

Pandas模块(上)(Series)
概要
主体:数据分析三剑客之pandas操作表格库
-
pandas模块简介
-
pandas两大数据结构(Series、DataFrame)

-
pandas模块简介
pandas主要功能
1、具备诸多功能的两大数据结构——Series、DataFrame >>> 两种数据结构都是基于Numpy构建的,在公司中DataFrame使用频繁,Series是构成DataFrame的基础,即一个DataFrame由多个Series构成。
2、集成时间序列功能。
3、提供丰富的数学运算和操作(基于Numpy)。
-
pandas两大数据结构(Series、DataFrame)
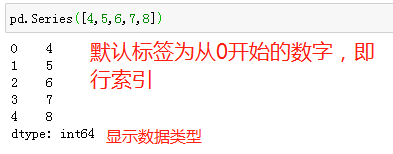

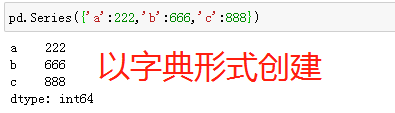
3、以字典的形式创建Series对象
pd.Series({"a":1,"b":2})
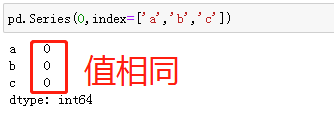
缺失数据
数据分析一般以NaN表示缺失数据。
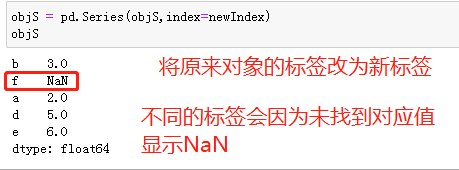
1、先新建一个Series
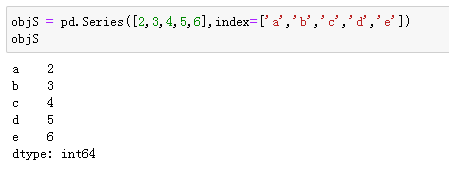
2、使用一组新的标签,与原标签不同

3、切换成新的标签,没有对应值的标签的值显示为NaN,即not a number
NaN属于浮点型!
和数组相同,Series中数据出现不同数据类型时数据均会统一转换成其中精度高的那个类型
'''
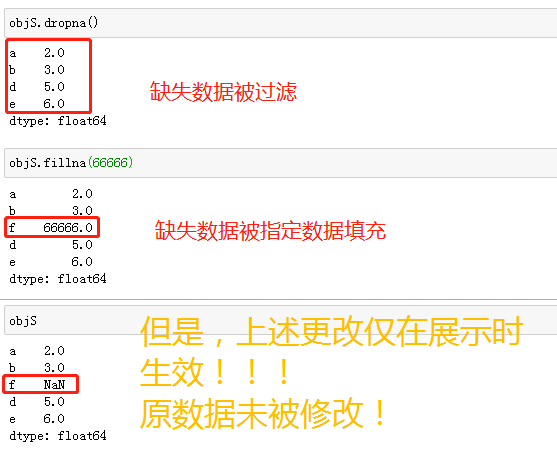
针对缺失数据,有以下方法可供使用
''' dropna() # 过滤掉值为NaN的行 fillna() # 填充缺失数据 isnull() # 返回布尔数组 notnull() # 返回布尔数组

数据修改规则
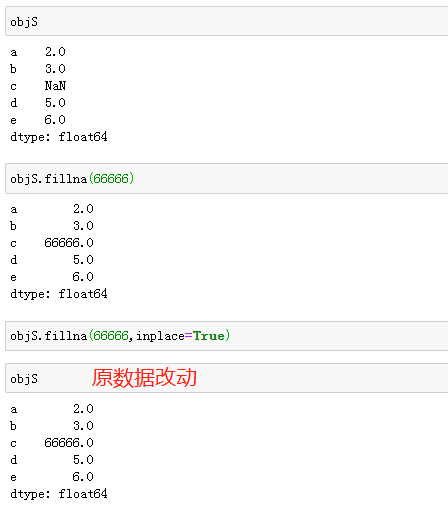
如果要修改原Series的缺失数据,需要先判断原数据是否被更改。
判断方法:
1、执行操作后有结果展示,说明原数据未被更改。
2、执行操作后无结果展示,说明原数据已被更改。

修改原数据:在方法的参数中加入inplace=True即可,很多方法都具有这个参数。
布尔值索引
本质:按照对应关系筛选出True对应的数据。
# 条件 mask = pd.Series([True,False,False,True,False]) # 待判断的序列 price = pd.Series([321312,123,324,5654,645]) price[mask]

# 条件用|表示或关系 price|mask # 条件之间用&表示与关系,条件需要加括号 (price>200) & (price<900) # 将条件放入[]内可求值 price[(price>200) & (price<900)]

行索引/标签
假设存在这样一个Series,直接按照索引取值可能会报错。因为行索引和标签名有冲突。
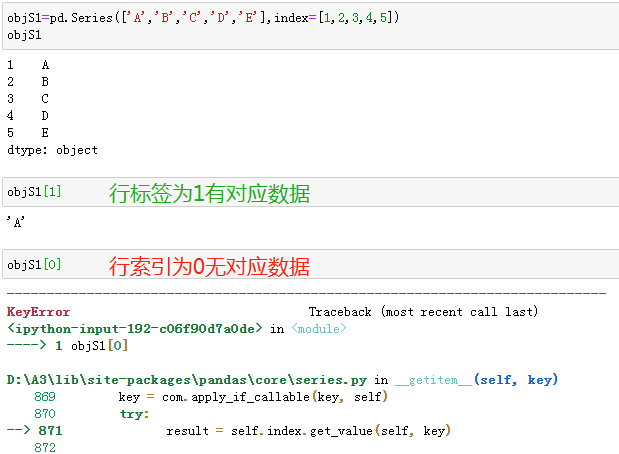
为了避免这种情况,可以手动指定按索引取值还是按标签名取值。
'''手动指定取值方式''' objS1.iloc[0] # 以行索引取值 objS1.loc[1] # 以行标签取值


 浙公网安备 33010602011771号
浙公网安备 33010602011771号