

本篇博客为系列博客第二篇,主要介绍非线性最小二乘相关内容,线性最小二乘介绍请参见SLAM中的优化理论(一)—— 线性最小二乘。本篇博客期望通过下降法和信任区域法引出高斯牛顿和LM两种常用的非线性优化方法。博客中主要内容为:
- 非线性最小二乘介绍;
- 下降法相关理论(Desent Method);
- 信任区域理论(Trust Region Methods);
- 非线性最小二乘求解方法(高斯牛顿、LM)
由于个人水平有限,文中难免有解释不清晰的地方,因此希望大家结合着[1]、[2]和[3]进行理解。如果在阅读过程中发现有任何错误烦请告知。
如果有人知道如何将word中编辑的公式直接复制到博客上也麻烦给我说一下。
1. 非线性最小二乘介绍
1.1. 最小二乘问题回顾:
在上一篇博客中我们知道最小二乘问题是为了找到测量值和模型预测值之间的最小误差,该问题可以简单的表示为:

其中e(x)为模型和样本之间的误差,在SLAM中亦可以看作为观测值和估计值之间的误差。通过求解该问题我们就能够优化我们的模型函数使之更接近与真实的函数模型。
下图的数据拟合可以很好的说明最小二乘问题的结果和效果。

1.2. 线性与非线性最小二乘
假如该问题为线性的我们可以直接对目标函数求导,并且令其等于零,以此求得其极值,并通过比较求取全局最小值(Global Minimizer),并将其最为目标函数的解。
但是如果问题为非线性,此时我们通常无法直接写出其导数形式(函数过于复杂),因此我们不再去试图直接找到全局最小值,而是退而求其次通过不停的迭代计算寻找到函数的局部最小值(Local Minimizer),并认为该局部最小值能够使得我们的目标函数取得最优解(最小值),这就是非线性最小二乘的通常求解思路。
1.3. 非线性最小二乘相关定义
我们可以定义非线性最小二乘问题形式为:
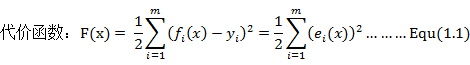
同时我们定义局部最小值满足以下定义:

![]() 可理解为局部最小值的搜索区域,对于每一次的迭代,局部最小值与当前迭代的初始值之差不应超出设定的搜索区域。
可理解为局部最小值的搜索区域,对于每一次的迭代,局部最小值与当前迭代的初始值之差不应超出设定的搜索区域。
现在我们将代价函数在点处进行泰勒展开有:
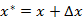
假设x为局部最小值,即使足够小,我们也将无法找到一个点x+△x,使得其对应的函数值小于x处的函数值。因此我们也可以得到以下结论:

同时我们也将所有满足令函数在其处一阶导等于零的点为驻点(Stationary Point)。

综上所述,我们知道局部最小值为函数的驻点,但是驻点同时也有肯能为函数的局部最大值或者鞍点(saddle point)。因此为区分某一个点到底是局部最小值、局部最大值或者是鞍点,我们在需要保留泰勒展开式的二阶信息。通过判定展开式中的H(Hessian)矩阵的相关性质进行判定:

现在我们已经对非线性最小二乘问题的相关概念定义有了基本了解,因此接下来介绍两种通用的求解思想和相关算法。
2. 下降法
几乎所有求解非线性优化的方法都是从一个函数的初始值( )开始求解得到一些列的值(
)开始求解得到一些列的值( ),并希望最后函数收敛于局部最小值(
),并希望最后函数收敛于局部最小值(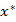 )。因此,我们能够得到函数的下降条件为:
)。因此,我们能够得到函数的下降条件为:
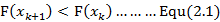
该条件可以使得函数最后不收敛于局部最大值,并且可以再一定程度上使得函数尽可能小概率的收敛于鞍点。
不过在实际操作当中,函数最后收敛于哪个局部最小值在很大程度上是取决于我们的初始值的,下图可以直观的表示这种影响。这也是在SLAM中为什么我们期望尽可能为后端优化得到一个准确的初始值的原因。不过因为本篇博客是为了讲解优化方法的因此并不会深入讨论如何获取到精确的初始值。

2.1. 下降法计算流程
下降法满足上面所提到的公式2.1中的条件,且每一步迭代中都主要包括两部分内容,分别是求解下降方向 和合理的步长
和合理的步长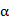 。
。
因此下降法的整体流程如下,参考[1]。
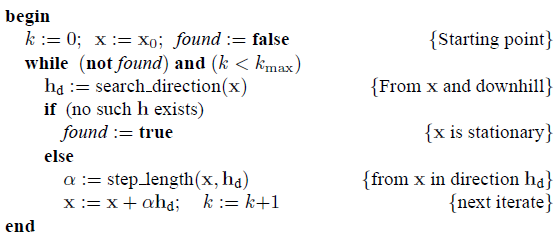
该流程从给定的初始值开始,在每一步迭代中首先计算下降的方向,然后在计算合理的步长,步长计算采用line search方法。最后根据下降方向和步长产生△x,并与此次迭代的初始值x相加得到下次迭代的初始值 。以此类推直到最后找到收敛值后,停止计算。
。以此类推直到最后找到收敛值后,停止计算。
为了进一步说明该方法的相关内容我们参考公式1.2对函数进行一阶泰勒展开:

在此处我们将公式1.2中的△x拆解为和分别代表函数的下降步长和方向。
2.2. 下降方向
因为h为函数的下降方向,因此如果函数 是一个关于的下降函数,且
是一个关于的下降函数,且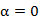 ,那么我们就能得到如下定义:
,那么我们就能得到如下定义:

即我们可以发现,函数的下降方向将永远为函数的负梯度方向。该结论亦可通过下面两张图进行直观的说明。
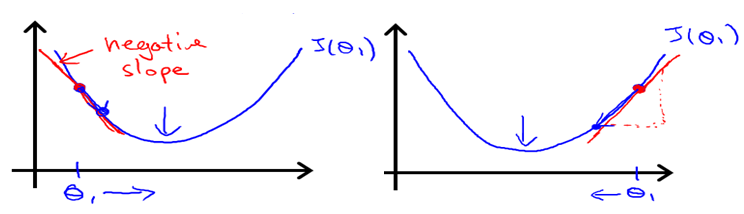
如上图所示,如果当前迭代点在全局最小值左侧,函数的梯度方向为y正x负,但是实际求解出来的下降方向为y负x正,正好与梯度方向相反。迭代点在全局最小值右侧的情况也是一样的。因此可以证明定义3。
2.3. 下降步长
现在我们已经能够明确下降的方向h了,接着我们需要去计算下降的步长。下降的步长可以告诉在此次迭代中我们应该沿着下降方向h走多远使得函数的值降低到一个合适的值。下降的步长计算方法有很多其中一种为line search方法, 具体形式为:
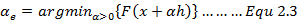
该公式是指在已知下降方向h后,我们通过求取函数F的最小值来反向求解出此次迭代的步长值,此处 为最后求解得到的步长值,且该值必须大于0。
为最后求解得到的步长值,且该值必须大于0。
Line Search方法的基本思想可以解释为每一次都会去尝试一个步长,并使用该步长沿着下降方向走,并检测函数值是否会下降到一定程度。如果没有,则按比例减小,并重复之前步骤知道满足条件。
由于line search方法存在计算量大等一些问题在SLAM中其实运用的并不是太多(牛顿法和高斯牛顿法直接默认步长为1),因此在此处不再对line search方法进行进一步探究。
2.4. 最速下降法
前面已经对下降法的内容进行了介绍,了解这些概念后再来看看最速下降法算法就会比较好理解。
最速下降法与前面所述的下降法最大的不同就是其下降方向为:
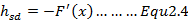
该结论是通过相对增益方程推导出来的,即对于一个下降方向为h步长为的函数,其相对增益函数为:

角度theta为h和F一阶导之间的向量夹角。如果theta=pi我们就能够公式2.4所示的最快下降方向了。
然后在通过line search方法计算出来步长就能够得到某一次迭代的更新增量△x,从而也能够得到更新后的x值。之后再重复以上步骤不停迭代知道满足条件收敛。
最速下降法虽然每次都是找的局部的最优下降方向,但是其快速性只能在局部中体现出来,从全局来看其计算速度反而比较慢,因此最速下降法在实际的SLAM计算中也并不会使用。不过了解该方法和背后的理论可以帮助我们理解后面其他算法的相关内容。
3. 信任区域法 (Trust Region Methods)
假设我们有一个模型L,在当前迭代点x附近,该模型可以被近似为函数F形式的二阶泰勒展开式,则我们有:
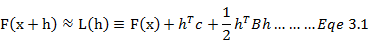
此处我们用h替代变量,即当前迭代中需要在初始x上增加的量。
但是这个近似假设的成立是有一定程度限制的,我们可以设立一个正值变量△使得模型在一个以x为圆心为半径的圆中被视为可以精确近似。这个圆就是我们所说的信任区域。然后我们就可以基于以下公式求解变化值h:

该公式表示,在信任区域半径限制内,求解出最优的变化值h是的模型L的值最小。
但是在计算过程中,可信任区域半径值是会不停改变的,其改变的依据为模型的近似质量,模型的近似质量又可以通过增益比例(gain ration)进行判定。
首先我们定义增益比例的概念。增益比例为实际函数改变量和模型该变量之间的差异,数学表达式为:
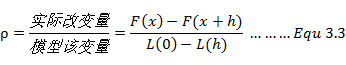
当我们得到增益比例后我们就可以通过它去实时控制可信任区域半径以及迭代的步长:
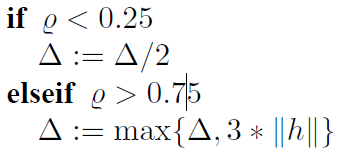
如果增益比例过小(例如小于0.25),说明实际改变的量远远小于近似模型的值,此时近似情况并不理想,因此我们需要缩小近似范围。反之如果比例较大,说明实际下降的比预期的更大,近似情况比较好,我们可以适当放大一下近似范围。
以上就是信任区域法的简单介绍,其具体应用和计算我们将会在下文中的L-M算法中进行介绍。
4. 非线性最小二乘问题计算
为了后面表述方便,首先我们再简单回顾一下非线性最小二乘问题,并对问题中变量符号进行定义。非线性最小二乘问题目的为求解代价函数的最优解(局部最小值)使得函数的值最小:

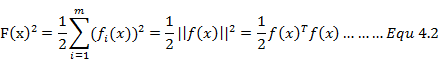
上面公式中,函数 为我们需要求解的代价函数(目标函数),f(x)是由模型函数与测量值之差构成,
为我们需要求解的代价函数(目标函数),f(x)是由模型函数与测量值之差构成,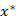 为代价函数的局部最小值也是我们最终需要求解的值。
为代价函数的局部最小值也是我们最终需要求解的值。
4.1. 高斯牛顿法
高斯牛顿法是一种求解非线性最小二乘的简单算法,该算法的基本思想是将函数非线性F(x)进行一阶泰勒展开(此处我们展开的只是函数F(x)而非代价函数):

此处J(x)为函数的雅克比矩阵,即函数F的一阶导。
根据前面所述我们的目的其实就是求解合适的变量值△x使得函数的值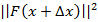 达到最小。
达到最小。
为了实现这个目的我们可以依照前面的框架构建一个最小二乘问题,即:


现在我们将通过x求解函数F(x)的最小值问题转换为了通过△x求解函数F(x+△x)最小值的问题,同时目标函数也转换为![]() 。
。
现在我们将目标函数展开有:
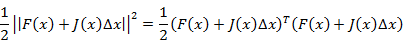
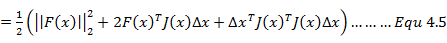
为了求解其极值我们需要对式4.5求导并令其等于零。
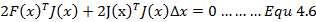

由公式4.7我们将能够得到一个关于△x的线性方程组,我们称这个方程为高斯牛顿方程。如果我们将J(x)看做为A将F(x)看做为b,函数也可以写成为:
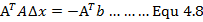
我们会发现公式4.8与上一篇博客中所讲的最小二乘的正规方程解一模一样,因此公式4.7也被成为正规方程。
同时更进一步,因为高斯牛顿法其实是第二章中下降法的一种,为了明白两者间的关系,我们可以讲增量拆分为下降方向h和下降步长. 然后我们从公式4.7能够发现,该公式的下降方向满足下降法的约束,即沿着函数梯度的负方向,而步长则等于为1.
明白公式4.7的相关意义后,我们将其进行简化:
![]()
此处的H矩阵其实是Hessian矩阵的近似,通过雅克比矩阵去避免掉真是的Hessian矩阵的计算。
基于以上内容我们能够得到高斯牛顿算法的执行步骤,参考[2]:

在整个高斯牛顿算法中,增量方程即方程4.9的求解是最为主要的。根据本文前面所提到的,我们为了保证所求解的x为函数的局部最小值,我们需要保证H矩阵为正定的,但是在实际中H矩阵很有可能是半正定的或者其他情况,因此可能会发生算法不收敛或结果不准确的情况。
因为高斯牛顿算法有以上这些缺点因此在SLAM的实际优化问题中我们更多的是使用后文提到的LM算法。
4.2. Levenberg-Marquardt Method
LM算法大致与高斯牛顿算法理论相同,但是不同于高斯牛顿算法,LM算法是基于信赖区域理论(Trust Region Method)进行计算的。这是因为高斯牛顿法中的泰勒展开只有在展开点附近才会有比较好的效果,因此为了确保近似的准确性我们需要设定一个具有一定半径的区域作为信赖区域(和第三节中的信赖区域理论道理相同)。
同第三节中所述相同,采用信赖区域法我们就需要明确该区域该怎么确定。在LM算法中信赖区大小的确定也是运用增益比例来进行判定的(参考公式3.3):
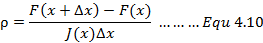
基于信赖区域我们能够重新构建一个更有效的优化框架,参考[2]。

我们引入拉格朗日乘子将该有约束优化问题转化为无约束优化问题后我们能够得到:

因为D=I,又有:

公式4.13就是LM算法的增量表达式。通过该式计算就可以避免掉高斯牛顿算法中出现的不收敛等问题。
参考内容:
[1]. Methods for Non-linear Least Squares Problems
[2]. 视觉SLAM十四讲
[3]. Multiple View Geometry in Computer Vision, Appendix 6, Iterative Estimation Methods
[4]. 机器学习.Lecture 2(吴恩达)
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号