基于 Apache Hudi 构建增量和无限回放事件流的 OLAP 平台
1. 摘要
在本博客中,我们将讨论在构建流数据平台时如何利用 Hudi 的两个最令人难以置信的能力。
- 增量消费--每 30 分钟处理一次数据,并在我们的组织内构建每小时级别的OLAP平台
- 事件流的无限回放--利用 Hudi 的提交时间线在超级便宜的云对象存储(如 AWS S3)中存储 10 天的事件流(想象一个具有 10 天保留期的 kafka 主题)
- 具有部分记录更新的自定义 Hudi Payload 类
2. 当前状态
2.1 问题说明
对于大多数业务需要手动干预以通过查看 KPI 和数据趋势来决定下一组操作用例以及其他不太实时的用例,我们需要具有成本效益和高性能的近实时系统。
但是我们在数据湖中获得的数据通常以 D -1 的每日批处理粒度出现,即使我们每天不止一次地运行这些日常批处理数据处理系统以获取当前 D 的最新数据,这些批处理系统的固有局限性也无助于我们解决近实时业务用例。
2.2 挑战
在将批处理数据摄取到我们的数据湖时,我们支持 S3 的数据集在每日更新日期分区上进行分区。即使我们每天多次运行这些批处理系统,我们从上游 Kafka 或 RDBMS 应用程序数据库中提取的最新批处理也会附加到 S3 数据集中当前日期的分区中。
当下游系统想要从我们的 S3 数据集中获取这些最新记录时,它需要重新处理当天的所有记录,因为下游进程无法在不扫描整个数据分区的情况下从增量记录中找出已处理的记录。
此外如果我们按小时(而不是每日分区)对 S3 数据集进行分区,那么这会将分区粒度设置为每小时间隔。任何试图以低于一小时(例如最后 x 分钟)的粒度获取最新更新的下游作业都必须在每次运行时再次重新处理每小时数据分区,即这些批处理源将错过解决近实时用例所需的关键增量数据消费。
2.3 无限播放事件流
现在回到帮助我们解决这些挑战的 Apache Hudi 的特性,让我们首先尝试了解commit(提交)和commit timeline(提交时间线)如何影响增量消费和事件流保留/回放。
Hudi 维护了在不同时刻在表上执行的所有操作的时间表,这些commit(提交)包含有关作为 upsert 的一部分插入或重写的部分文件的信息,我们称之为 Hudi 的提交时间线。
对于每个 Hudi 表,我们可以选择指定要保留多少历史提交,要保留的默认提交是 10 次,即在 10 次提交之后,第 11 次提交将另外运行一个清理服务,该服务将清除第一次提交历史记录。
清理commit(提交)时,清理程序会清理与该提交对应的部分文件的过时版本,相关数据被保留,因为过时的文件中的所有数据无论如何都存在于新版本的文件中,这里重要的是我们可以触发快照查询来获取数据的最新状态,但我们将无法对已清理的提交运行增量查询来获取增量数据。
简而言之,如果清除了commit(提交),我们就失去了从该commit(提交)回放事件流的能力,但是我们仍然可以从任何尚未清理的commit(提交)中回放事件流。
在我们的例子中,我们将 Hudi 表配置为保留 10K 提交,从而为我们提供 10 天的增量读取能力(类似于保留 10 天的 kafka 主题)
我们保留的历史提交数量越多,我们就越有能力及时返回并重放事件流。
3. 每小时 OLAP
让我快速展示一下我们的端到端消息 OLAP 计算管道与 10 天事件流的架构
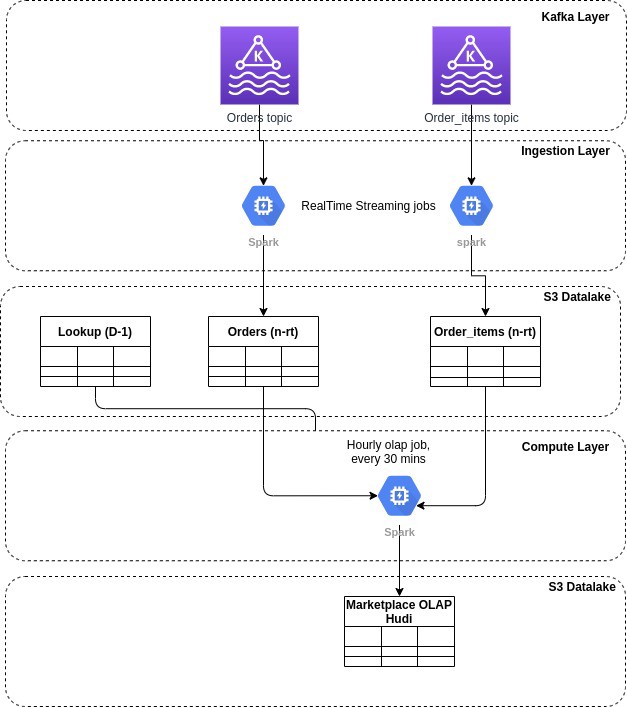
在 kafka 层,我们的 kafka 输入源每个都有 1 天的主题保留期。
在摄取层,我们有 Spark 结构化流作业,从 kafka 源读取数据并将微批处理写入 S3 支持的 Hudi 表。 这是我们配置为保持 10k 提交以启用 10 天事件流播放的地方。
