

网络爬虫理论
概要
-
获取数据的途径
-
爬虫及其分类
-
网页组成(HTML)
详细
-
获取数据的途径
常见的数据收集网站
1、免费查找
1.百度指数 https://index.baidu.com/v2/index.html 主要反映出各个关键字在百度的搜索起来趋势,以及各行各业发展情况。
2.新浪指数 # 微指数 https://data.weibo.com/index 是新浪微博的数据分析工具,通过关键字热议度以及行业/类别影响力,来反映微博舆情或账号的发展情况。 主要分为热词指数和影响力指数两大块,还能查看热议人群及账号地域分布情况。

3.国家数据/中国政府网 http://www.gov.cn/shuju/index.htm 是各级政府在互联网上发布政务信息和提供在线服务的综合平台。 # 数据来源于统计局 促进政务公开,改进公共服务,提高行政效能, 便于公众知情、参与和监督。
4.世界银行 https://data.worldbank.org.cn/ 主要用于获取世界各国的发展数据。
5.纳斯达克 https://www.nasdaq.com/zh/market-activity 世界上主要的股票市场中成长速度最快的市场 首家电子化的股票市场
6.联合国 http://data.un.org/ 世界上重要的数据库,涵盖政治、经济、人口、交通、能源等方面。可分为基本数据和国家概况,资料丰富,从网络上查阅到数据

2、需要付费
支付一定费用让专业的数据工作者收集数据并整理
# 国内 1.艾瑞咨询 https://www.iresearch.com.cn/ 着重于市场研究
# 国际 可能速度较慢 2.埃森哲:https://www.accenture.com/cn-zh 麦肯锡:https://www.mckinsey.com.cn/ # 第三方平台 3.数据堂 https://www.datatang.com/ 为客户提供涵盖语音、图像、文本等全类型人工智能数据定制服务及解决方案 贵阳大数据 # 暂时打不开 http://gbdex.bdgstore.cn/
-
爬虫及其分类
爬虫理论
