
在SLAM的后端优化中有存在这两大类优化方法:滤波器优化和非线性优化.目前大多数基于视觉的SLAM算法都是采用的非线性优化的相关方法(如应用较多的G2O图优化框架).但是滤波器的方法仍然在某些情况下有应用,且以前不少论文都是基于滤波器优化的方法设计的SLAM算法.因此学习滤波器优化的方法对于做SLAM算法相关的研究还是有很大的意义的.
卡尔曼滤波(KF)和扩展卡尔曼滤波(EKF)是一类常用的滤波器优化方法.本文主要翻译一片国外的博客,以较为易懂的方式介绍卡尔曼滤波器的结构以及背后的数学原理.如果各位英文不错还是比较推荐直接看英文原文,博客的原地址为:http://www.bzarg.com/p/how-a-kalman-filter-works-in-pictures/#mathybits
除了这篇文章以外个人认为以下这几篇文章也写的非常好,推荐阅读:
1. The Extended Kalman Filter: An Interactive Tutorial for Non-Experts
这篇文章通俗易懂,还配有大量的交互式图形小程序帮助大家理解各个参数对整个系统的影响,非常适合入门.同时该文章还配有matlab代码和C++代码.
2. Tutorial: The Kalman Filter - MIT
这是一篇MIT课程上的tutorial.比较深入的讲解了KF滤波器背后的一些原理.
3. KF, EKF and SLAM course in MATLAB
该课程授课教师为MATLAB SLAM TOOLBOX的作者。在该课程上详细讲解了KF和EKF的相关理论以及EKF-SLAM的实现方法,对于大家深入了解EKF以及EKFSLAM相关理论(稀疏矩阵,反向深度,反向模型)都有很大帮助(附带KF、EKF以及EKFSLAM Matlab代码以及对应视频)。
4. Probabilistic Robotics - Chpter 3
最后强烈推荐一下概率机器人,里面的卡尔曼滤波这一章讲的非常的好,如果各位有时间强烈建议读一下.
以下为翻译内容(略有更改) - How a Kalman filter works, in picture
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
1. 使用卡尔曼滤波器的目的
我们假设你建造了一个可以在树林里行走的小机器人,为了精准的进行导航,机器人需要每时每刻都知道它自己的位置

我们用符号![]() 来表示机器人的状态变量,在此处我们假设状态变量只包含机器人的位置和速度:
来表示机器人的状态变量,在此处我们假设状态变量只包含机器人的位置和速度:

需要注意的是,状态只是一列和你系统有关的变量,它可以是任何的变量,不仅限于位置和速度(例如可以将引擎的温度,操作人员的手指在触摸板上的位置等变量作为系统的状态变量,只要这些变量的状态是可跟踪的).
在制造这个机器人的时候,我们在它上面也安装了一些传感器,其中就包括GPS.机器人上的GPSD定位精度为10m,但是由于树林中存在一些障碍物以及洼地,悬崖我们需求更高精度的定位能力,否则机器人就有可能撞到障碍物或者是跌落.

同时,我们也知道一些与机器人运动相关的信息(变量):知道控制端口发送至机器人驱动轮上的命令,知道机器人的正方向朝向以及前方有无障碍物等.但是很明显,我们无法获取到有关机器人运动的所有信息(变量):机器人有可能收到强风影响,驱动轮可能打滑等.因此仅仅是通过计量驱动轮转动圈数无法准确的计算出机器人走了有多远.
同理,GPS能够非直接的告诉我们一些机器人的状态,但是GPS所提供的信息也是带有误差和不确定行的.因此如果只是依据GPS做出的预测也是不够精确的.
虽然单一的依靠某一种信息无法给我们提供一个具有足够置信度的结果,但是如果我们将所有有用的信息结合在一起,我们能否在不依赖机器人自身以外的传感器得到一个比较的预测结果呢?答案当然是肯定的,这就是卡尔曼滤波器的设计目的.
2. 卡尔曼滤波器
同上,我们将继续用位置和速度来代表机器人的状态:

由于不确定性的存在,机器人当前时刻的位置和速度值存在很多可能的可能性,我们无法知道准确的值.但是某中可能性的概率相较于其他会更大,如下图所示:

卡尔曼滤波器假设所有变量(在此例中为位置和速度)都满足随机的高斯分布.每一个变量都有均值u来代表随机分布的中心点,![]() 符号代表了不确定性.关于这两个变量的解释如下图所示:
符号代表了不确定性.关于这两个变量的解释如下图所示:
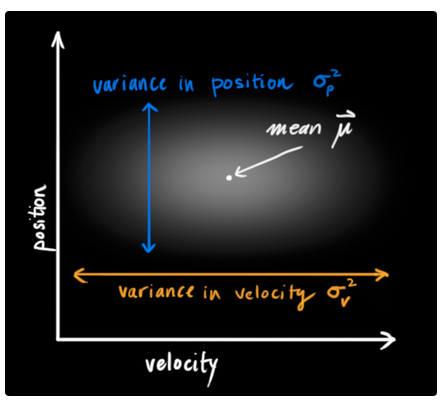
在该示意图中,位置和速度是不具有关联性的,也就是说我们无法通过位置推断得到和与速度有关的信息,反之亦然.
当位置和速度变量具有关联性时,其示意图如下所示.如图所示,观察到某一个特定位置的可能性(概率)受当前机器人的速度影响.

上图所述这种情形可能在这种情况下发生.例如,当前我们依据上一时刻的位置去预测机器人下一时刻的位置.如果机器人的运行速度较高,其移动距离也可能变的更大,从而导致计算的位置也发生较大的距离变化.反之亦然.
这种关系是十分重要的,因为它会告诉我们更多的有关信息:一个变量的状态将会反应出其他变量量的一些状态.这也是卡尔曼滤波器的目的,即我们希望尽量的从具有不确定性的信息中获取尽可能多的有用信息.
在之后计算过程中我们用协方差矩阵(covariance matrix)来代表和描述这种关联关系.即Σij描述了第i个状态变量与第j个状态变量之间的关联性.协方差矩阵通常用符号Σ表示,其中的元素表示为Σij.

3. 用矩阵方式表述问题
现在我们运用高斯来表述状态量(位置与速度)的情况,因此对于当前时刻k机器人的状态我们需要通过两个变量进行定义:
1. 估计值![]() - 各状态量的均值,也可以用符号u进行表示;
- 各状态量的均值,也可以用符号u进行表示;
2. 协方差矩阵Pk;
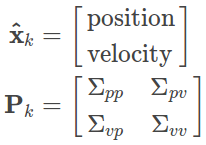
在此处我们仅仅只使用了机器人的位置和速度来表示状态量,但是在实际操作和运算中,状态矩阵的定义可以包括其他任何有用的变量.
现在,我们需要了解一下当前状态(t = k-1)和下一时刻的预测状态(t = k)的情况.我们需要注意的是,虽然我们无法明确指出当前分布中的哪一种情况是当前真实的状态,但是我们仍然可以通过预测方程得到新时刻的分布情况.因为预测方程并非只作用于某一个具体的状态量,而是作用与当前分布中所包含的所有情况.
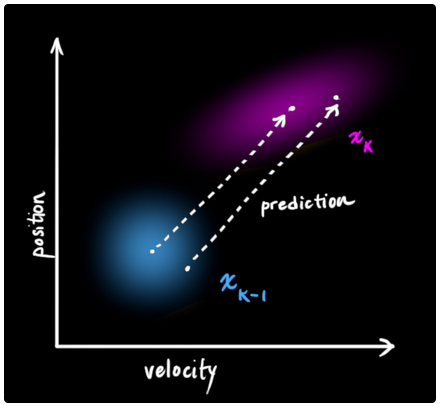
在下图中我们用矩阵Fk来表示预测步骤:

