TCP/IP协议栈在Linux内核中的运行时序分析
前言:
本文拟基于Linux-5.4.34内核网络协议的源码分析,并执行断点追踪调试,进行TCP/IP协议栈在Linux内核中运行的时序分析。
调研要求:
1.在深入理解Linux内核任务调度(中断处理、softirq、tasklet、wq、内核线程等)机制的基础上,分析梳理send和recv过程中TCP/IP协议栈相关的运行任务实体及相互协作的时序分析。
2.编译、部署、运行、测评、原理、源代码分析、跟踪调试等
3.应该包括时序图
一、 Linux内核任务调度机制简述
在linux系统中,各个进程的执行与切换和系统的调用都是在任务调度的范围之内进行,针对于网络程序而言,涉及到很明显的分层处理,这一机制就显得尤为重要,这个时候就不得不说其调度的核心中断处理。对于中断处理而言,linux将其分成了两个部分,一个叫做中断handler(top half),即上半部,是全程关闭中断的;另外一部分是deferable task(bottom half),即下半部,属于不那么紧急需要处理的事情。在执行bottom half的时候,是开中断的。有多种bottom half的机制,例如:软中断softirq、tasklet、工作队列work queue或是直接创建一个kernel thread来执行bottom half。下面分别简述这几个实现机制。
1.软中断
软中断softirq不允许休眠阻塞,支持SMP(Symmetric MultiPcocessor),同一个softirq可以在不同CPU同时运行,且必须是可重入的,是编译期间静态分配的。kernel/softirq.c文件中定义了一个包含32个softirq_action结构体的数组,每个被注册的软终端都占据该数组的一项,因此最多可能有32个软中断。相关实现代码可表示如下:
1 //软中断描述符 2 struct softirq_action{ void (*action)(struct softirq_action *);}; 3 //描述每一种类型的软中断,其中void(*action)是软中断触发时的执行函数。 5 //软中断全局数据和类型 7 static struct softirq_action softirq_vec[NR_SOFTIRQS] __cacheline_aligned_in_smp; enum 8 { 9 HI_SOFTIRQ=0, /*用于高优先级的tasklet*/ 10 TIMER_SOFTIRQ, /*用于定时器的下半部*/ 11 NET_TX_SOFTIRQ, /*用于网络层发包*/ 12 NET_RX_SOFTIRQ, /*用于网络层收报*/ 13 BLOCK_SOFTIRQ, 14 BLOCK_IOPOLL_SOFTIRQ, 15 TASKLET_SOFTIRQ, /*用于低优先级的tasklet*/ 16 SCHED_SOFTIRQ, 17 HRTIMER_SOFTIRQ, 18 RCU_SOFTIRQ, /* Preferable RCU should always be the last softirq */ 19 NR_SOFTIRQS 20 };
相关API如下:
注册软中断
1 void open_softirq(int nr, void (*action)(struct softirq_action *))
即注册对应类型的处理函数到全局数组softirq_vec中。例如网络发包对应类型为NET_TX_SOFTIRQ的处理函数net_tx_action,这个函数在后面的物理层时序分析中会用到。
触发软中断
1 void raise_softirq(unsigned int nr)
实际上即以软中断类型nr作为偏移量置位每cpu变量irq_stat[cpu_id]的成员变量__softirq_pending,这也是同一类型软中断可以在多个cpu上并行运行的根本原因。
软中断执行函数
1 do_softirq-->__do_softirq
其特点可总结如下:
1)一个软中断不会抢占另一个软中断
2)唯一可以抢占软中断的是ISR(中断服务程序)
3)其它软中断可以在其它处理器同时执行
4)一个注册的软中断必须被标记后才执行
5)软中断不可以自己休眠(不能自己调用sleep,wait等函数)
6)索引号小的软中断在索引号大的软中断之前执行
2.tasklet
由于软中断必须使用可重入函数,这就导致设计上的复杂度变高,作为设备驱动程序的开发者来说,增加了负担。而如果某种应用并不需要在多个CPU上并行执行,那么软中断其实是没有必要的。因此诞生了弥补以上两个要求的tasklet。它具有以下特性:
1)一种特定类型的tasklet只能运行在一个CPU上,不能并行,只能串行执行。
2)多个不同类型的tasklet可以并行在多个CPU上。
3)软中断是静态分配的,在内核编译好之后,就不能改变。但tasklet就灵活许多,可以在运行时改变(比如添加模块时)。
tasklet是在两种软中断类型的基础上实现的,因此如果不需要软中断的并行特性,tasklet就是最好的选择。也就是说tasklet是软中断的一种特殊用法,即延迟情况下的串行执行。
相关描述符和数据结构定义如下:
1 //tasklet描述符 3 struct tasklet_struct 5 { struct tasklet_struct *next;//将多个tasklet链接成单向循环链表 7 unsigned long state;//TASKLET_STATE_SCHED(Tasklet is scheduled for execution) TASKLET_STATE_RUN(Tasklet is running (SMP only)) 9 atomic_t count;//0:激活tasklet 非0:禁用tasklet 11 void (*func)(unsigned long); //用户自定义函数 13 unsigned long data; //函数入参 15 }; 17 //tasklet链表 19 static DEFINE_PER_CPU(struct tasklet_head, tasklet_vec);//低优先级 21 static DEFINE_PER_CPU(struct tasklet_head, tasklet_hi_vec);//高优先级 23 //相关API 25 //定义tasklet 27 #define DECLARE_TASKLET(name, func, data) \ 29 struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(0), func, data } 31 //定义名字为name的非激活tasklet 33 #define DECLARE_TASKLET_DISABLED(name, func, data) \ 35 struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(1), func, data } 37 //定义名字为name的激活 39 taskletvoid tasklet_init(struct tasklet_struct *t,void (*func)(unsigned long), unsigned long data) 41 //动态初始化tasklet 43 //tasklet操作 45 static inline void tasklet_disable(struct tasklet_struct *t) 47 //函数暂时禁止给定的tasklet被tasklet_schedule调度,直到这个tasklet被再次被enable;若这个tasklet当前在运行, 这个函数忙等待直到这个tasklet退出 49 static inline void tasklet_enable(struct tasklet_struct *t) 51 //使能一个之前被disable的tasklet;若这个tasklet已经被调度, 它会很快运行。tasklet_enable和tasklet_disable必须匹配调用, 因为内核跟踪每个tasklet的"禁止次数" 53 static inline void tasklet_schedule(struct tasklet_struct *t) 55 //调度 tasklet 执行,如果tasklet在运行中被调度, 它在完成后会再次运行; 这保证了在其他事件被处理当中发生的事件受到应有的注意. 这个做法也允许一个 tasklet 重新调度它自己 57 tasklet_hi_schedule(struct tasklet_struct *t) 59 //和tasklet_schedule类似,只是在更高优先级执行。当软中断处理运行时, 它处理高优先级 tasklet 在其他软中断之前,只有具有低响应周期要求的驱动才应使用这个函数, 可避免其他软件中断处理引入的附加周期. 61 tasklet_kill(struct tasklet_struct *t)//确保了 tasklet 不会被再次调度来运行,通常当一个设备正被关闭或者模块卸载时被调用。如果 tasklet 正在运行, 这个函数等待直到它执