# 了解爬虫之前不妨先来了解一下互联网 1.什么是互联网? 互联网是由网络设备(网线、路由器、交换机、防火墙等)和一台台计算机连接而成,形成的一张巨大的网。 2.互联网建立的核心目的? 互联网的核心价值就在于数据的共享/传输,数据存放在计算机上,将多台计算机互联能大幅提升数据的共享/传输的效率。 # 若无互联网,获取数据就必须去到达计算机的物理所在地 3.什么是上网? 上网的本质是由用户端的计算机向目标计算机发送请求并将存放在其内部的数据传输到本地的过程。 4.爬虫做什么? 爬虫是通过代码模拟网络请求(人的行为)获取并分析数据最后保存的过程。# 比人为查找数据的效率高 5.爬虫的价值? 互联网 -> 蜘蛛网 数据 -> 猎物 爬虫程序 -> 想要顺着蜘蛛网捕猎的小蜘蛛
其中数据是最重要的
如天猫商城的商品信息
链家网的租房信息
雪球网的证券投资信息
掌握了爬虫技能,就掌握了行业第一手资料,你就是行业的主宰。
爬虫的分类
# 通用爬虫:搜索引擎使用的爬虫系统 尽可能把互联网上所有的网页下载放到本地服务器形成备份,再对其进行相应的处理(如提取关键字、去除广告等),在组成检索结果提供给用户 1.搜索引擎获取url的过程 (1)主动向搜索引擎提供 https://ziyuan.baidu.com/site/index (2)在其他网站设置外链 # 各种友情链接 (3)与DNS服务商合作(域名解析) ping URL -t 2.并不是什么都能爬,需要遵循robots协议 协议内会指明可以爬取网页的那些部分 (...百度快照...) 3.工作流程 爬取网页 -> 存储数据 -> 内容处理 ->提供检索/排名 排名根据网站的流量统计 (1) 点击、浏览量、人气... (2) 支付一定的费用提高排名 # 聚焦爬虫 爬虫相关程序员写的有针对内容的爬虫
-
网页组成(HTML)
# HTML的全称为超文本标记语言 我们使用浏览器看到的界面其实是通过HTML代码展现的。爬虫程序就是从大量HTML代码中筛选需要的数据 # 前端 与用户直接交互的界面。 # 后端 由程序员编写的实现程序内部业务逻辑的代码,不直接与用户打交道。 '''前端一般由三种语言构成''' 1.HTML 超文本标记语言 构成网页的整体 作用: 通过这些标签可以将网络上的文档格式统一 2.CSS 层叠样式表 构成网页的样式 作用: 对网页中元素位置的排版进行像素级精确控制 3.JavaScript(JS) 是一种脚本语言 构成网页的动态效果 作用: 为网页添加各式各样的动态功能 为用户提供更流畅美观的浏览效果
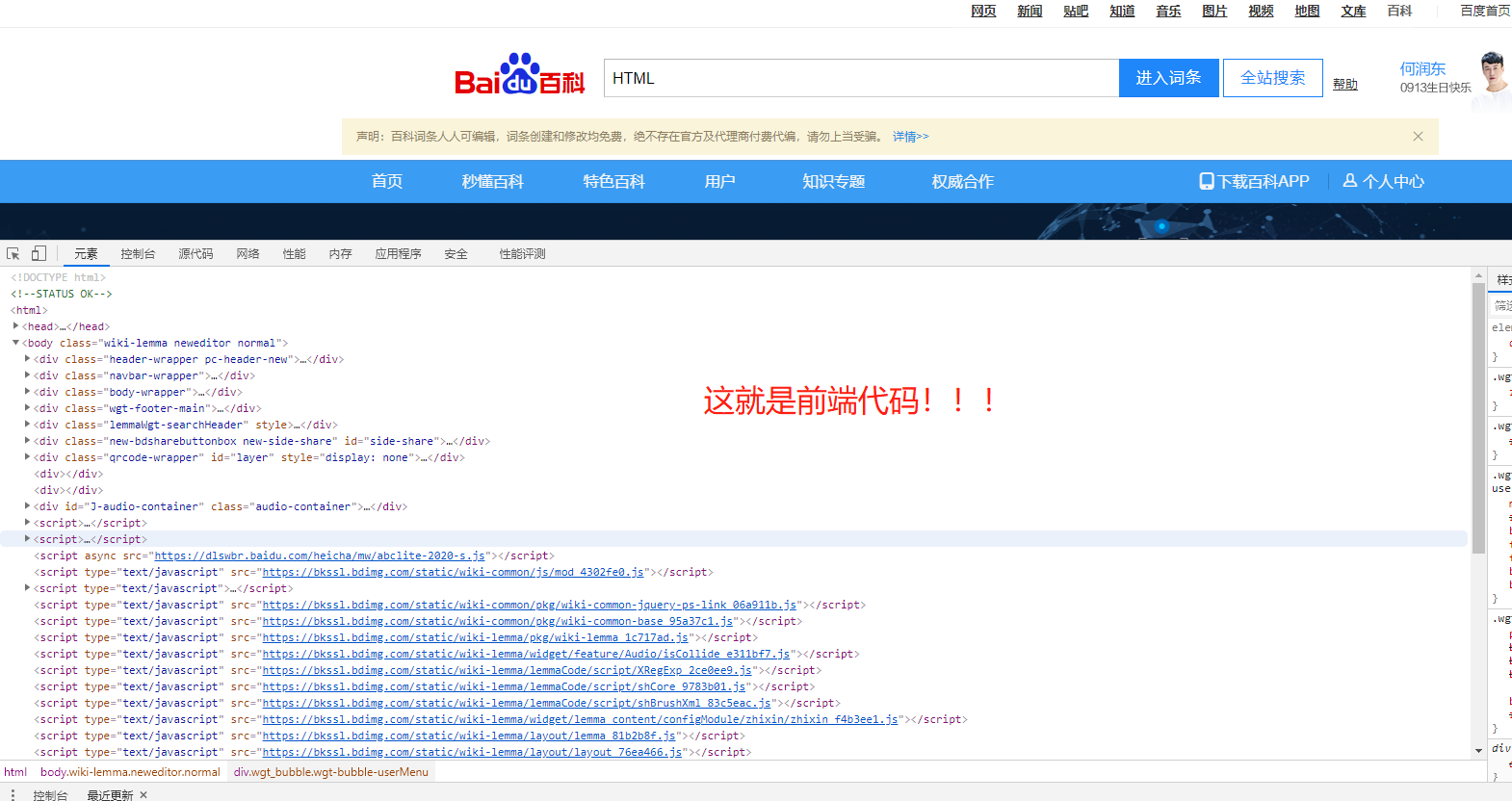
