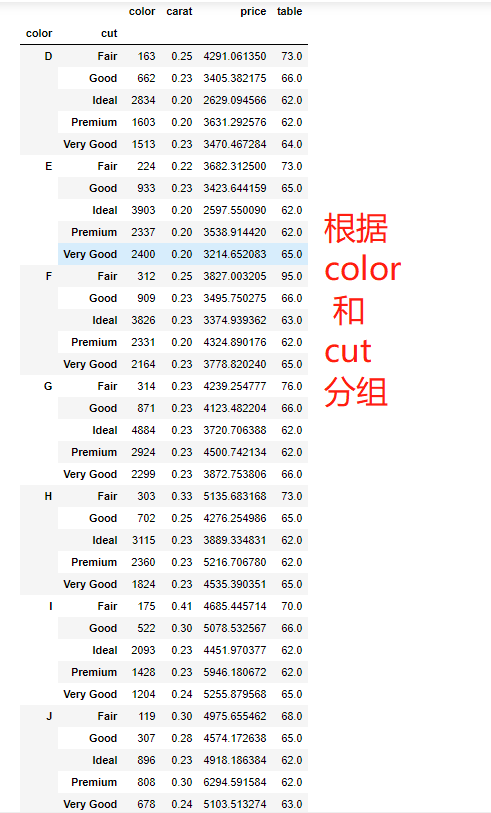
# 透视表 pd.pivot_table(data, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All') # 参数说明 1.data:指定需要构造透视表的数据集 2.values:指定需要显示成数值的字段 3.index:指定行标签字段 4.columns:指定列标签字段 5.aggfunc:指定数值的统计函数,默认为均值;也可以使用numpy模块中其他函数 6.fill_value:指定用于填充缺失数据的值 7.margins:bool类型,判断是否需要显示行或列的总和,默认为False 8.dropna:bool类型,判断是否需要删除整列均缺失的字段,默认为True 9.margins_name:指定行或列的总和名,默认为All '''案例''' data06 = pd.read_csv(r'diamonds.csv') data06.head() pd.pivot_table(data06, index = 'color', values='price', aggfunc='mean') pd.pivot_table(data06, index = 'color', columns='clarity', values='price', aggfunc='size')


分组&聚合
# 使用聚合函数需要引入numpy模块 import numpy as np # 通过group方法,指定分组依据 groupDf = data06.groupby(by=['color','cut']) # 对分组后的数据进行统计汇总 result = groupDf.aggregate({ 'color':np.size,'carat':np.min, 'price':np.mean,'table':np.max }) # 调整变量名的顺序 result = pd.DataFrame(result, columns=['color','carat','price','table']) # 数据集重命名 result.rename(columns={'color':'counts', 'carat':'min_weight', 'price':'avg_price', 'table':'max_table'}, inplace=True)
数据合并(纵向,一般用于列相同的数据)
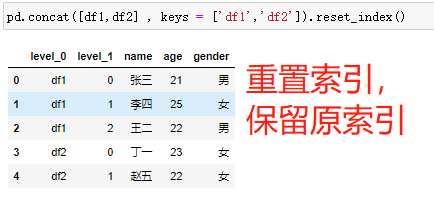
pd.concat(objs,axis=0,join='outer',join_axes=None, ignore_index=False,keys=None) # 参数说明 1.objs:需要合并的对象,可以是序列(series),数据框(dataframe),或者数据构成的列表 2.axis:数据合并的轴方向,默认为 0-行,1-列 3.join:合并的方式,默认为outer表示合并所有数据,inner为合并公共数据 4.join_axes:合并数据后保留的数据轴 5.ignore_index:bool类型,判断是否忽略原数据索引,默认为 False——不忽略,True——忽略原索引生成新索引 6.keys:为合并后的数据添加表示合并前对象的新索引,用于区分各个部分# 数据集的纵向合并 pd.concat([df1,df2] , keys = ['df1','df2']) # 加keys参数可以在合并之后看到数据来源 pd.concat([df1,df2] , keys = ['df1','df2']).reset_index() pd.concat([df1,df2] , keys = ['df1','df2']).reset_index().drop(labels ='level_1', axis = 1).rename(columns = {'level_0':'Class'}) # 如果df2数据集中的“姓名变量为Name” df2 = pd.DataFrame({ 'Name':['丁一','赵五'], 'age':[23,22], 'gender':['女','女']} ) # 数据集的纵向合并 pd.concat([df1,df2]) # concat行合并,数据源的变量名称完全相同(变量名顺序没有要求)
数据准备
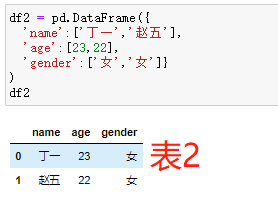
'''案例''' # 构造数据集df1和df2 df1 = pd.DataFrame({ 'name':['张三','李四','王二'], 'age':[21,25,22], 'gender':['男','女','男']} ) df2 = pd.DataFrame({ 'name':['丁一','赵五'], 'age':[23,22], 'gender':['女','女']} )