现在思考一下,我们如何运用一个矩阵来预测下一时刻机器人的位置和速度呢?在此,我们将会运用如下所示的运动学方程进行预测:
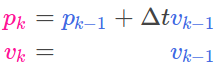
转化为矩阵形式有:
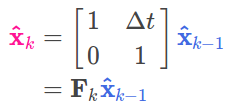
很明显,这是一个匀速运动模型,新时刻的位置P_new = P_previous + time*v .现在我们已经求得了预测矩阵(或称为状态转移矩阵),但是我们仍然不知道如何去更新协方差矩阵.
为了更新协方差矩阵,我们需要一个新的公式即:
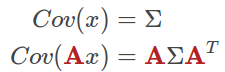
该公式表示,将当前分布中所包含的所有情形(点)乘以预测矩阵就能够得到更新或的协方差矩阵了.
以上所属内容,可以总结为以下两个公式:
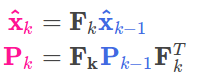
4. 外部影响
即使计算到了现在,我们也仍未囊括所有信息.因为在系统中存在这一些不随状态量变化而发生变化的变量 - 外部世界的一些因素也能对系统产生影响.
以火车运行为例,火车的操作员可能会控制运行开关使得火车加速.类似的,在此机器人的案例中,机器人导航系统可能会发出指令使得机器人驱动轮转向或停止.因此,在计算中我们需要考虑到这类变量对系统的影响.通常来说我们将这类变量称作为系统的控制变量,用符号![]() 进行表示.
进行表示.
现在我们假设对于机器人这个案例,已知其外部控制量为加速度a(由运动开关或控制命令进行控制),则之前所述的运行方程可更新为:

矩阵形式为:

其中Bk为控制矩阵,而![]() 为控制变量所组成的矩阵(n x 1).系统中的控制量只有在其已知或可获取时才加入到方程中,并不是必不可少的.
为控制变量所组成的矩阵(n x 1).系统中的控制量只有在其已知或可获取时才加入到方程中,并不是必不可少的.
现在在让我们思考另外一个问题,如果我们预测并不是一个100%精准的模型,那么将会发生什么?
5. 外部不确定性
假如我们的变量是通过系统本身的属性以及已知的外部影响而计算得到的,那么状态计算将不会有太大问题.但假如影响系统的量我们无法明确获取到他们的值呢?
仍然以我们的机器人为例,在运动过程中其驱动轮可能打滑,机器人也有可能撞到地面上的隆起物(地面凹凸不平)使速度变慢.我们很难表示或追踪这些因素所产生的影响.一旦这些情况发生,我们的预测结果就很有可能与实际结果产生很大的偏差,因为我们并未在数学模型中考虑到这些因素.
但是不用担心,在数学上对于这种情况是有解决办法的.我们在每一次的预测步骤中加入新的不确定性来表示这些世界中存在但是我们无法明确表示的变量所带来的影响.
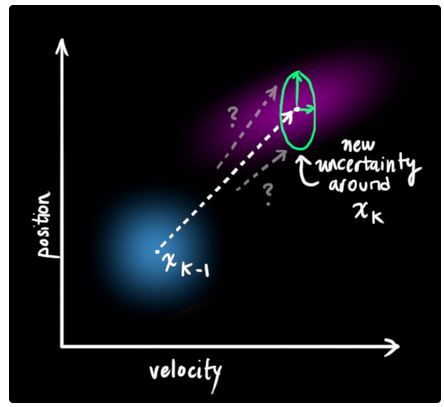
原始估计中的每个状态都会通过变换方程运动到一个新的状态范围中.
如图下所示,上一时刻状态![]() 中的每一个状态点(蓝色区域表示)都会移动到一个新的区域范围中(该范围新加入了不确定性,用绿色圆表示).也就是说,我们将世界中无法表示且会对状态变量带来不确定性的影响视作噪声(KF中通常为白噪声,协方差用
中的每一个状态点(蓝色区域表示)都会移动到一个新的区域范围中(该范围新加入了不确定性,用绿色圆表示).也就是说,我们将世界中无法表示且会对状态变量带来不确定性的影响视作噪声(KF中通常为白噪声,协方差用![]() 表示).
表示).
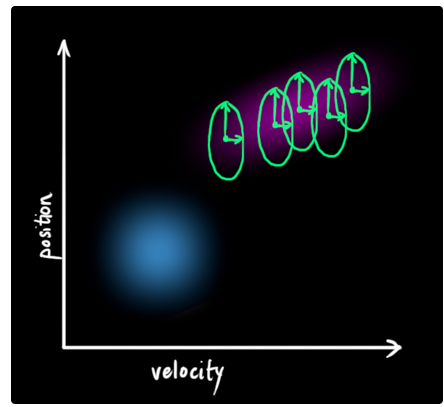
由于加入了额外的噪声协方差,因此很明显相较与之前推导中所产生的分布区域,在在这种情况下的分布区域会明显不一样.
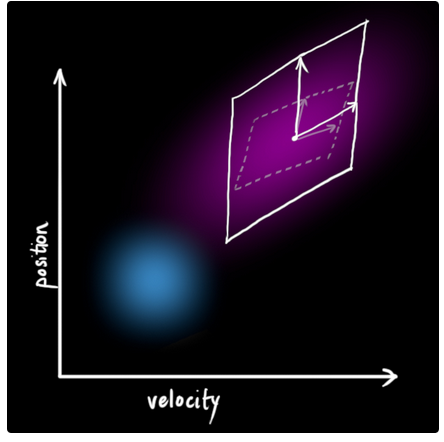
现在,让我们将新的噪声协方差加入到之前所推导出来的公式中:

