

Python操作Excel文件
-
python操作表格
-
爬取豆瓣电影top250数据并写入表格

详情
-
python操作表格
1.excel文件的后缀名有两种,03版本之前为.xls,03版本之后为.xlsx
2、能利用Python代码操作Excel表格文件的模块有很多
(1).openpyxl模块:近几年较流行,可用于操作03年之后的版本,对于老版本的兼容性不好
(2).xlrd、xlwt模块:分别控制Excel文件的读和写,可操作任何版本的表格
3、Excel本质并不是一个文件,通过将其后缀改为.zip可知,是由多个文件组成的文件夹,类似于网页
# openpyxl模块并不是内置模块,需要从其他地址下载 pip3 install openpyxl

# 首先需要引入模块的创建Excel表格文件的方法 from openpyxl import Workbook # 1.创建一个Workbook对象(Excel文件) wb = Workbook # 2.创建工作表(一个或多个) ws1 = wb1.create_sheet('第一张表') ws2 = wb1.create_sheet('第二张表') # 3.保存文件 wb.save(r'001.xlsx')
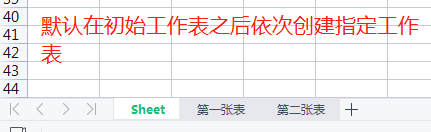

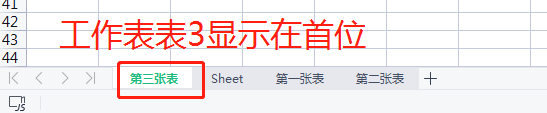
# 创建工作表的时候可以指定顺序 ws3 = wb1.create_sheet('第三张表', 0)
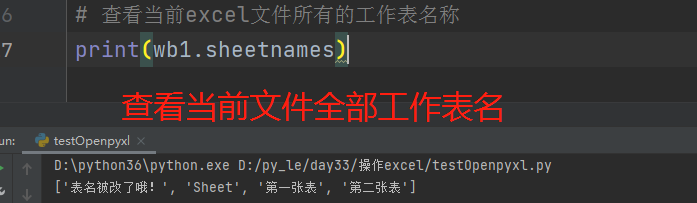
# create_sheet方法返回当前被创建的工作表对象 1.可以二次修改工作表名字 ws3.title = '表名被改了哦!' 2.可以修改工作表名称的样式 ws3.sheet_properties.tabColor = "1072BA" 3.可以查看当前excel文件所有的工作表名称,返回列表 print(wb1.sheetnames)

创建表相当于文件操作中的写模式(w),会将原有内容全部删除再重新创建新内容!!!
# 引入创建Excel表格文件的方法 from openpyxl import Workbook # 创建一个Workbook对象(Excel文件) wb2 = Workbook() ws2 = wb.create_sheet('数据统计', 0) 写入方式1 工作表对象名['单元格名'] = 值 eg: ws2['A1'] = 111 ws2['A2'] = 222 写入方式2 # cell表示单元格对象 工作表对象名.cell(column=列序, row=行序, value=值) eg: ws2.cell(column=2, row=3, value=2233) 写入方式3 # 适用于批量写入数据,空值用None或者''代替 工作表对象名.append([列1, 列2, 列3, 列4]) eg: ws2.append(['序号', '姓名', '年龄', '性别']) ws2.append([1, 'Leoric', '', 'male']) ws2.append([2, None, 18, 'female']) '''append方法按照行录入数据''' 也可以写入计算公式 eg: ws2['A9'] = '=SUM(A2:A8)' # 保存文件 wb2.save(r'002.xlsx')