3.工作队列
工作队列(work queue)是另外一种将工作推后执行的形式,它和前面讨论的tasklet有所不同。工作队列可以把工作推后,交由一个内核线程去执行,也就是说,这个下半部分可以在进程上下文中执行。这样,通过工作队列执行的代码能占尽进程上下文的所有优势。最重要的就是工作队列允许被重新调度甚至是睡眠。这也就是的它具有自己的特性:
1)可以阻塞
2)可以重新调度
3)缺省工作者线程(kthrerad worker && kthread work)
4)在工作队列和其它内核间用锁和其它进程上下文一样
5)默认允许响应中断
6)默认不持有任何锁
工作队列和tasklet的选择比较重要,由各自的工作特性可以得知如果推后执行的任务需要睡眠,那么就选择工作队列。如果推后执行的任务不需要睡眠,那么就选择tasklet。另外,如果需要用一个可以重新调度的实体来执行你的下半部处理,也应该使用工作队列。它是唯一能在进程上下文运行的下半部实现的机制,也只有它才可以睡眠。工作队列的源码描述如下:
1 //结构体代码: 3 struct workqueue_struct { 5 struct cpu_workqueue_struct *cpu_wq; 7 //指针数组,其每个元素为per-cpu的工作队列 9 struct list_head list; const char *name; int singlethread; 11 //标记是否只创建一个工作者线程 13 nt freezeable; /* Freeze threads during suspend */ 15 int rt; 17 #ifdef CONFIG_LOCKDEP 19 struct lockdep_map lockdep_map; 21 #endif }; 23 //相关API如下: 25 //静态创建 27 DECLARE_WORK(name,function); 29 //定义正常执行的工作项 31 DECLARE_DELAYED_WORK(name,function); 33 //定义延后执行的工作项 35 动态创建 INIT_WORK(_work, _func) 37 //创建正常执行的工作项 39 INIT_DELAYED_WORK(_work, _func 41 )//创建延后执行的工作项
4.内核线程
Linux内核可以看作一个服务进程(管理软硬件资源,响应用户进程的种种合理以及不合理的请求)。内核需要多个执行流并行,为了防止可能的阻塞,支持多线程是必要的。内核线程就是内核的分身,一个分身可以处理一件特定事情。内核线程的调度由内核负责,一个内核线程处于阻塞状态时不影响其他的内核线程,因为其是调度的基本单位。这与用户线程是不一样的。因为内核线程只运行在内核态,因此,它只能使用大于PAGE_OFFSET(3G)的地址空间。内核线程和普通的进程间的区别在于内核线程没有独立的地址空间,mm指针被设置为NULL;它只在 内核空间运行,从来不切换到用户空间去;并且和普通进程一样,可以被调度,也可以被抢占。
内核线程(kernel thread)或叫守护进程(daemon),在操作系统中占据相当大的比例,当Linux操作系统启动以后,可以用"ps -ef"命令查看系统中的进程。内核线程和普通的进程间的区别在于内核线程没有独立的地址空间,它只在 内核空间运行,从来不切换到用户空间去;并且和普通进程一样,可以被调度,也可以被抢占,让模块在加载后能一直运行下去的方法。
较为熟知的和内核线程有关的而且比较重要的三个进程是idle(swapper)进程(PID = 0)、init进程(PID =1)和kthreadd(PID = 2)。idle(swapper)即交换进程由系统自动创建,运行在内核态; init进程由idle通过kernel_thread创建,在内核空间完成初始化后,加载init程序,并最终转变为用户空间的init进程;kthreadd进程由idle通过kernel_thread创建,并始终运行在内核空间,负责所有内核线程的调度和管理。
关于内核线程的主要原理以及生命周期等,不是本文研究的重点,本文研究主要在于通过内核线程来加载TCP/IP协议栈,所以接下来的一部分我们就来进行具体的分析。
二、TCP/IP协议族简述
上一部分简要介绍了Linux任务调度机制的一些方法以及内核线程先关的概念,本节主要介绍TCP/IP协议族的相关原理。
计算机网络是一种非常复杂的系统,相互通信的两个计算机系统必须高度协调工作才行,而这种高度协调过程是由网络协议来实现。网络协议(network protocol),简称为协议,是为进行网络中的数据交换而建立的规则、标准或约定。
两个计算机通信的过程非常复杂,要解决许多问题(差错控制、路由、格式转换等),为了实现这一过程,通常以分层的观点来分析网络的各个组成部分的功能,常见的分层的参考模型即为OSI参考模型和TCP/IP参考模型,下图即表示利用分层的思想来实现两个主机之间利用网络模块进行通信。
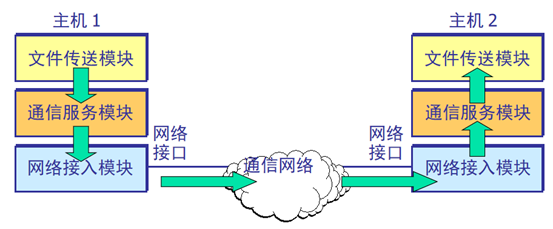
计算机网络体系结构是网络层次结构模型与各层协议的集合。服务是各层向其上层提供的一组原语。尽管服务定义了该层能够为其上层完成的操作,但没有设计这些操作是如何实现的。协议是定义在相同层次的对等实体之间交换的帧、分组和报文的格式及含义的一组规则。实体利用协议实现它们的服务定义。服务是"垂直的",协议是"水平的"。下面以两种较为流行的分层模型来阐述协议这一概念。
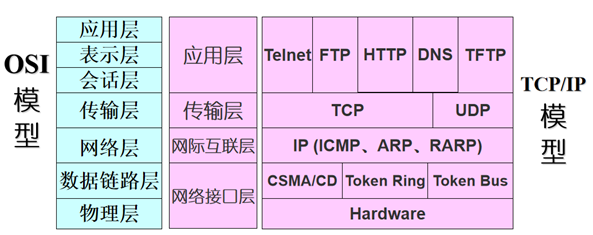
2.OSI参考模型
OSI(Open System Interconnect),即开放式系统互连。 一般都叫OSI参考模型,是ISO组织在1985年研究的网络互连模型。该体系结构标准定义了网络互连的七层框架即物理层、数据链路层、网络层、传输层、会话层、表示层和应用层,即OSI开放系统互连参考模型。各层之间的关系和功能表示如下:
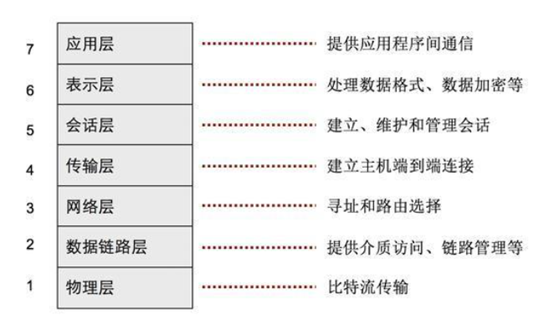
数据由传送端的最上层(通常是指应用程序)产生,由上层往下层传送。每经过一层,都在前端增加一些该层专用的信息,这些信息称为报头,然后才传给下一层,可将加上报头想象为套上一层信封。因此到了最底层时,原本的数据已经套上了七层信封,而后通过网线、电话线、光纤等介质,传送到接收端。
接收端接收到数据后,从最底层向上层传送,每经过一层就拆掉一层信封(即去除该层所认识的报头),直到最上层,数据便恢复成当初从传送端最上层产生时的原貌。
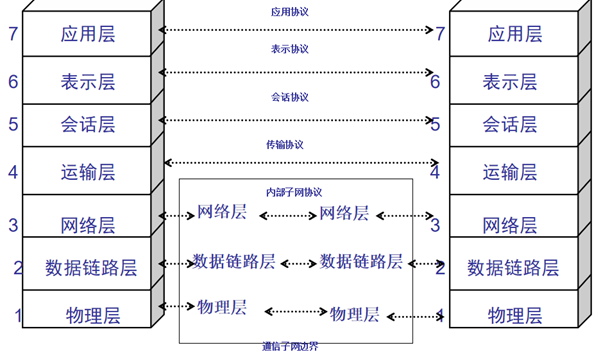
如果以网络的术语来说,这种每一层将原始数据加上报头的操作,便是数据的封装,而封装前的原始数据则称为数据承载。在传送端,上层将数据传给下层,下层将上层传过来的数据当成数据承载,再将数据承载封装成新的数据,继续传给更下层去封装,直到最底层为止。各层次之间的应用协议如下图所示。
3.TCP/IP模型
TCP/IP(Transmission Control Protocol/Internet Protocol,传输控制协议/网际协议)是指能够在多个不同网络间实现信息传输的协议簇。TCP/IP协议不仅仅指的是TCP 和IP两个协议,而是指一个由FTP、SMTP、TCP、UDP、IP等协议构成的协议簇, 只是因为在TCP/IP协议中TCP协议和IP协议最具代表性,所以被称为TCP/IP协议。
同OSI参考模型类似,TCP/IP参考模型也是采用的分层结构,但是OSI参考模型的分层过于复杂,实现起来很困难,而TCP/IP采用的是四层的分层模型,即直接分为应用层、传输层、网际层和网络接口层。各层的功能如下:应用层的功能为对客户发出的一个请求,服务器作出响应并提供相应的服务;传输层的功能为通信双方的主机提供端到端的服务,传输层对信息流具有调节作用,提供可靠性传输,确保数据到达无误;网络层功能为进行网络互连,根据网间报文IP地址,从一个网络通过路由器传到另一网络;网络接口层负责接收IP数据报,并负责把这些数据报发送到指定网络上。
它和OSI参考模型各层次对比如下:
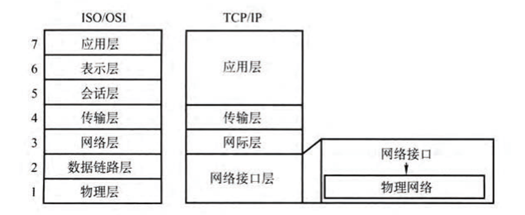
相当于上三层总结为应用层,中间二层不变,下两层转为网络接口层。这样的好处是大大的降低了网络层次结构的复杂性,相对于七层的网络结构,四层的TCP/IP模型虽然协议分层较差,封装性也不是很好,但是实现起来较为容易,所以目前较为流行,其信息发送过程可表示如下:
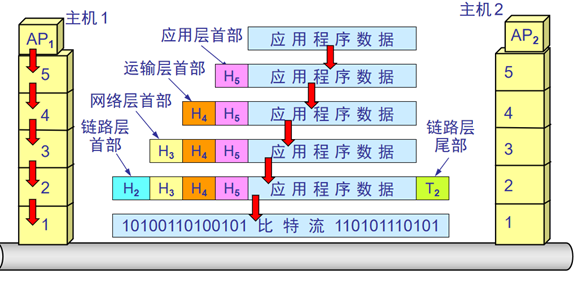
在两个主机之间发送信息的过程从上往下依然是封装和解封装的过程,这样做到了协议的一体化和实现的共同化。在通常教学中,通常将下两层分成数据链路层和物理层,形成了典型的五层结构。在实际的协议应用中,具体的一些协议对比如下:
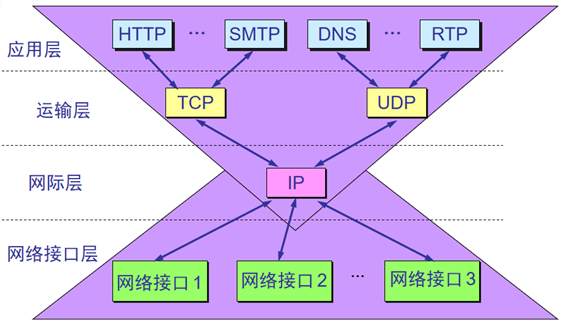
将OSI模型和TCP/IP模型中涉及到的常用的协议综合为下图所示:
以上两个即展示了较为常用的TCP/IP协议族所示的协议,这些协议在网络通信和数据传输的过程中起到了非常重要的作用,共同构成了TCP/IP协议丰富的协议栈。
4.TCP/IP协议栈的加载
TCP/IP协议栈作为Linux内核的一个软件模块嵌入到Linux内核中,从网络协议层次的角度看,大致如图,TCP/IP协议栈上面对接Socket套接口,下面对接二层链路层,即LAN或WAN网络协议及网络设备驱动。
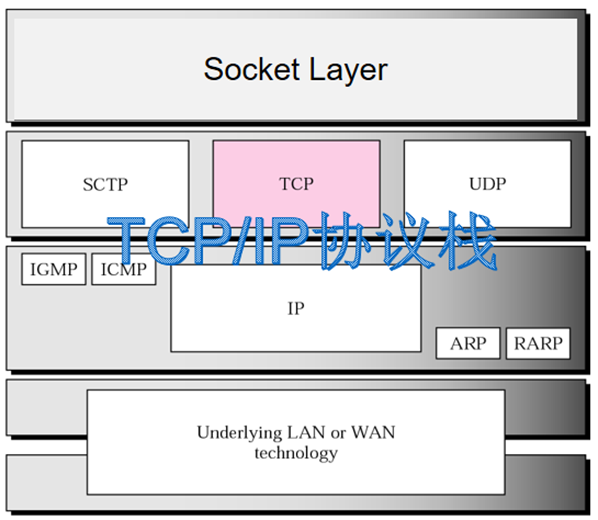
通过阅读Linux源码可知,协议栈的加载过程即可理解为函数的层层调用,具体的各个函数如下图所示:

即此处可以联系到我们上面所说的内核线程的作用,在加载TCP/IP协议栈的时候,内核线程即起到了很重要的作用,初始化协议栈同时进行系统调用,并告知各层次进行具体的歇息的处理等,进行一系列操作,完成各段的存储并找到入口地址。
三、Socket简述
socket是独立于具体协议的网络编程接口,在OSI模型中,主要位于会话层和传输层之间。Linux操作系统中的Socket基本上就是BSD Socket,需要使用的头文件定义为:
数据类型:#include <sys/types.h>
函数定义:#include <sys/socket.h>
BSD Socket(伯克利套接字)是通过标准的UNIX文件描述符和其它程序通讯的一个方法,目前已经被广泛移植到各个平台。套接字和文件类似,每个活动套接字使用一个小整数标识,进程的文件描述符和套接字描述符值不能相同,利用socket函数创建套接字描述符。
TCP网络程序调用Socket APi的次序如下图所示:
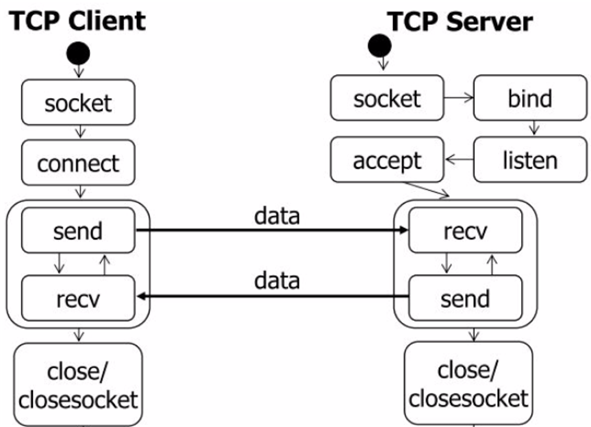
2.相关API函数
linux中的网络编程通过socket接口实现,在编程的过程中,socket提供了丰富的API函数,可以分为创建、连接、绑定、监听、接收、数据收发和关闭套接字等,这些API函数简要定义如下,使用的时候应该包含上面所说的头文件。
1 #include <sys/types.h> 3 #include <sys/socket.h> 5 //创建套接字 7 int socket( int domain, int type, int protocol) 9 /** 功能:创建一个新的套接字,返回套接字描述符 11 参数说明: 13 domain:域类型,指明使用的协议栈,如TCP/IP使用的是 PF_INET 15 type: 指明需要的服务类型, 如 17 SOCK_DGRAM: 数据报服务,UDP协议 19 SOCK_STREAM: 流服务,TCP协议 21 protocol:一般都取0 **/ 23
//建立连接 25 int connect(int sockfd,struct sockaddr *server_addr,int sockaddr_len) 27 /** 功能: 同远程服务器建立主动连接,成功时返回0,若连接失败返回-1。 29 参数说明: 31 Sockfd:套接字描述符,指明创建连接的套接字 33 Server_addr:指明远程端点:IP地址和端口号 35 sockaddr_len :地址长度 **/ 37
//绑定端口 39 int bind(int sockfd,struct sockaddr * my_addr,int addrlen) 41 /** 功能:为套接字指明一个本地端点地址TCP/IP协议使用sockaddr_in结构,包含IP地址和端口号,服务器使用它来指明熟知的端口号,然后等待连接 43 参数说明: 45 Sockfd:套接字描述符,指明创建连接的套接字 47 my_addr:本地地址,IP地址和端口号 49 addrlen :地址长度 **/ 51 //监听端口 52 53 int listen(int sockfd,int input_queue_size) 55 /** 功能:面向连接的服务器使用它将一个套接字置为被动模式,并准备接收传入连接。用于服务器,指明某个套接字连接是被动的 57 参数说明: 59 Sockfd:套接字描述符,指明创建连接的套接字 61 input_queue_size:该套接字使用的队列长度,指定在请求队列中允许的最大请求数 63 举例:listen(sockfd,20) **/ 65 //接收连接 67 int accept(int sockfd, struct sockaddr *addr, int *addrlen); 69 /** 功能:获取传入连接请求,返回新的连接的套接字描述符。为每个新的连接请求创建了一个新的套接字,服务器只对新的连接使用该套接字,原来的监听套接字接受其他的连接请求。新的连接上传输数据使用新的套接字,使用完毕,服务器将关闭这个套接字。 71 参数说明: 73 Sockfd:套接字描述符,指明正在监听的套接字 75 addr:提出连接请求的主机地址 77 addrlen:地址长度 79 举例:new_sockfd = accept(sockfd, (struct sockaddr *)&address, &addrlen); **/ 81 //数据发送 103 int send(int sockfd, const void * data, int data_len, unsigned int flags) 105 /** 功能:在TCP连接上发送数据,返回成功传送数据的长度,出错时返回-1。send会将外发数据复制到OS内核中 107 参数说明: 109 sockfd:套接字描述符 111 data:指向要发送数据的指针
113 data_len:数据长度 115 flags:一直为0 117 举例(p50):send(s,req,strlen(req),0); **/ 119 //数据接收 141 int recv(int sockfd, void *buf, int buf_len,unsigned int flags); 143 /** 功能:从TCP接收数据,返回实际接收的数据长度,出错时返回-1。服务器使用其接收客户请求,客户使用它接受服务器的应答。如果没有数据,将阻塞,如果收到的数据大于缓存的大小,多余的数据将丢弃 145 参数说明: 147 Sockfd:套接字描述符 149 Buf:指向内存块的指针 151 Buf_len:内存块大小,以字节为单位 153 flags:一般为0 155 举例:recv(sockfd,buf,8192,0)**/ 157 //关闭套接字 159 close(int sockfd); 161 /** 功能: 163 撤销套接字。如果只有一个进程使用,立即终止连接并撤销该套接字,如果多个进程共享该套接字,将引用数减一,如果引用数降到零,则撤销它。 165 参数说明: 167 Sockfd:套接字描述符 169 举例:close(socket_descriptor) **/
上三个部分介绍了linux内核任务调度相关机制、TCP/IP协议族的组成和加载以及socket的原理,本节我们结合具体的网络通信程序的代码来简要进行TCP/IP运行的时序分析。
1.应用层
应用层的各种网络应用程序基本上都是通过 Linux Socket 编程接口来和内核空间的网络协议栈通信的。通过上文的介绍我们得知Linux Socket 是从 BSD Socket 发展而来的,它是 Linux 操作系统的重要组成部分之一,它是网络应用程序的基础。从层次上来说,它位于应用层,是操作系统为应用程序员提供的 API,通过它,应用程序可以访问传输层协议。发送消息的前提是客户端和服务端已经建立起了连接。网络应用调用Socket API socket (int family, int type, int protocol) 创建一个 socket,该调用最终会调用 Linux system call socket() ,并最终调用 Linux Kernel 的 sock_create() 方法。此时便可以通过socket维护的队列来进行消息的发送和接收。
1)发送端
对于发送端而言,由于给定的代码是tcp连接,所以在源码中查看send方法,可以看到如下代码:
1 SYSCALL_DEFINE4(send, int, fd, void __user *, buff, size_t, len, 2 3 unsigned int, flags) 4 5 { 6 7 return __sys_sendto(fd, buff, len, flags, NULL, 0); 8 9 }
在这个函数中执行了socket的send方法,然后在函数下面调用了__sys_sendto函数,这个函数即为发送消息的实体。我们继续追踪这个函数,看到如下代码段:
1 int __sys_sendto(int fd, void __user *buff, size_t len, unsigned int flags, 2 3 struct sockaddr __user *addr, int addr_len) 4 5 { 6 7 struct socket *sock; 8 9 struct sockaddr_storage address; 10 11 int err; 12 13 struct msghdr msg; 14 15 struct iovec iov; 16 17 int fput_needed; 18 19 ........... 20 21 if (sock->file->f_flags & O_NONBLOCK) 22 23 flags |= MSG_DONTWAIT; 24 25 msg.msg_flags = flags; 26 27 err = sock_sendmsg(sock, &msg); 28 29 out_put: 30 31 fput_light(sock->file, fput_needed); 32 33 out: 34 35 return err; 36 37 }
在返回时调用的是sock_sendmsg函数,到这一步继续追踪,
1 int sock_sendmsg(struct socket *sock, struct msghdr *msg) 2 3 { 4 5 int err = security_socket_sendmsg(sock, msg, 6 7 msg_data_left(msg)); 8 9 return err ?: sock_sendmsg_nosec(sock, msg); 10 11 } 12 13 EXPORT_SYMBOL(sock_sendmsg); 14 15 static inline int sock_sendmsg_nosec(struct socket *sock, struct msghdr *msg) 16 17 { 18 19 int ret = INDIRECT_CALL_INET(sock->ops->sendmsg, inet6_sendmsg, 20 21 inet_sendmsg, sock, msg, 22 23 msg_data_left(msg)); 24 25 BUG_ON(ret == -EIOCBQUEUED); 26 27 return ret; 28 29 }
到sock_sendmsg_nosec这个函数,我们就可以看到sock->ops->sendmsg这个系统调用,查阅资料可知对于inet域,tcp协议sendmsg被初始化为tcp_sendmsg,tcp_sendmsg 具体负责传输层协议的操作细节,并传到网络层处理函数。所以到tcp_sendmsg为止,应用层的各个函数调用和时序过程追踪完毕,利用gdb断点调试来进行验证,结果如下图所示:
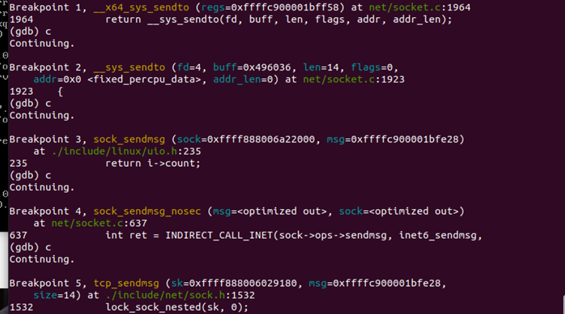
按照断点反应的调用的顺序,和我们的预期是一致的,所以也大概清楚了应用层的数据发送的时序流程。
有了上述追踪发送时序的经验,这个时候我们按照同样的做法来查看socket中的recvAPI的代码
1 SYSCALL_DEFINE4(recv, int, fd, void __user *, ubuf, size_t, size, 2 3 unsigned int, flags) 4 5 { 6 7 return __sys_recvfrom(fd, ubuf, size, flags, NULL, NULL); 8 9 }
和上次的设想差不多,还是调用了一个__sys函数,继续追踪这个函数,
1 int __sys_recvfrom(int fd, void __user *ubuf, size_t size, unsigned int flags, 2 3 struct sockaddr __user *addr, int __user *addr_len) 5 { 6 7 struct socket *sock; 8 9 struct iovec iov; 10 11 struct msghdr msg; 12 13 struct sockaddr_storage address; 14 15 int err, err2; 16 17 int fput_needed; 18 19 ........... 20 21 if (sock->file->f_flags & O_NONBLOCK) 22 23 flags |= MSG_DONTWAIT; 24 25 err = sock_recvmsg(sock, &msg, flags); 26 27 if (err >= 0 && addr != NULL) { 28 29 err2 = move_addr_to_user(&address, 30 31 msg.msg_namelen, addr, addr_len); 32 33 if (err2 < 0) 35 err = err2; 37 } 38 39 fput_light(sock->file, fput_needed); 40 41 out: 42 43 return err; 44 45 }
定位到了sock_recvmsg函数,
1 int sock_recvmsg(struct socket *sock, struct msghdr *msg, int flags) 2 3 { 4 5 int err = security_socket_recvmsg(sock, msg, msg_data_left(msg), flags); 6 7 return err ?: sock_recvmsg_nosec(sock, msg, flags); 8 9 } 10 11 EXPORT_SYMBOL(sock_recvmsg); 12 13 static inline int sock_recvmsg_nosec(struct socket *sock, struct msghdr *msg, 14 15 int flags) 16 17 { 18 19 return INDIRECT_CALL_INET(sock->ops->recvmsg, inet6_recvmsg, 20 21 inet_recvmsg, sock, msg, msg_data_left(msg), 22 23 flags); 24 25 }
然后基本上一样的代码,我们还是到了sock->ops->recvmsg这里,在inet域,tcp协议对应的recvmsg被初始化为tcp_recvmsg,和send的过程基本上完全类似,断点追踪如下:
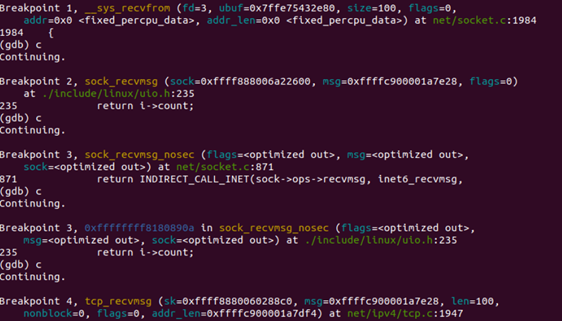
可以看出,这个执行的过程和send的过程有着惊人的相似,这也符合socketAPI对称的特点,在使用和编程的过程中,具有很强的一致性,也便于开发人员进行维护。所以,应用层的具体收发流程追踪结束,tcp_sendmsg和tcp_recvmsg即进行传输层。
传输层为应用进程之间提供端到端的逻辑通信, "逻辑通信"的意思是:运输层之间的通信好像是沿水平方向传送数据。但事实上这两个运输层之间并没有一条水平方向的物理连接。
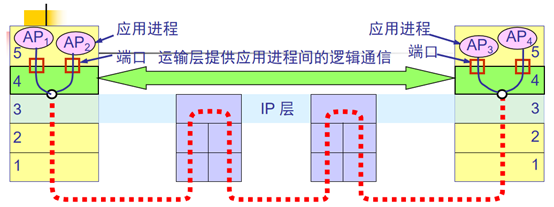
即在第四层,通过端口完成进程之间的逻辑通信。本次实验追踪的代码是基于tcp协议完成的传输层信息传递,所以向用户提供高效的、可靠的和成本有效的数据传输服务,主要包括了构造tcp段,回复确认包,确定滑动窗口等一些列动作。
从上面所说的应用层,我们可以得知最后到达传输层的tcp协议的函数为tcp_sendmsg,所以在代码中查看该函数:
1 int tcp_sendmsg(struct sock *sk, struct msghdr *msg, size_t size) 2 3 { 4 5 int ret; 6 7 lock_sock(sk); 8 9 ret = tcp_sendmsg_locked(sk, msg, size); 10 11 release_sock(sk); 12 13 return ret; 14 15 } 16 17 EXPORT_SYMBOL(tcp_sendmsg);
