代码中的软件工程---menu实验代码的调试与分析
最近上了孟宁老师的“代码中的软件工程 工程化编程实战”的一系列课程,引发了我深深的思考。在听了孟宁老师的一些讲解之后,让之前在我印象中的比较抽象的软件工程的一些理论和方法现在都能在实践中得到应用,虽然不能说自己完全理解了软件工程的一系列开发方法,但是也有了一定的认识。下面结合老师提供的menu实验代码来对这些方法及其应用来进行一些具体的分析。(本博客基于孟宁老师提供的资料和上课内容完成,源代码:https://github.com/mengning/menu,教学参考内容参见:https://gitee.com/mengning997/se/blob/master/README.md#%E4%BB%A3%E7%A0%81%E4%B8%AD%E7%9A%84%E8%BD%AF%E4%BB%B6%E5%B7%A5%E7%A8%8B)
一、编译和调试环境配置
首先来完成环境的配置和源代码的调试运行等工作。
第一步来配置VS Code的c语言编译环境。打开VS Code,此时VS Code对我们来说只是一个文本编辑器,没有任何的代码编译功能,如果我们想要运行C语言的代码,就要配置C/C++的编译环境。在VS Code中间打开扩展,如下图所示:
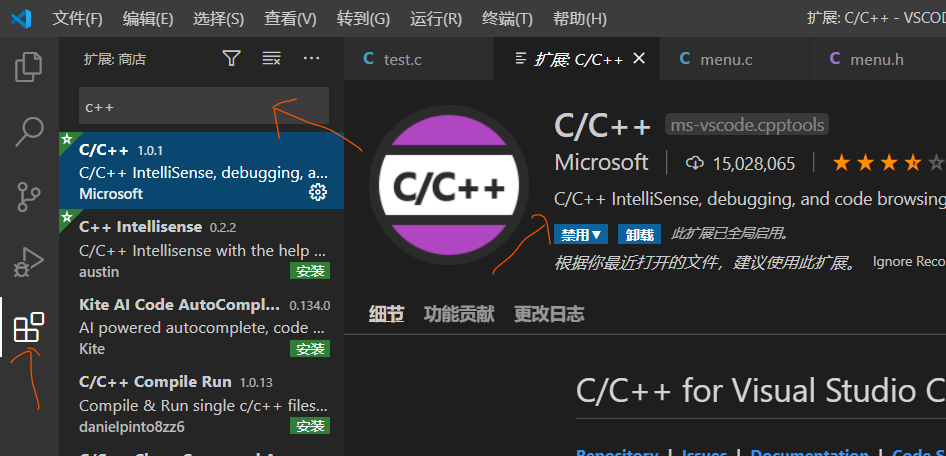
搜索c++,为防止出现不明bug,选择微软官方推荐的扩展,点击安装。此时扩展已经安装完成,但是现在还是无法运行c/c++的程序代码的,因为我们还没有配置编译器,所以,接下来配置编译器,为了在不同环境下保持一致,我们选择Mingw-w64/GCC。直接百度搜索MingGW即可下载,由于我之前已经下载过,所以此处不详说,然后下一步就直接安装即可。这里还有很重要的一步,那就是环境变量的配置,因为在VS Code需要找到该编译器。具体步骤如下:
1.找到下载好的MinGW的bin目录。
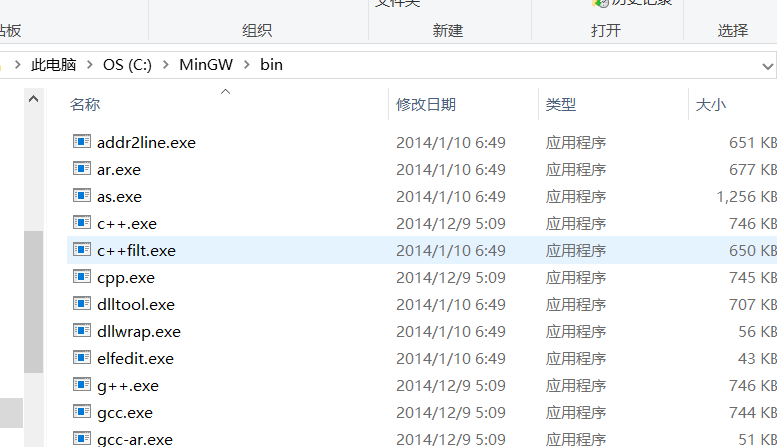
所以我的bin目录的路径是
1 C:\MinGW\bin
这个目录路径非常重要,先复制下来。
2.将bin目录的路径添加到系统环境变量,如下图所示:
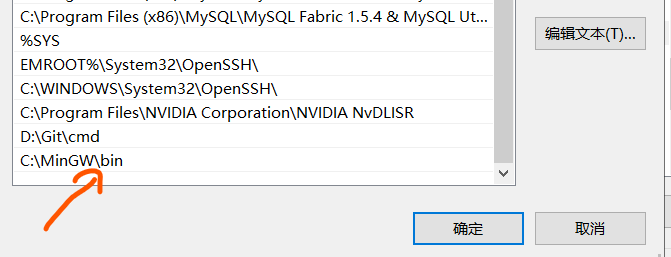
点击确定之后,环境变量就已经添加。
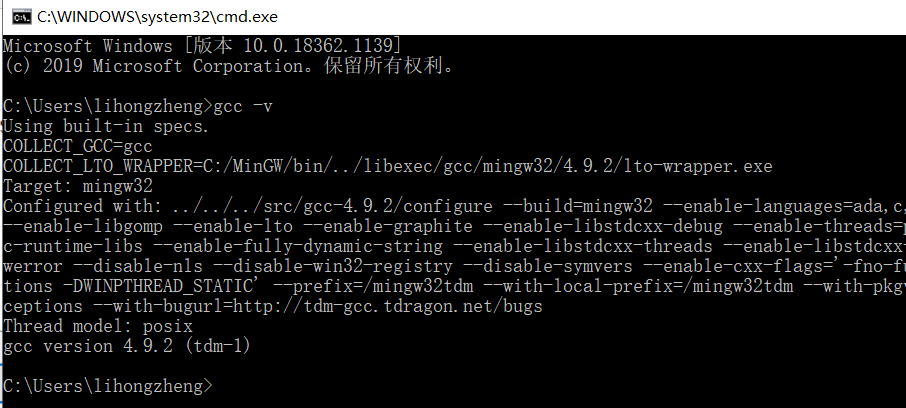
添加环境变量后,打开CMD,执行gcc -v看看是否安装成功。若出现版本号,则说明安装编译器成功。
此时我们便可以开始进行"hello world"测试。新建工作区,然后新建一个test的c语言文件。
3.配置工程所需的json文件。
进行到此步骤之后,在管理页面使用ctrl+shift+p,输入edit,此时会出现几个配置文件,分别是launch.json,tasks.json以及c_cpp_properties.json,这几个文件分别是对项目的编译路径以及运行方式的一些配置,此处我们重点配置一下c_cpp_properties这个配置文件,代码如下:
1 { 2 "configurations": [ 3 { 4 "name": "MinGW", 5 "intelliSenseMode": "gcc-x64", 6 "compilerPath": "C:/MinGW/bin/gcc.exe",//编译器的路径 7 "includePath": [ 8 "${workspaceFolder}" 9 ], 10 "defines": [], 11 "browse": { 12 "path": [ 13 "${workspaceFolder}" 14 ], 15 "limitSymbolsToIncludedHeaders": true, 16 "databaseFilename": "" 17 }, 18 "cStandard": "c11", 19 "cppStandard": "c++17" 20 } 21 ], 22 "version": 4 23 }
这个配置文件里面的compilerPath即为gcc的路径,此时千万不能写错,一定要和MinGW里的路径保持一致。其他两个配置文件基本上不用大改,所以,到此,环境配置基本上配置完成。当然,为了运行方便,可以安装一下code runner扩展,如下图所示,
即可很方便的运行文件。
当上面的几步全部弄完之后,做hello world测试时,报了一大堆gcc的乱码错误,然后我百思不得其解,大概花了一个多小时到网上去查找博客和官方文档,结果一无所获,后来在一篇博客中偶然看到了修改系统环境变量之后重启电脑的字眼,瞬间让我头脑一震,马上重启电脑,然后继续测试,果然就好了。浪费了一个多小时也让我汲取到了一个教训,修改了环境变量之后,如果对系统的程序有影响,那么就要重启电脑才能生效,否则无用。大家如果出现了和我一样的问题,不妨重启电脑试试。
二、运行源代码
经历了第一部分中的环境配置之后,下面我们来运行源代码,从提供的github网址上下载下来源代码之后,添加到工作区中,此时代码目录如下:
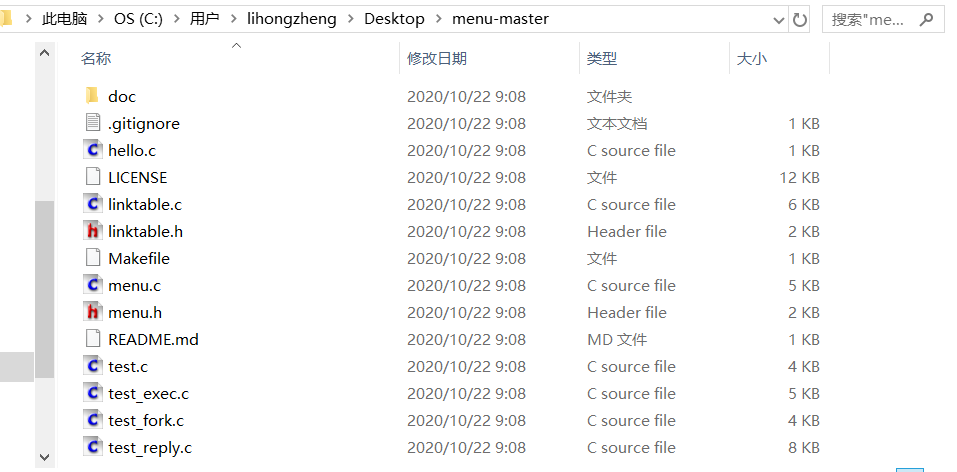
此时即可发现拥有两个头文件menu.h和linktable.h,然后一个测试的hello.c文件,以及其他五个功能c文件。查看这几个文件的代码之后,大概了解了这几个文件之间的关系,即linktable.c包含了linktable.h,menu.c包含了menu.h和linktable.h,然后其他的四个以test开头的c文件包含了menu.h。所以大致了解了代码的整体结构和包含关系,这里我们以较简单一点的test.c文件来进行运行。我们在VSCode终端中利用gcc命令来运行这一系列文件,主要命令如下图所示:
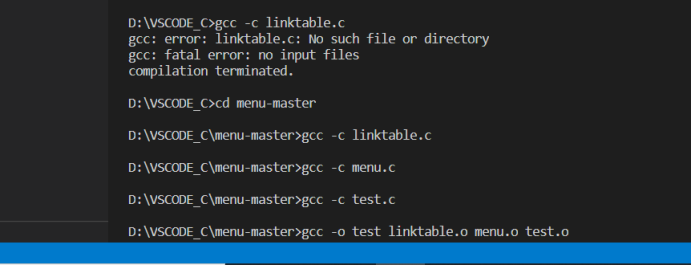
利用gcc -c命令来对c文件进行编译生成目标.o文件,然后利用gcc -o来将这些.o 文件生成可执行的exe文件。此时的目录如下图所示:

可见已经生成了可执行的test.exe文件,我们打开这个文件,然后根据代码中提示的help命令进行测试,得到如下结果:
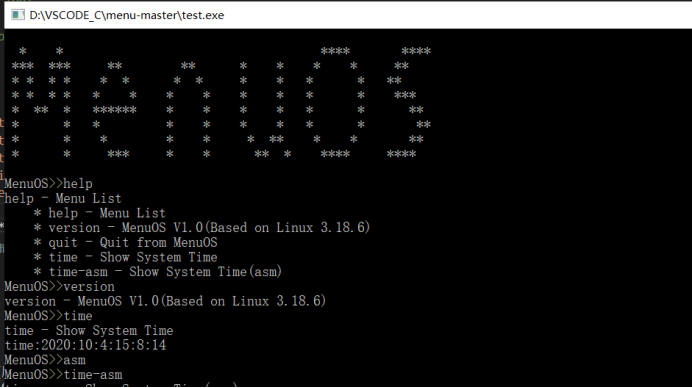
当然,如果你喜欢直接在终端中运行exe文件,也可直接在终端运行:

所以,通过help测试,代码显示了一系列的提示命令,然后执行time,version等命令,都显示了正确的结果,所以,代码运行成功。
三、源代码分析
经过上面两步的努力,我们现在已经能正确运行程序,接下来来进行源码的分析,下面将从模块化设计、可重用接口、线程安全和代码书写风格等四个方面来进行源代码的分析。
1、模块化设计。