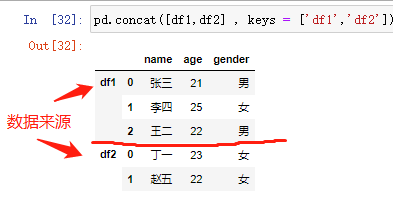
合并
# 数据集的纵向合并 pd.concat([df1,df2] , keys = ['df1','df2']) # 加keys参数可以在合并之后看到数据来源 # 重置索引 pd.concat([df1,df2] , keys = ['df1','df2']).reset_index() pd.concat([df1,df2] , keys = ['df1','df2']).reset_index().drop(labels ='level_1', axis = 1).rename(columns = {'level_0':'Class'})

# 如果df2数据集中的“姓名变量为Name” df2 = pd.DataFrame({ 'Name':['丁一','赵五'], 'age':[23,22], 'gender':['女','女']} ) # 数据集的纵向合并 pd.concat([df1,df2]) # concat行合并,数据源的变量名称完全相同(变量名顺序没有要求)
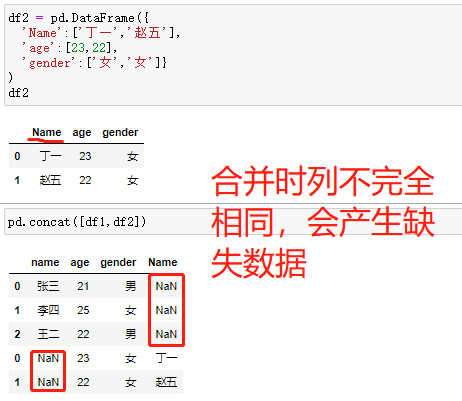
数据连接(横向)
pd.merge(left,right,how='inner',on=None,left_on=None, right_on=None,left_index=False,right_index=False,sort=False, suffixes=('_x','_y')) # 参数说明 1.left:需要连接的主表 2.right:需要连接的辅表 3.how:连接方式,默认为inner——内连接,还有其他方式,left——左连接,right——右连接,outer——外连接 4.on:连接两张表的共同字段 5.left_on:主表中需要连接的共同字段 6.right_on:辅表中需要连接的共同字段 7.left_index:bool类型,是否将主表中的行索引用作连接的共同字段 8.right_index:bool类型,是否将辅表中的行索引用作连接的共同字段 9.sort:bool类型,是否对连接后的数据按照共同字段排序,默认为False 10.suffixes:对于数据连接结果中重复的变量名,分别增加后缀加以区分
数据准备
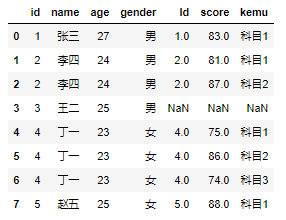
'''案例''' # 构造数据集 df3 = pd.DataFrame({ 'id':[1,2,3,4,5], 'name':['张三','李四','王二','丁一','赵五'], 'age':[27,24,25,23,25], 'gender':['男','男','男','女','女']}) df4 = pd.DataFrame({ 'Id':[1,2,2,4,4,4,5], 'score':[83,81,87,75,86,74,88], 'kemu':['科目1','科目1','科目2','科目1','科目2','科目3','科目1']}) df5 = pd.DataFrame({ 'id':[1,3,5], 'name':['张三','王二','赵五'], 'income':[13500,18000,15000]})
d3与d4连接
merge1 = pd.merge(left = df3, right = df4, how = 'left', left_on='id', right_on='Id')
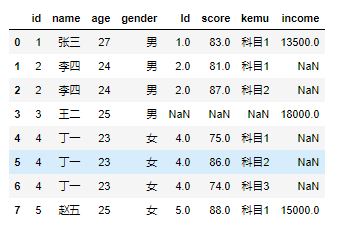
上表与d5连接
merge2 = pd.merge(left = merge1, right = df5, how = 'left')
-
pandas实战案例
1、分析NBA各球队冠军次数及球员FMVP次数
# 返回列表,其中是当前页面的所有表格数据 res = pd.read_html('https://baike.baidu.com/item/NBA%E6%80%BB%E5%86%A0%E5%86%9B/2173192?fr=aladdin') type(res) # 返回列表,获取需要的有效数据即可 champion = res[0]
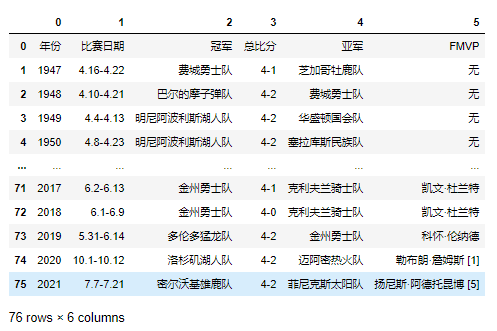
# 处理列字段名称:将第一行数据设置为表头,再删除第一行 champion.rename(columns=champion.iloc[0],inplace=True) champion.drop(0,inplace=True)
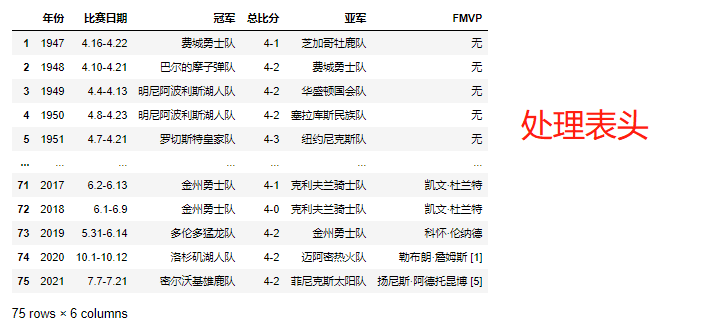
# 针对冠军字段分组 champion.groupby('冠军').groups