从这段代码可以看出,发送的过程涉及到上锁和释放锁的一个操作,查阅资料可知目的是让接收和发送队列能够有序进行相关的工作。然后主要的发送函数即为tcp_sendmsg_locked这个函数,继续追踪该函数,
1 int tcp_sendmsg_locked(struct sock *sk, struct msghdr *msg, size_t size) 2 3 { 4 5 struct tcp_sock *tp = tcp_sk(sk); 6 7 struct ubuf_info *uarg = NULL;40 41 if (!zc) 42 43 uarg->zerocopy = 0; 44 45 } 46 47 ........ 48 49 if (((1 << sk->sk_state) & ~(TCPF_ESTABLISHED | TCPF_CLOSE_WAIT)) && 50 51 !tcp_passive_fastopen(sk)) { 52 53 err = sk_stream_wait_connect(sk, &timeo); 54 55 if (err != 0) 56 57 goto do_error; 58 59 }........ 60 61 wait_for_sndbuf: 62 63 set_bit(SOCK_NOSPACE, &sk->sk_socket->flags); 64 65 wait_for_memory: 66 67 if (copied) 68 69 tcp_push(sk, flags & ~MSG_MORE, mss_now, 70 71 TCP_NAGLE_PUSH, size_goal);........... 72 73 } 74 75 EXPORT_SYMBOL_GPL(tcp_sendmsg_locked);
这个函数的代码相当多,涉及到的逻辑即为tcp协议中具体的几个处理过程。首先即为检查连接状态的TCPF_ESTABLISHED和TCPF_CLOSE_WAIT,如果不是这两个状态,即代表要等待连接或者进行出错处理;然后就是检查数据的是否分段,获取最大的MSS数据,将数据复制到skb队列进行发送。当然,这两部中间省略了很多检查的逻辑,也做了很多出错的处理,作为正确发送的过程中,这两个倒不是特别重要,所以先不详述。到发送这一步,可以看到tcp_push函数,这个即为将数据添加到sk队列追踪,检查是否立即发送,然后将数据复制到发送队列中,一切正常的话,即进行发送。在查看tcp_push函数,
static void tcp_push(struct sock *sk, int flags, int mss_now, int nonagle, int size_goal) { struct tcp_sock *tp = tcp_sk(sk); struct sk_buff *skb; skb = tcp_write_queue_tail(sk); if (flags & MSG_MORE) nonagle = TCP_NAGLE_CORK;...... __tcp_push_pending_frames(sk, mss_now, nonagle); }
此处已经通过代码写入到skb队列当中,最后调用了 __tcp_push_pending_frames这个函数,这个时候通过这个函数进入到tcp_output.c这个文件,即为具体的处理过程。
1 void __tcp_push_pending_frames(struct sock *sk, unsigned int cur_mss , int nonagle) 4 5 { 6 7 /* If we are closed, the bytes will have to remain here. 8 9 * In time closedown will finish, we empty the write queue and 10 11 * all will be happy. 12 13 */ 14 15 if (unlikely(sk->sk_state == TCP_CLOSE)) 16 17 return; 18 19 if (tcp_write_xmit(sk, cur_mss, nonagle, 0, 20 21 sk_gfp_mask(sk, GFP_ATOMIC))) 22 23 tcp_check_probe_timer(sk); 24 25 }
继续查看可以追踪到tcp_write_xmit这个函数,这个函数即为具体发送过程,检查连接状态和拥塞窗口的大小,然后将skb队列发送出去。再往下看可以追踪到tcp_transmit_skb函数和__tcp_transmit_skb函数等,
1 static int tcp_transmit_skb(struct sock *sk, struct sk_buff *skb, int clone_it, gfp_t gfp_mask) 4 5 { 6 7 return __tcp_transmit_skb(sk, skb, clone_it, gfp_mask, 8 9 tcp_sk(sk)->rcv_nxt); 10 11 }
在__tcp_transmit_skb这个函数中,我们看到了如下代码:
/* Leave earliest departure time in skb->tstamp (skb->skb_mstamp_ns) */ /* Cleanup our debris for IP stacks */ memset(skb->cb, 0, max(sizeof(struct inet_skb_parm), sizeof(struct inet6_skb_parm))); tcp_add_tx_delay(skb, tp); err = icsk->icsk_af_ops->queue_xmit(sk, skb, &inet->cork.fl); if (unlikely(err > 0)) { tcp_enter_cwr(sk); err = net_xmit_eval(err); } if (!err && oskb) { tcp_update_skb_after_send(sk, oskb, prior_wstamp); tcp_rate_skb_sent(sk, oskb); } return err;
追踪到err = icsk->icsk_af_ops->queue_xmit(sk, skb, &inet->cork.fl)这个语句的时候,突然眼前一亮,因为传输层追踪到最后肯定是要发往网络层的数据,一直到现在,才能看到和网络层有些关系的东西。因为对于icsk->icsk_af_ops这个函数指针,在tcp协议栈中,会被初始化为ip_queue_xmit,所以知道这个函数这里才进入了网络层。可以简述为tcp_transmit_skb函数负责将tcp数据发送出去,这里调用了icsk->icsk_af_ops->queue_xmit函数指针,实际上就是在TCP/IP协议栈初始化时设定好的IP层向上提供数据发送接口ip_queue_xmit函数,这里TCP协议栈通过调用这个icsk->icsk_af_ops->queue_xmit函数指针来触发IP协议栈代码发送数据。到这个函数为止,传输层发送过程追踪完毕。下面进行断点验证,如下图所示,从上往下即可看出是符合我们的追踪过程的。
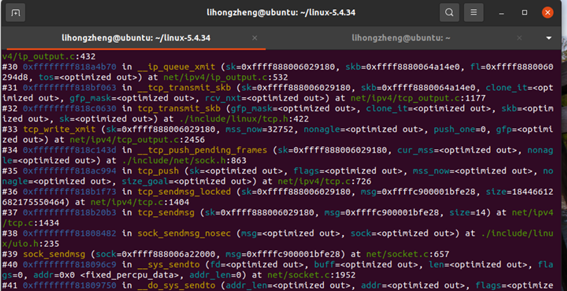
对于传输层的接收端而言,我们先整体分析一下。TCP/IP协议栈的初始化过程是在inet_init函数,其中有段代码中提到的tcp_protocol结构体变量,如下结构体所示:
1 static struct net_protocol tcp_protocol = { 2 3 .early_demux = tcp_v4_early_demux, 4 5 .early_demux_handler = tcp_v4_early_demux, 6 7 .handler = tcp_v4_rcv, 8 9 .err_handler = tcp_v4_err, 10 11 .no_policy = 1, 12 13 .netns_ok = 1, 14 15 .icmp_strict_tag_validation = 1, 16 17 };
其中的handler被赋值为tcp_v4_rcv,符合底层更一般化上层更具体化的协议设计的一般规律。此时不涉及到网络层的代码,但我们可以想象底层网络代码接到数据需要找到合适的处理数据的上层代码来负责处理,那么用handler函数指针来处理就很符合代码逻辑。
到这里我们就找到TCP协议中负责接收处理数据的入口tcp_v4_rcv,从从tcp_v4_rcv找到对SYN/ACK标志的处理(三次握手),连接请求建立后并将连接放入accept的等待队列。
找到入口函数之后,我们就开始追踪源代码,具体分析过程和发送端类似,此处简要叙述.