模块化(Modularity)是在软件系统设计时保持系统内各部分相对独立,以便每一个部分可以被独立地进行设计和开发。这个做法背后的基本原理是关注点的分离 (SoC, Separation of Concerns),是由软件工程领域的奠基性人物Edsger Wybe Dijkstra(1930~2002)在1974年提出。关注点的分离在软件工程领域是最重要的原则,我们习惯上称为模块化,翻译成我们中文的表述其实就是“分而治之”的方法。 关注点的分离的思想背后的根源是由于人脑处理复杂问题时容易出错,把复杂问题分解成一个个简单问题,从而减少出错的情形。
结合本实验,我们就可以看出来实验的各个模块中就很好的利用到了模块化设计的思想。对于代码中的五个基本的文件,我做了一个表格,来表示其含义,
|
文件名 |
文件内容 |
包含头文件 |
|
linktable.h |
定义linktable相关属性和操作(菜单数据) |
|
|
menu.h |
定义menu相关操作(菜单操作) |
|
|
linktable.c |
实现linktable相关操作(菜单数据) |
linktable.h |
|
menu.c |
实现menu相关操作(菜单操作) |
menu.h,linktable.h |
|
test.c |
menu具体实现和页面展示(测试) |
menu.h |
在以上表格中,我们可以看出每个文件都有自己的独立完成的功能,当然,也包含有文件之间的调用关系,所以,这样就能保证系统的高内聚和低耦合性,即系统中的各模块能够各司其职,当出现了错误时,也能够很好的定位到该错误。由于分的层次很明显,也能很快的知道调用的关系。我们以linktable.h中定义的
1 tLinkTableNode * GetNextLinkTableNode(tLinkTable *pLinkTable,tLinkTableNode * pNode) 2 { 3 if(pLinkTable == NULL || pNode == NULL) 4 { 5 return NULL; 6 } 7 tLinkTableNode * pTempNode = pLinkTable->pHead; 8 while(pTempNode != NULL) 9 { 10 if(pTempNode == pNode) 11 { 12 return pTempNode->pNext; 13 } 14 pTempNode = pTempNode->pNext; 15 } 16 return NULL; 17 }
在menu.c中的调用为:
1 int ShowAllCmd(tLinkTable * head) 2 { 3 tDataNode * pNode = (tDataNode*)GetLinkTableHead(head); 4 while(pNode != NULL) 5 { 6 printf(" * %s - %s\n", pNode->cmd, pNode->desc); 7 pNode = (tDataNode*)GetNextLinkTableNode(head,(tLinkTableNode *)pNode); 8 } 9 return 0; 10 }
可见,其功能即为查找所有的命令,而这个功能的实现是在menu.c文件中具体实现的,但是调用的是linktable.h中的接口,即相当于我们使用的本地化外部接口,这样提高了代码的适应能力,即提高了代码的稳健性,但是有保证了各个模块代码中做的事情都是单一的,不会有很高的重合度。所以这也是模块化设计的很大的优点。