# 获取分组后各组大小 champion.groupby('冠军').size() champion.groupby(by='冠军').aggregate({'冠军':np.size})


# 获取各组获得冠军的次数 ascending=False(降序)/True(升序) champion.groupby('冠军').size().sort_values(ascending=False)

# 支持一次性按多个字段分组 champion.groupby(['冠军','FMVP']).size()

-
可视化模块之matplotlib
matplotlib是一个强大的Python绘图与数据可视化工具包,数据可视化是数据分析重要步骤之一,可以帮助我们分析出更多有价值的信息,可视化也是分析流程的最后一个阶段。
matplotlib也是第三方模块,需要下载 # python开发环境 pip3 install matplotlib # anaconda环境下 conda install matplotlib # 导入模块 import matplotlib.pyplot as plt
绘制饼图
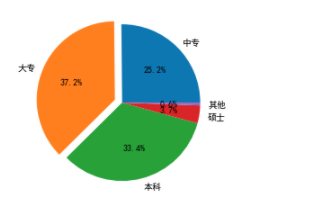
在工作中如果遇到需要计算总费用或金额的各个部分构成比例的情况,一般都是通过各个部分与总额相除来计算,而且这种比例表示方法很抽象,我们可以使用一种饼形图表工具,能够直接以图形的方式直接显示各个组成部分所占比例。
pie(x,explode=None,labels=None,colors=None,autopct=None, pctdistance=0.6,labeldistance=1.1) # 参数说明 1.x:需要绘制的数据 2.explode:饼图突出显示的部分,爆炸式 3.labels:标签说明,图例 4.colors:饼图填充颜色 5.autopct:百分比显示,可以按照一定格式 6.pctdistance:百分比显示与圆心的距离 7.labeldistance:扇形标签(图例)与圆心的距离
数据准备
'''案例''' # 导入第三方模块 import matplotlib.pyplot as plt # 解决中文乱码情况 plt.rcParams['font.sans-serif'] = ['SimHei'] # 构造数据 edu = [0.2515,0.3724,0.3336,0.0368,0.0057] labels = ['中专','大专','本科','硕士','其他'] explode = [0,0.1,0,0,0]
绘图