查找入口地址函数tcp_v4_rcv,可以看到具体过程是检测连接状态最后调用具体的接收处理函数tcp_v4_do_rcv,查看源码可知,利用建立连接之后利用tcp_rcv_established来进行数据的接收,继续追踪就到了tcp_input.c这个文件当中,和发送端一样,具有很高的对称性。
1 int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb) 2 3 { 4 5 struct sock *rsk; 6 7 if (sk->sk_state == TCP_ESTABLISHED) { /* Fast path */ 8 9 struct dst_entry *dst = sk->sk_rx_dst; 10 11 sock_rps_save_rxhash(sk, skb); 12 13 sk_mark_napi_id(sk, skb); 14 15 if (dst) { 16 17 if (inet_sk(sk)->rx_dst_ifindex != skb->skb_iif || 18 19 !dst->ops->check(dst, 0)) { 20 21 dst_release(dst); 22 23 sk->sk_rx_dst = NULL; 24 25 } 26 27 } 28 29 tcp_rcv_established(sk, skb);
再往下走:
1 /* Bulk data transfer: receiver */ 2 3 __skb_pull(skb, tcp_header_len); 4 5 eaten = tcp_queue_rcv(sk, skb, &fragstolen); 6 7 tcp_event_data_recv(sk, skb); 8 9 if (TCP_SKB_CB(skb)->ack_seq != tp->snd_una) { 10 11 /* Well, only one small jumplet in fast path... */ 12 13 tcp_ack(sk, skb, FLAG_DATA); 14 15 tcp_data_snd_check(sk); 16 17 if (!inet_csk_ack_scheduled(sk)) 18 19 goto no_ack; 20 21 } 22 23 __tcp_ack_snd_check(sk, 0);
在tcp_rcv_established这个函数中,涉及到的逻辑也比较复杂,涉及到一系列的标志位检查,状态处理的过程,当然这也是tcp协议必须保证的一个特征。到最后返回值里面,有一个tcp_queue_rcv函数,可以看出来这个即时最终向上返回的函数,查看这个函数,
1 static int __must_check tcp_queue_rcv(struct sock *sk, struct sk_buff *skb, 2 3 bool *fragstolen) 4 5 { 6 7 int eaten; 8 9 struct sk_buff *tail = skb_peek_tail(&sk->sk_receive_queue); 10 11 eaten = (tail && 12 13 tcp_try_coalesce(sk, tail, 14 15 skb, fragstolen)) ? 1 : 0; 16 17 tcp_rcv_nxt_update(tcp_sk(sk), TCP_SKB_CB(skb)->end_seq); 18 19 if (!eaten) { 20 21 __skb_queue_tail(&sk->sk_receive_queue, skb); 22 23 skb_set_owner_r(skb, sk); 24 25 } 26 27 return eaten; 28 29 }
到这个函数这里,稍微有点眉目了。
struct sk_buff *tail = skb_peek_tail(&sk->sk_receive_queue);这个语句表明将发送的消息添加到队列的最尾端,即相当于发送之后进行系统调用唤醒socket(一切正常的情况下),然后再利用我们刚刚在应用层提到的tcp_recvmsg函数去进行消息的处理。所以,接收端追踪完毕,断点追踪如下:
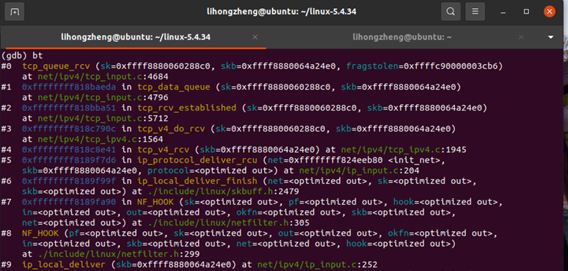
3.网络层
网络层的任务就是选择合适的网间路由和交换结点, 确保数据及时传送。这一层的 主要任务有路由处理、添加IP头部、IP校验和、IP分片和转发进链路层。相关的协议在下图中可以表示出来:

在IP协议里面,还有ICMP,ARP等重要协议。结合源码来分析其发送和接收的具体流程。
1)发送端
结合我们上面在传输层追踪到的最后的函数ip_queue_xmit,可以查看到其中的源码:
1 static inline int ip_queue_xmit(struct sock *sk, struct sk_buff *skb,struct flowi *fl) 4 5 { 6 7 return __ip_queue_xmit(sk, skb, fl, inet_sk(sk)->tos); 8 9 }
其实是调用了__ip_queue_xmit函数进行具体的消息处理。
1 int __ip_queue_xmit(struct sock *sk, struct sk_buff *skb, struct flowi *fl, __u8 tos) 4 5 {................ 6 7 int res;......... 8 9 rt = ip_route_output_ports(net, fl4, sk,24 25 goto no_route; 26 27 sk_setup_caps(sk, &rt->dst); 28 29 } 30 31 skb_dst_set_noref(skb, &rt->dst); 32 33 packet_routed: 34 35 if (inet_opt && inet_opt->opt.is_strictroute && rt->rt_uses_gateway) 36 37 goto no_route; 38 39 /* OK, we know where to send it, allocate and build IP header. */ 40 41 skb_push(skb, sizeof(struct iphdr) + (inet_opt ? inet_opt->opt.optlen : 0)); 42 43 .............. 44 45 iph->protocol = sk->sk_protocol; 46 63 no_route: 64 65 rcu_read_unlock(); 66 67 IP_INC_STATS(net, IPSTATS_MIB_OUTNOROUTES); 68 69 kfree_skb(skb); 70 71 return -EHOSTUNREACH; 72 73 } 74 75 EXPORT_SYMBOL(__ip_queue_xmit);
ip_queue_xmit(skb)会检查skb->dst路由信息。如果没有,比如套接字的第一个包,就使用ip_route_output()选择一个路由。紧接着根据代码可知,会进行分片和字段填充等工作,根据我们所学知识可知,如果大于最大长度mtu,则进行分片,否则直接发出去,调用的函数是ip_finish_output,进而调用__ip_finish_output。
1 static int __ip_finish_output(struct net *net, struct sock *sk, struct sk_buff *skb) 2 3 { 4 5 unsigned int mtu; 6 7 #if defined(CONFIG_NETFILTER) && defined(CONFIG_XFRM) 8 9 /* Policy lookup after SNAT yielded a new policy */ 10 11 if (skb_dst(skb)->xfrm) { 12 13 IPCB(skb)->flags |= IPSKB_REROUTED; 14 15 return dst_output(net, sk, skb); 16 17 } 18 19 #endif 20 21 mtu = ip_skb_dst_mtu(sk, skb); 22 23 if (skb_is_gso(skb)) 24 25 return ip_finish_output_gso(net, sk, skb, mtu); 26 27 if (skb->len > mtu || (IPCB(skb)->flags & IPSKB_FRAG_PMTU)) 28 29 return ip_fragment(net, sk, skb, mtu, ip_finish_output2); 30 31 return ip_finish_output2(net, sk, skb); 32 33 }
这个函数检查完标志位和路由之后,正常情况下就调用ip_finish_output2发送数据报,在转发的过程中,neigh_output,neigh_hh_outpu(缓存)被调用,选择具体的路由进行转发,最终调用dev_queue_xmit(skb)将数据包考本到链路层skb,交由下一层处理。这几个调用的过程见下面部分源码。