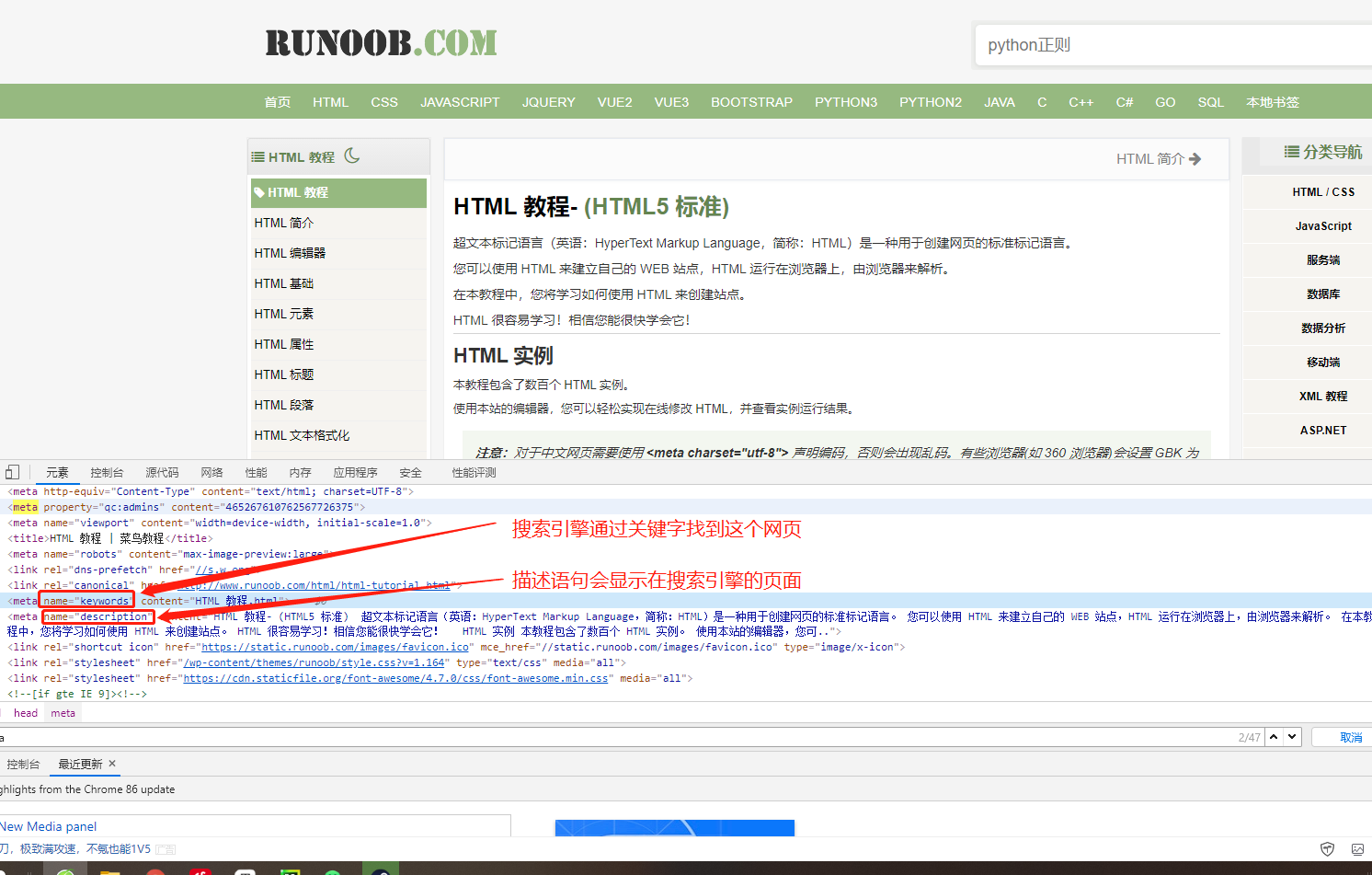
网页文件一般都以.html结尾 <!-- 语法 --> <html> <head>供浏览器识别的数据</head> <body>展现给用户的数据</body> </html> <!-- head部分常见标签 --> <title>定义网页标题</title> <style>css代码</style> <link>引入外部css文件 <script>js代码或者引入js文件</script> <meta>定义网页源信息 eg: <!-- 关键字 --> <meta name="keywords" content="HTML 教程,html"> <!-- 摘要/描述 --> <meta name="description" content="HTML 教程- (HTML5 标准) 超文本标记语言(英语:HyperText Markup Language,简称:HTML)是一种用于创建网页的标准标记语言。 您可以使用 HTML 来建立自己的 WEB 站点,HTML 运行在浏览器上,由浏览器来解析。 在本教程中,您将学习如何使用 HTML 来创建站点。 HTML 很容易学习!相信您能很快学会它! HTML 实例 本教程包含了数百个 HTML 实例。 使用本站的编辑器,您可..">
body常见标签
<!-- html标签分类 --> 1.双标签(有头有尾) <a></a> 2.单标签(自闭和) <img> <!-- 基本标签 --> <h1></h1> ~ <h6></h6>大小各不相同的标题 <a></a>网页链接 <img>图像 <u></u>下划线 <s></s>删除线 <i></i>斜体字 <b></b>粗体字 <p></p>段落 <hr>水平分割线 <br>换行

 浙公网安备 33010602011771号
浙公网安备 33010602011771号