# 如果python版本较低可能是扁的需要加该行 # plt.axes(aspect='equal') plt.pie(x = edu, # 绘图数据 labels=labels, # 添加教育水平标签 autopct='%.1f%%', # 设置百分比的格式,这里保留一位小数 explode = explode ) # 显示图形 plt.show()
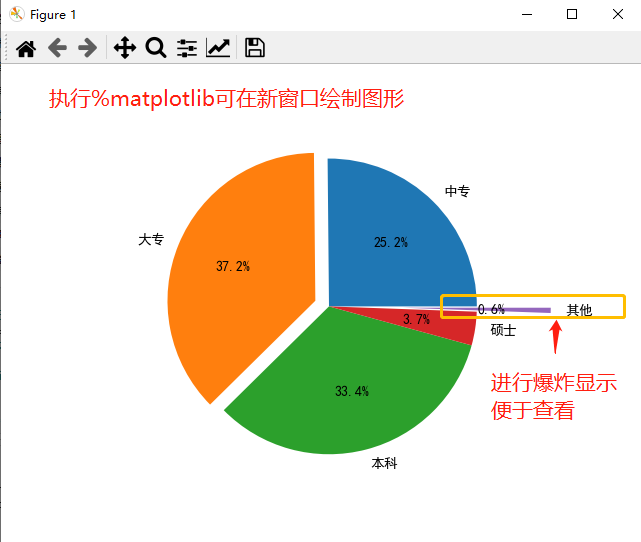
绘制条形图
饼图不适用于对比差异不大或水平值过多的离散型变量,因为饼图是通过各扇形面积的大小来比价差异的,面积的比较有时并不直观。
条形图对比的是柱形的高低,柱体越高,代表的数值越大;柱体越小,代表的数值越小。
bar(x,height,width=0.8,bottom=None,color=None,edgecolor=None, tick_label=None,label=None,ecolor=None) # 参数说明 1.x:数值序列,即x轴刻度值 2.height:数值序列,即y轴高度 3.width:条形图宽度,默认为0.8 4.bottom:堆叠条形图 5.color:条形图填充颜色 6.edgecolor:条形图边框颜色 7.tick_label:x轴刻度标签 8.label:y轴标签,图例
数据准备
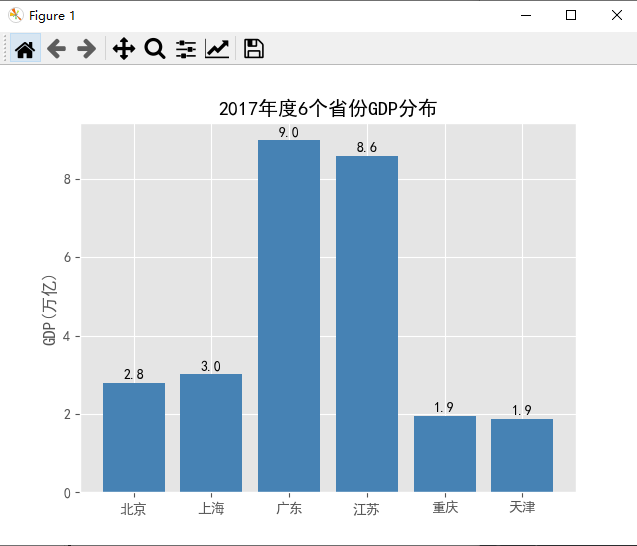
'''案例''' import pandas as pd import matplotlib.pyplot as plt # 读入数据 GDP = pd.read_excel(r'Province GDP 2017.xlsx')
绘图
# 设置绘图风格(不妨使用R语言中的ggplot2风格) plt.style.use('ggplot') # 绘制条形图 plt.bar(x = range(GDP.shape[0]), # 指定条形图x轴的刻度值 height = GDP.GDP, # 指定条形图y轴的数值 tick_label = GDP.Province, # 指定条形图x轴的刻度标签 color = 'steelblue', # 指定条形图的填充色 ) # 添加y轴的标签 plt.label('GDP(万亿)') # 添加条形图的标题 plt.title('2017年度6个省份GDP分布') # 为每个条形图添加数值标签 for x,y in enumerate(GDP.GDP): plt.text(x,y+0.1,'%s' %round(y,1),ha='center') # 显示图形 plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号