这两个公式代表了卡尔曼滤波器中的预测部分,是卡尔曼滤波器五个基础公式中的前两个.其中估计值![]() 为根据上一时刻系统状态和当前时刻系统控制量所得到的系统估计值,该估计值又叫做先验估计值,为各变量高斯分布的均值.而
为根据上一时刻系统状态和当前时刻系统控制量所得到的系统估计值,该估计值又叫做先验估计值,为各变量高斯分布的均值.而![]() 为协方差矩阵,代表了不确定性,它是由上一时刻的协方差矩阵和外部噪声的协方差一起计算得到的.
为协方差矩阵,代表了不确定性,它是由上一时刻的协方差矩阵和外部噪声的协方差一起计算得到的.
好了,现在我们已经得到了系统的预测(估计)值了.但是在真是的系统中,我们往往还能通过传感器得到一些能反映系统状态的测量值.
6. 测量值(观测值)
通常我们会在机器人上安装一些传感器,这些传感器的返回值(测量量)能够让我们了解更多与机器人当前状态有关的信息.例如,我们现在有两个传感器,一个返回位置信息另一个返回速度信息.这两个传感器都能够间接的提供一些机器人运动状态的信息(sensor operate on a state and produce a set of readings).

需要注意的是,传感器返回的信息其单位和尺度可能与我们在预测步骤中所跟踪的状态量的单位和尺度有所不同.因此通常我们使用矩阵Hk来表示状态量与传感器所观测的测量量之间的关系.
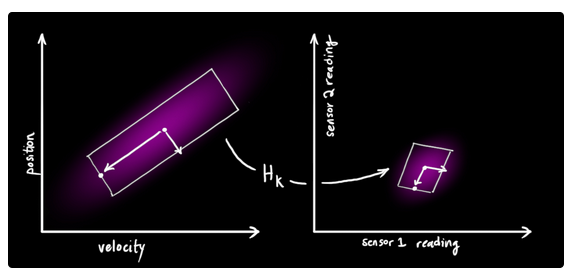
通常,我们能够计算出传感器返回值的分布情况(通过传感器出厂说明中的参数等信息):

需要注意的是卡尔曼滤波器之所以好用的一个原因就是它可以很好的处理传感器的噪声.也就是说,传感器的观测值(或测量值)是具有一定程度的不可靠性的(由噪声引起),因此传感器的读数是并非是一个精确值,而是一个带有不确定区域的范围.