在此之前,如果我自己设计一个系统,可能不会分出这么多子模块和接口,直接揉在一个大的.c文件里面,虽然功能实现没什么差别,但是如果代码量上去了,然后同时又出现了很多bug,这个时候才能切实体会到模块化的优点。
2.可重用接口
上一部分说的模块化设计中,很大程度上就已经利用了接口来实现一些模块之间的调用关系,上述模块化设计中已经分离出来了menu的数据结构和其操作,但是分离出来的数据结构和它的操作还有很多菜单业务上的痕迹,这个时候我们就要让模块的内聚度提高,这样才能保证一个模块所作的事情就是这个模块要做的,不涉及其他模块的干预,这个时候我们就需要定义简洁、清晰、明确的接口。
关于接口的概念,我们简要的复习一下,接口就是互相联系的双方共同遵守的一种协议规范,在我们软件系统内部一般的接口方式是通过定义一组API函数来约定软件模块之间的沟通方式。换句话说,接口具体定义了软件模块对系统的其他部分提供了怎样的服务,以及系统的其他部分如何访问所提供的服务。接口规格是软件系统的开发者正确使用一个软件模块需要知道的所有信息,那么这个软件模块的接口规格定义就必须清晰明确地说明正确使用本软件模块的信息。一般来说,接口规格包含五个基本要素:接口的目的; 接口使用前所需要满足的条件,一般称为前置条件或假定条件; 使用接口的双方遵守的协议规范; 接口使用之后的效果,一般称为后置条件; 接口所隐含的质量属性。所以,针对这些条件来进行接口的设计,才能满足简洁清晰等特点。
我们来看一下linktable.h文件中定义的一系列接口:
1 tLinkTable * CreateLinkTable(); 2 /* 3 * Delete a LinkTable 4 */ 5 int DeleteLinkTable(tLinkTable *pLinkTable); 6 /* 7 * Add a LinkTableNode to LinkTable 8 */ 9 int AddLinkTableNode(tLinkTable *pLinkTable,tLinkTableNode * pNode); 10 /* 11 * Delete a LinkTableNode from LinkTable 12 */ 13 int DelLinkTableNode(tLinkTable *pLinkTable,tLinkTableNode * pNode); 14 /* 15 * Search a LinkTableNode from LinkTable 16 * int Conditon(tLinkTableNode * pNode,void * args); 17 */ 18 tLinkTableNode * SearchLinkTableNode(tLinkTable *pLinkTable, int Conditon(tLinkTableNode * pNode, void * args), void * args); 19 /* 20 * get LinkTableHead 21 */ 22 tLinkTableNode * GetLinkTableHead(tLinkTable *pLinkTable); 23 /* 24 * get next LinkTableNode 25 */ 26 tLinkTableNode * GetNextLinkTableNode(tLinkTable *pLinkTable,tLinkTableNode * pNode);