1 static int ip_finish_output2(struct net *net, struct sock *sk, struct sk_buff *skb) 3 { 5 struct dst_entry *dst = skb_dst(skb);12 13 struct neighbour *neigh; 14 15 bool is_v6gw = false; 16 17 .............. 18 19 if (!IS_ERR(neigh)) { 20 21 int res; 22 23 sock_confirm_neigh(skb, neigh); 24 25 /* if crossing protocols, can not use the cached header */ 26 27 res = neigh_output(neigh, skb, is_v6gw); 28 29 rcu_read_unlock_bh(); 30 31 return res; 32 33 } 34 35 static inline int neigh_output(struct neighbour *n, struct sk_buff *skb, bool skip_cache) 38 39 { 40 41 const struct hh_cache *hh = &n->hh; 42 43 if ((n->nud_state & NUD_CONNECTED) && hh->hh_len && !skip_cache) 44 45 return neigh_hh_output(hh, skb); 46 47 else 48 49 return n->output(n, skb); 50 51 } 52 53 static inline int neigh_hh_output(const struct hh_cache *hh, struct sk_buff *skb) 55 { 57 ................ 58 59 __skb_push(skb, hh_len); 60 61 return dev_queue_xmit(skb); 62 63 }
断点追踪调试的协议栈如下图所示,所以可以看出对应的代码中没有缓存,直接利用网络层路由来转发。
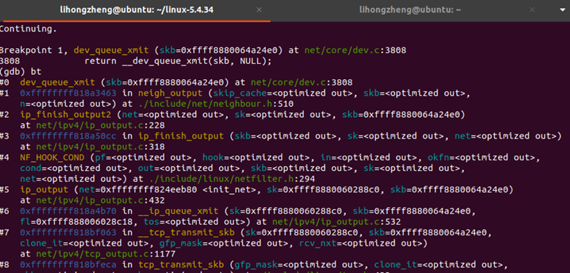
2)接收端
上面传输层的部分可以得知,网络层的的接收端函数的入口地址是ip_rcv,查看源码可以看到
1 int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt,struct net_device *orig_dev) 4 5 { struct net *net = dev_net(dev); 6 7 skb = ip_rcv_core(skb, net); 8 9 if (skb == NULL) 10 11 return NET_RX_DROP; 12 13 return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING, 14 15 net, NULL, skb, dev, NULL, 16 17 ip_rcv_finish); 18 19 }
最终调用的是ip_rcv_finish这个函数接口,ip_rcv_finish 函数会调用dst_input函数,
static int ip_rcv_finish(struct net *net, struct sock *sk, struct sk_buff *skb) { struct net_device *dev = skb->dev; int ret; /* if ingress device is enslaved to an L3 master device pass the * skb to its handler for processing */ skb = l3mdev_ip_rcv(skb); if (!skb) return NET_RX_SUCCESS; ret = ip_rcv_finish_core(net, sk, skb, dev); if (ret != NET_RX_DROP) ret = dst_input(skb); return ret; } static inline int dst_input(struct sk_buff *skb) { return skb_dst(skb)->input(skb); }
在dst_input函数中,最终在ip层即生成ip_input,根据路由选择调用ip_router_input 函数,进入路由处理环节。它首先会调用 ip_route_input 来更新路由,然后查找 route,决定该 package 将会被发到本机还是会被转发还是丢弃。
根据源码可以看出发向上层的数据时调用 ip_local_deliver 函数,可能会合并IP包,然后调用 ip_local_deliver 函数。该函数根据 package 的下一个处理层的 protocal number,调用下一层接口,包括 tcp_v4_rcv等,对于 TCP 来说,函数 tcp_v4_rcv 函数会被调用,从而处理流程进入 TCP 栈。由此可以和我们刚刚追踪的传输层的函数连接起来;当然,跟新路由的时候如果是转发而不是发送到本机则向下层处理。
1 int ip_local_deliver(struct sk_buff *skb) { 11 struct net *net = dev_net(skb->dev); 12 13 if (ip_is_fragment(ip_hdr(skb))) { 14 15 if (ip_defrag(net, skb, IP_DEFRAG_LOCAL_DELIVER)) 16 17 return 0; 18 19 } 20 21 return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN, 22 23 net, NULL, skb, skb->dev, NULL, 24 25 ip_local_deliver_finish); 26 27 } 28 29 static int ip_local_deliver_finish(struct net *net, struct sock *sk, struct sk_buff *skb) 30 31 { 32 33 __skb_pull(skb, skb_network_header_len(skb)); 34 35 rcu_read_lock(); 36 37 ip_protocol_deliver_rcu(net, skb, ip_hdr(skb)->protocol); 38 39 rcu_read_unlock(); 40 41 return 0; 42 43 }
上面的第二个函数中,最后调用的 ip_protocol_deliver_rcu即为具体的选择协议的函数,
1 void ip_protocol_deliver_rcu(struct net *net, struct sk_buff *skb, int protocol) 2 3 { 4 5 const struct net_protocol *ipprot; 6 7 int raw, ret; 8 9 resubmit: 10 11 raw = raw_local_deliver(skb, protocol); 12 13 ipprot = rcu_dereference(inet_protos[protocol]); 14 15 if (ipprot) { 16 17 if (!ipprot->no_policy) { 18 19 if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) { 20 21 kfree_skb(skb); 22 23 return; 24 25 } 26 27 nf_reset_ct(skb); 29 } 30 31 ret = INDIRECT_CALL_2(ipprot->handler, tcp_v4_rcv, udp_rcv,skb); 37 }
此处,根据tcp协议,调用了tcp_v4_rcv函数,向上进入传输层处理。即网络层的接收追踪完毕,断点调试如下所示:
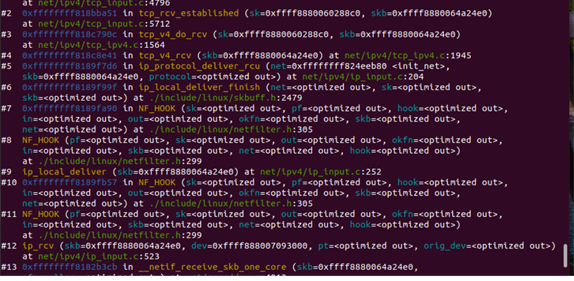
4.网络接口层
网络接口层对应着tcp/ip协议的最底层,也可以理解为是常说的数据链路层和物理层的结合,向上接收网络层来的包,向下联系具体的物理网络。在链路层的数据流为帧,在物理层转化为比特流。改层的数据流动较为简单和清晰,个人觉得这一层次的重点完全依赖于硬件的实现。
1)发送端
上层跟踪出来的入口函数dev_queue_xmit,即在这个函数入口这里进入链路层进行处理。
1 int dev_queue_xmit(struct sk_buff *skb) 2 3 { 4 5 return __dev_queue_xmit(skb, NULL); 6 7 }
可以看出和别的入口函数类似,调用__dev函数,__dev函数的实现较为复杂,
1 static int __dev_queue_xmit(struct sk_buff *skb, struct net_device *sb_dev) 2 3 { ......... 4 5 bool again = false; 6 7 if (dev->flags & IFF_UP) { 8 9 int cpu = smp_processor_id(); /* ok because BHs are off */ 29 skb = dev_hard_start_xmit(skb, dev, txq, &rc); 30 31 dev_xmit_recursion_dec(); 32 33 if (dev_xmit_complete(rc)) { 34 35 HARD_TX_UNLOCK(dev, txq); 36 37 goto out;
涉及到链路层的各个方面的检查,流量控制,封装成帧等,不过多去看他的代码实现,这里只关注一切正常的情况下,调用dev_hard_start_xmit函数向下发送数据。
1 struct sk_buff *dev_hard_start_xmit(struct sk_buff *first, struct net_device *dev, 2 3 ...... 4 5 while (skb) { 6 7 struct sk_buff *next = skb->next; 8 9 skb_mark_not_on_list(skb); 10 11 rc = xmit_one(skb, dev, txq, next != NULL); 12 13 .....
最终的数据通过xmit_one这个函数传递给物理层的设备,到这里虚拟的传递的驱动就要结束了,将和实际的设备驱动连接起来.