通过传感器的观测,我们可以猜测我们的机器人当前所处的状态.但是因为不确定性的存在,因此某些状态比其他状态有更大的可能行被视作传感器的读数.

在卡尔曼滤波器中我们用符号![]() 来表示传感器因为噪声所带来的不确定性的协方差.而传感器观测值的均值就等于传感器读数值,通常用
来表示传感器因为噪声所带来的不确定性的协方差.而传感器观测值的均值就等于传感器读数值,通常用![]() 来进行表示.
来进行表示.
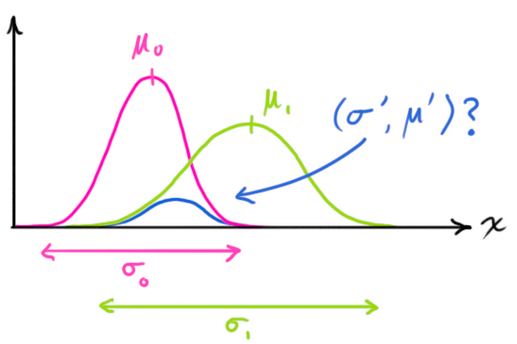
因此,现在我们有了两个不同的高斯分布:一个代表预测步骤,一个代表传感器的观测.
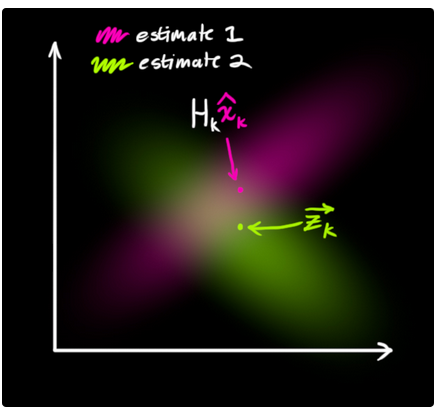
我们现在需要根据预测步骤(粉色)和传感器读数(绿色)来调整传感器读数的分布(此处是在解释后文将会提到的卡尔曼增益).
那么现在哪一种才是当前最有可能的状态情况呢?对于某一组传感器读数(Z1,Z2),我们现在有两种可能:
1. 当前的传感器测量为错误的,不可以很好的代表机器人的状态(当前机器人的状态应该完全与预测步骤的分布相同);
2. 当前的传感器测量为正确的,可以很好的代表当前机器人的状态(当前机器人的状态应该完全与传感器观测分布相同);
如果现在我们假设这两种可能行都是正确的,我们将其分布相乘,就能得到一个新的如下所示的分布:
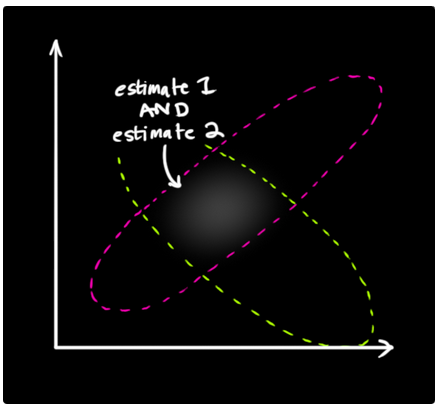
相乘后剩下的区域为高量部分,在此区域中两种假设情况都是高量.这就意味这这个新生成的分布区域比之前任一一种假设都要精确(完全相信预测步骤和完全相信传感器观测),因此该区域为对机器人当前状态的最好估计(可以用下图表示).
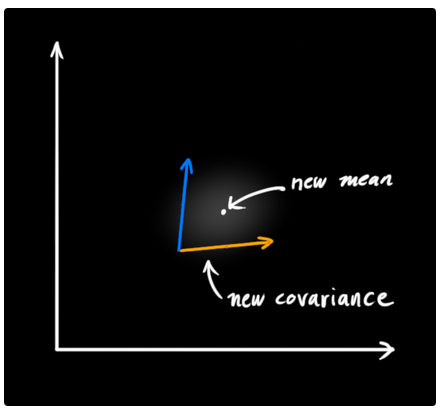
以上的表述证明了,当你讲两个具有独立的均值和协方差矩阵(seperate means and covariance matrics)的高斯分布相乘时,就能够得到一个具有新的均值和协方差矩阵的高斯分布.也许你能够发现:一定存在一个数学表达式能够通过旧的参数值计算出来这个新的参数值.
7. 结合高斯
现在我们一起来找到这个数学公公式.为了易于理解,我们首先从一维情况开始推导.一维的高斯分布可以表示为:

现在我们想要知道,当我们讲两个高斯曲线(分布)相乘时会发生什么.下图中的蓝色部分表示相乘后得到的新的高斯分布的结果.

现在我们将一阶高斯分布的公式带入到上式中有:
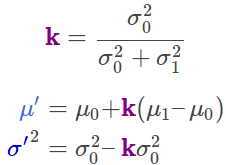
现在让我们将上式改写为矩阵形式的表达式,并令Σ为高斯分布的协方差矩阵:
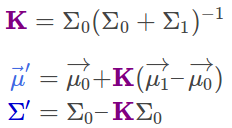
K被成为卡尔曼增益,我们将会在后面用到它.
8. 整合
我们有两个分布:预测步骤的分布为![]() ,传感器观测值的分布为
,传感器观测值的分布为![]() .我们将这两个分布带入到公式:
.我们将这两个分布带入到公式:
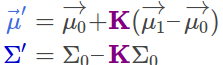
能够求解得到重叠区域:
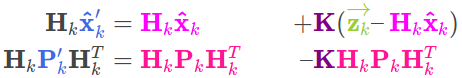
因此卡尔曼增益为:

在以上的推导过程中我们可以发现每一个变量都乘上了变量![]() ,因此可以约掉
,因此可以约掉![]() ,又发现在计算协方差矩阵时可以约掉
,又发现在计算协方差矩阵时可以约掉![]() .因此简化后的公式为:
.因此简化后的公式为:
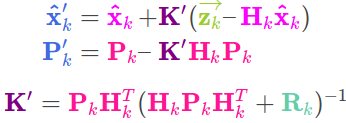
在卡尔曼滤波器中我们称这三个公式为更新步骤,这也是卡尔曼滤波器五个基本公式中的最后三个.
此处的估计值![]() 才是当前时刻机器人最后的最优估计值,而
才是当前时刻机器人最后的最优估计值,而![]() 为当前时刻机器人最有估计的协方差矩阵.这两个变量将会当成是当前时刻最后的输出值进入到下一次的卡尔曼滤波器计算过程中.
为当前时刻机器人最有估计的协方差矩阵.这两个变量将会当成是当前时刻最后的输出值进入到下一次的卡尔曼滤波器计算过程中.
卡尔曼滤波器工作流程示意图大致如下:

9. 总结
卡尔曼滤波器预算分为预测和更新两步,切具有五个基本方程:
1. 预测步骤:
2. 更新步骤


需要注意的是,卡尔曼滤波器只适用于线性系统,在真实世界中我们所面对的系统通常为非线性系统,因此工程更常用的是扩展卡尔曼滤波.扩展卡尔曼滤波与卡尔曼滤波十分相似,唯一不同点在与扩展卡尔曼滤波需要对系统进行线性化(雅克比矩阵).
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号