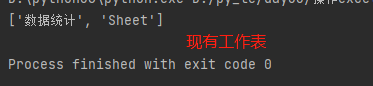
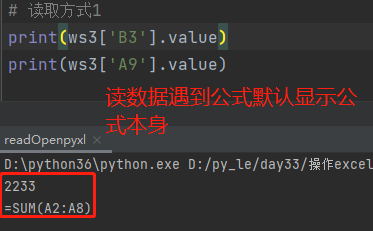
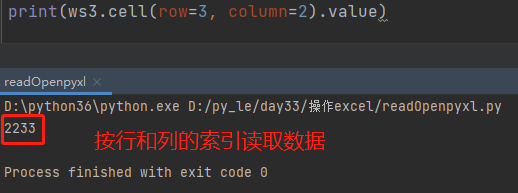
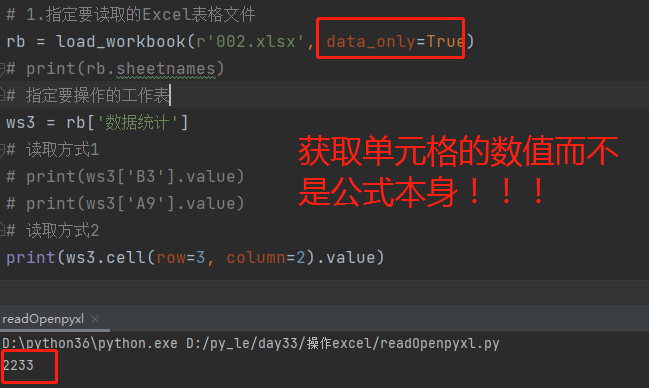
# 引入加载Excel表格文件的方法 from openpyxl import load_workbook # 1.指定要读取的Excel表格文件 rb = load_workbook(r'2.xlsx') # 2.查看全部工作表名,选择要操作的表 print(rb.sheetnames) # 3.指定要操作的工作表 ws3 = rb['数据统计'] 读取方式1 工作表对象名['单元格名'].value eg: ws3['B3'].value # 2233 ws3['A9'].value # =SUM(A2:A8) 读取方式2 工作表对象名.cell(row=行序,column=列序).value *************************************************** 按行读取 for row in ws3.rows: for r in row: print(r.value) 按列读取 for col in ws3.columns: for c in col: print(c.value)
-
爬取豆瓣电影top250数据并写入表格
1.先查看网页源代码,发现电影主要信息都在源代码中,说明这部分数据是直接加载的,向其发送get请求
2.分析返回的页面,利用bs4模块或者正则表达式筛选数据即可
3.将筛选出的字段利用openpyxl模块写入Excel文件
4.分析切换页的地址变化,只有表示起始位置的参数不同
5.外层添加for循环即可


import time from openpyxl import Workbook import requests from bs4 import BeautifulSoup import re def getMovies(n, ws): """ 获得豆瓣电影top250 参数 n: 页码 """ # 1.指定基础网址 baseUrl = 'https://movie.douban.com/top250?start={}'.format(n * 25) # 2.发送get请求获得豆瓣电影top250首页 res = requests.get(baseUrl, headers={ 'referer': 'https://movie.douban.com/top250?start=0', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36' }) # 3.构造针对豆瓣电影top250首页的解析器 soup = BeautifulSoup(res.text, 'lxml') # 4.获取电影列表的祖先标签 class为item的div标签 divItemTags = soup.select('div.item') # 5.循环存放电影的li标签 for movie in divItemTags: time.sleep(1) # 6.获取电影名称 title = movie.span.text # 7.获取电影导演和主演混合的文本 dmText = movie.select('div.bd')[0].p.text # 8.获取导演姓名 director = re.findall('导演: (.*?) ', dmText)[0] # 9.获取主演姓名(可能为空) mainActor = '' if len(re.findall('主演: (.*?) ', dmText)) > 0: mainActor = re.findall('主演: (.*?) ', dmText)[0] # 10.获取评分 ratingNum = movie.select('span.rating_num')[0].text # 11.获取评价人数 ratingCount = movie.select('div.star span')[3].text # 12.获取座右铭(可能为空) motto = '' if len(movie.select('p.quote>span.inq')) > 0: motto = movie.select('p.quote>span.inq')[0].text # 13.将电影相关信息添加至excel文件相关表末尾 ws.append([title, director, mainActor, ratingNum, ratingCount, motto]) """爬取电影排行""" # 1.新建excel文件对象 wbMovie = Workbook() # 2.创建工作表 ws250 = wbMovie.create_sheet('豆瓣电影top250') # 3.定义表头 ws250.append(['电影名称', '导演姓名', '主演姓名', '评分', '评价人数', '座右铭']) # 4.输入需要的页数 pageNum = int(input('想看几页的电影排行:').strip()) # 5.调用方法 for page in range(pageNum): getMovies(int(page), ws250) # 6.保存表格文件 wbMovie.save(r'豆瓣电影top250_{}.xlsx'.format(time.strftime('%Y-%m-%d')))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号