1 static int xmit_one(struct sk_buff *skb, struct net_device *dev,struct netdev_queue *txq, bool more) 5 { 6 7 unsigned int len; 8 9 int rc; 10 11 if (dev_nit_active(dev)) 12 13 dev_queue_xmit_nit(skb, dev); 14 15 len = skb->len; 16 17 trace_net_dev_start_xmit(skb, dev); 18 19 rc = netdev_start_xmit(skb, dev, txq, more); 20 21 trace_net_dev_xmit(skb, rc, dev, len); 23 return rc; 25 }
xmit_one函数在使用的过程中,利用netdev_start_xmit来启动物理层的接口,进而调用__netdev_start_xmit,物理层在收到发送请求之后,通过 DMA 将该主存中的数据拷贝至内部RAM(buffer)之中,同时在数据的拷贝中,还会加入相关协议等。对于以太网网络,物理层发送采用CSMA/CD协议,即在发送过程中侦听链路冲突。一旦网卡完成报文发送,将产生中断通知CPU,然后驱动层中的中断处理程序就可以删除保存的 skb 了。到这一步,这个数据就可以完整的输出到物理层设备上了,转化为比特流的形式。
1 static inline netdev_tx_t __netdev_start_xmit(const struct net_device_ops *ops, struct sk_buff *skb, struct net_device *dev, bool more) 7 { 9 __this_cpu_write(softnet_data.xmit.more, more); 10 11 return ops->ndo_start_xmit(skb, dev); 12 13 }
该层发送的过程断点追踪如下:
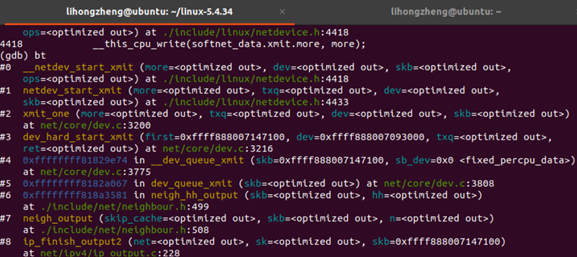
2)接收端
接收端的过程较为简单,因为从物理设备上到链路层,还是很底层的东西,所以会经过很多中断处理的过程,其中就包括我们前面所说的软中断(softirq)。
当一个包到达物理层网络时,接收到数据帧就会引发中断。接收端中断处理程序经过简单处理后,发出一个软中断(NET_RX_SOFTIRQ),通知内核接收到新的数据帧。在linux5.4.34内核中,利用一组特殊的API 来处理接收的数据帧,即 NAPI,通过NAPI机制该中断处理程序调用 Network device的 netif_rx_schedule 函数,进入软中断处理流程,再调用 net_rx_action 函数。
1 static __latent_entropy void net_rx_action(struct softirq_action *h) 2 3 { 4 5 struct softnet_data *sd = this_cpu_ptr(&softnet_data); 6 7 unsigned long time_limit = jiffies + 8 9 local_irq_disable(); 10 11 list_splice_init(&sd->poll_list, &list); 12 13 local_irq_enable(); 14 15 for (;;) { 16 17 struct napi_struct *n; 18 19 budget -= napi_poll(n, &repoll); 20 21 /* If softirq window is exhausted then punt. 22 23 * Allow this to run for 2 jiffies since which will allow 24 25 * an average latency of 1.5/HZ. 43 out: 44 45 __kfree_skb_flush(); 46 47 }
该函数关闭中断,获取每个网络设备中的所有 package。进入 netif _receive_skb 处理流程,具体的调用为__netif_receive_skb_one_core函数。netif_receive_skb 是链路层接收数据报的最后一个大步骤。它根据一系列的内部定义和协议栈信息,具体的是全局数组 ptype_all和ptype_base 里的网络层数据报类型将数据包递交给不同的网络协议来进行处理,以下代码中有具体的结构体的定义。本程序中即为ip_rcv函数(INET域中主要是ip_rcv和arp_rcv)。该函数主要就是调用第三层协议的接收函数处理该skb包,进入第三层网络层处理。
1 static int __netif_receive_skb_one_core(struct sk_buff *skb, bool pfmemalloc) 2 3 { 4 5 struct net_device *orig_dev = skb->dev; 6 7 struct packet_type *pt_prev = NULL; 8 9 int ret; 13 ret = __netif_receive_skb_core(skb, pfmemalloc, &pt_prev); 14 15 if (pt_prev) 17 ret = INDIRECT_CALL_INET(pt_prev->func, ipv6_rcv, ip_rcv, skb, 18 19 skb->dev, pt_prev, orig_dev); 20 21 return ret; 23 } 24 25 static int __netif_receive_skb_core(struct sk_buff *skb, bool pfmemalloc, 26 27 struct packet_type **ppt_prev) 28 29 { 30 31 struct packet_type *ptype, *pt_prev; 32 33 rx_handler_func_t *rx_handler; 34 35 struct net_device *orig_dev; 36 37 bool deliver_exact = false; 38 39 int ret = NET_RX_DROP; 40 41 __be16 type; 42 43 ..........
具体的中断处理过程不做详述,此处知道大概的时序过程即可。断点追踪如下所示,即可发现有多处软中断的过程以及napi的调用。所以,到这里接收端追踪结束,到ip_rcv函数这里交由网络层处理。
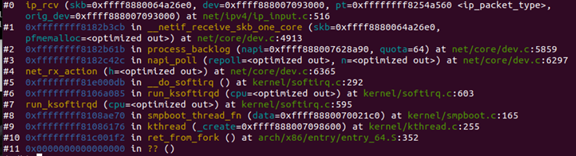
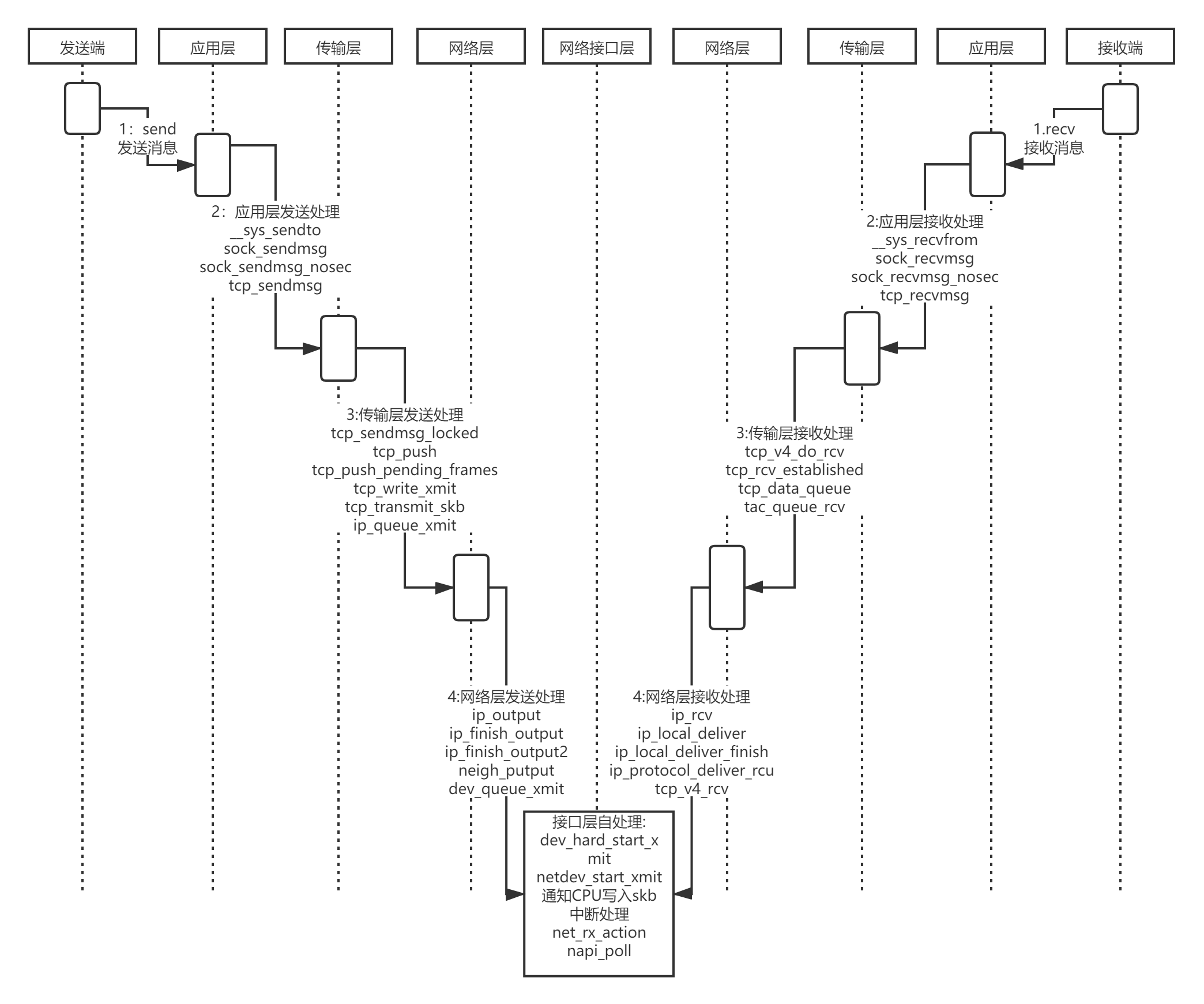
5.时序图
根据上述的发送和接收过程的各个函数调用和断点追踪,此时我们心已经有了一个大概的流程,消息在发送和接收的过程中,tcp/ip协议栈的变化以及各个层次的关系也已经稍微清晰了一点。下面画出时序图,该时序图目的是理解一切顺利比较完美的情况下发送和接收时的函数调用和栈的变化,所以没有考虑类似于分片以及路由查找等情况。正常情况下的完整的时序图应该远不止如此。
经过了几天的源码分析和查阅资料的过程,完成了这个调研报告。经过这次调研,对TCP/IP协议栈在Linux内核中运行的时序有了一定的了解,让我映象较为深刻的就是接收端和发送端的高对称性,在我自己的理解中,就像镜像的一种关系,有发就有收,也和计算机网络体系结构当中的对等层的服务的思想有点类似,这也体现了协议栈的设计者们的精巧之处和智慧所在。当然,对于这些函数和接口的简单分析只能说是浅尝辄止,没有理解其中的原理和设计理由所在,不管在以后的学习还是实习工作中,还得进一步深入理解!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号