文件操作补充与函数(上)
概要
详情
一、字符编码
字符编码记录了人类的文字与二进制数的对应关系,为相互转换提供参照。
'国内的windows电脑默认使用的字符编码是GBK'
ASCII记录英文与二进制数的对应关系
八个二进制位(8bit)对应一个字节(1bytes)
#所以的英文符号加起来不超过127个字符(7bit)
1.这里多保留一位以作备用
2.在二进制下8位换算更加方便
GBK码记录英文、中文与二进制数的对应关系
英文字符用8bit(1bytes)保存
中文字符用16bit(2bytes)保存
#由于汉字数量庞大,生僻字需要用更多的位数来保存
unicode码兼容多国语言
所有的字符都是用16bit(2bytes)保存
#使英文字符的读写效率降低
UTF-8码(unicode优化后)
英文字符用8bit(1bytes)保存
中文字符用24bit(3bytes)保存
#由上可知 目前文本文件默认使用的编码是UTF-8,乱码问题主要由编码与解码使用的字符编码不一致导致。
二、编码与解码
#python中只有字符串类型数据可以编码
字符串.encode('字符编码')
若字符串只由英文和数字构成则可以简写
eg: b'Hello World'
#python中只有二进制类型数据可以解码
二进制数据.decode('字符编码')
#基于网络传输的数据只能为二进制类型
1.文件操作的方法补充
.flush()
将内存中的数据保存至硬盘,与ctrl+s相同
.readable(),.writeable()
判断文件是否可读、是否可写
.writelines(参数)
按照参数将其中多个元素依次写入
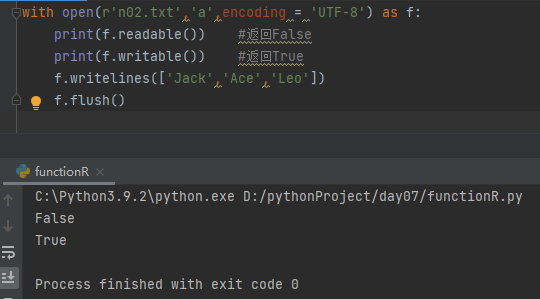
with open(r'n02.txt', 'a', encoding='UTF-8') as f:
print(f.readable()) #返回False
print(f.writable()) #返回True
f.writelines(['Jack', 'Ace', 'Leo'])
f.flush()
2.光标移动 .seek(offset,whence)
1.offset参数表示光标移动次数,以字节为单位
2.whence参数表示操作模式
whence=0:文本文件或二进制文件中均可使用,光标移动至文件开头
whence=1:只能在二进制文件中使用,光标在当前位置
whence=2:只能在二进制文件中使用,光标移动至文件末
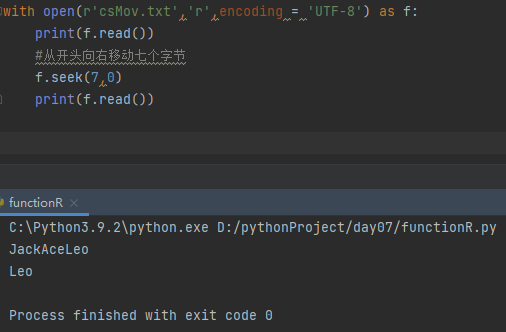
with open(r'csMov.txt','r',encoding = 'UTF-8') as f:
print(f.read())
#从开头向右移动7个字节
f.seek(7,0)
print(f.read())
with open(r'csMov.txt','rb') as f:
print(f.read())
#从末尾向左移动4个字节
f.seek(-4,2)
print(f.read())
#.read(x):参数x表示读取几个字节
3.文件修改
#方法一:将源文件内容抹除,写入新内容.(文件内容过大时不推荐使用)
with open(r'aaa.txt','r',encoding = 'UTF-8') as f:
data = f.read()
with open(r'aaa.txt','w',encoding = 'UTF-8') as f:
#replace():参数2代替参数1
f.write(data.replace('a','b'))
#方法二:创建新文件,将源文件修改后的内容写入新文件,随后删除源文件,将新文件命名为旧文件.
import os
with open(r'aaa.txt','r',encoding = 'UTF-8') as oldF,open(r'aaa.txt.backend','w',encoding = 'UTF-8') as newF:
for line in oldF:
newF.write(line.replace('b','C'))
os.remove(r'aaa.txt')
os.rename(r'aaa.txt.backend',r'aaa.txt')
def 函数名(参数1,参数2)
'''函数的注释'''
函数体
return 函数返回值
def getUserInfo ():
'''该函数用于返回输入的用户信息'''
newUserName = input('用户名>>>').strip()
newPasswd = input('密码>>>').strip()
return '%s|%s' % (newUserName,newPasswd)
作业
用户信息表(注册、登录功能结合函数优化)
![]()
![]()
def getUserInfo():
'''返回输入的用户信息'''
newUserName = input('用户名>>>').strip()
newPasswd = input('密码>>>').strip()
userInfo = [newUserName, newPasswd]
return userInfo
def register():
'''该函数用于注册用户'''
#1.用户输入用户名和密码
userInfo = getUserInfo()
#2.校验用户名是否重复
flag = False
with open(r'userInfo.txt', 'r', encoding = 'UTF-8') as f:
#循环读取每一行用户数据
for line in f:
userName = line.split('|')[0]
if userInfo[0] == userName:
print('用户名已存在!')
break
else:
flag = True
#3.如果用户名不重复,写入用户信息
if flag == True:
with open(r'userInfo.txt', 'a', encoding = 'UTF-8') as f:
userStr = '%s|%s\n' % (userInfo[0], userInfo[1])
f.write(userStr)
print('注册成功')
return
def logIn():
'''该函数用于用户登录'''
#1.用户输入用户名和密码
userInfo = getUserInfo()
#2.校验用户名和密码是否都正确
with open(r'userInfo.txt', 'r', encoding = 'UTF-8') as f:
for line in f:
realName,realPasswd = line.split('|')
if userInfo[0] == realName and userInfo[1] == realPasswd.strip():
print('登录成功!')
break
else:
print('用户名或密码错误')
return
'''用户信息表注册与登录的优化版本'''
while True:
flag = input('请选择你需要的功能:1.注册 2.登录>>>')
if flag == '1':
register()
elif flag == '2':
logIn()
else:
print('该功能不存在,请重新输入')
View Code





 浙公网安备 33010602011771号
浙公网安备 33010602011771号