.option("hoodie.cleaner.commits.retained", 10000)
.option("hoodie.keep.max.commits", 10002)
.option("hoodie.keep.min.commits", 10001)
计算层由我们当前每 30 分钟运行一次的批处理 Spark 作业组成,并重新处理我们在过去 60 分钟内摄取到 Hudi 表中的所有事件。 每小时 OLAP 作业读取两个跨国表和可选的 N 维表,并将它们全部连接起来以准备我们的 OLAP 增量DataFrame。
我们每 30 分钟处理一次 60 分钟的数据,以增强表连接的一致性。
有趣的是生产系统中通常不建议保留 1 天的 kafka 保留期,但是我们能够进行这种权衡以节省一些 SSD 和 Kafka 代理成本,因为无论如何我们都可以通过 S3 支持的 Hudi 表实现 10 天的事件流播放能力。
4. 部分记录更新
上面的管道显示了我们如何通过读取和合并两个增量上游数据源来创建每小时增量 OLAP。
然而这些增量数据处理有其自身的挑战。 可能会发生在两个上游表中,对于主键,我们在其中一个数据源中获得更新,但在另一个数据源中没有,我们称之为不匹配的交易问题。
下面的插图试图帮助我们理解这一挑战,并看看我们实施的解决方案。
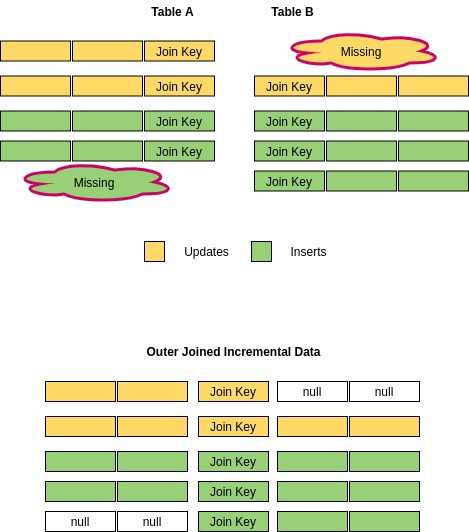
在这里,表A和B都有一些对应的匹配事务和一些不匹配的事务。使用内部连接将简单地忽略不匹配的事务,这些事务可能永远不会流入我们的基础 OLAP。相反使用外连接会将不匹配的事务合并到我们的每小时增量数据加载中。但是使用外连接会将缺失的列值添加为 null,现在这些空值将需要单独处理。
在使用默认有效负载类将此每小时增量数据更新到基础 Hudi OLAP 时,它将简单地用我们准备的每小时增量数据中的新记录覆盖基础 Hudi OLAP 中的记录。但是通过这种方式,当我们用传入记录中的空列值覆盖现有记录时,我们将丢失现有记录中可能已经存在的信息。因此为了解决这个问题,我们提供了我们的自定义部分行更新有效负载类,同时将外部连接的每小时增量数据插入到基础 Hudi OLAP。有效负载类定义了控制我们在更新记录时如何合并新旧记录的函数。
我们的自定义有效负载类比较存储和传入记录的所有列,并通过将一条记录中的空列与另一条记录中的非空列重叠来返回一条新记录。
因此即使只有一个上游表得到了更新,我们的自定义有效负载类也会使用这个部分可用的新信息,它会返回包含部分更新信息的完全最新记录。
由于存储和部分行更新记录的主键和分区键相同,因此 Hudi upsert 操作会自动更新旧记录,从而为我们提供基本 OLAP 的去重和一致视图。
有关如何编写自己的有效负载类的更多技术细节。
5. 结语
结合这三个概念,即增量消费、增量每小时 OLAP 处理和自定义部分行更新有效负载类,我们为我们的独角兽初创公司构建了一个强大的流处理平台,以使其一直扩展成为一个百角兽组织。
PS:如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,您的“推荐”,将会是我不竭的动力!
作者:leesf 掌控之中,才会成功;掌控之外,注定失败。
出处:http://www.cnblogs.com/leesf456/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
如果觉得本文对您有帮助,您可以请我喝杯咖啡!



 浙公网安备 33010602011771号
浙公网安备 33010602011771号