然后结合之后的实现和调用,可以看出基本上都满足了接口的目的和达到的效果这些要求,然后各个接口对应的操作的实现也是都在自己的函数内部来进行实现,不涉及到其他模块的耦合以及内部调用等,这也就保证了在调用该接口时,不需要太关注其他的模块的限定条件,也是我们使用起来较为方便。以上述的SearchLinkTableNode函数为例,实现和调用和上面例举的GetNextLinkTableNode函数很相似,代码如下:
1 /////实现------linktable.c 2 tLinkTableNode * SearchLinkTableNode(tLinkTable *pLinkTable, int Conditon(tLinkTableNode * pNode, void * args), void * args) 3 { 4 if(pLinkTable == NULL || Conditon == NULL) 5 { 6 return NULL; 7 } 8 tLinkTableNode * pNode = pLinkTable->pHead; 9 while(pNode != NULL) 10 { 11 if(Conditon(pNode,args) == SUCCESS) 12 { 13 return pNode; 14 } 15 pNode = pNode->pNext; 16 } 17 return NULL; 18 } 19 20 21 //////调用-------menu.c 22 tDataNode *p = (tDataNode*)SearchLinkTableNode(head,SearchConditon,(void*)argv[0]); 23 if( p == NULL) 24 { 25 continue; 26 } 27 printf("%s - %s\n", p->cmd, p->desc); 28 if(p->handler != NULL) 29 { 30 p->handler(argc, argv); 31 } 32 33 int SearchConditon(tLinkTableNode * pLinkTableNode,void * arg) 34 { 35 char * cmd = (char*)arg; 36 tDataNode * pNode = (tDataNode *)pLinkTableNode; 37 if(strcmp(pNode->cmd, cmd) == 0) 38 { 39 return SUCCESS; 40 } 41 return FAILURE; 42 }
可见,在该接口的实现和调用过程中,menu.c这个文件只包含了linktable.h这个头文件,而实现是在linktable.c这个文件中完成的,这样就保证了接口的实现的可扩展性,同时在menu.c中,定义的 SearchConditon函数也是给该查询的实现做了一定的扩展,即查询的条件可以通过这个来确定。综合以上两个特点来看,在linktable.h中定义的接口,都具有很好的扩展性,即实现不是已经确定的,可以通过具体的实现来完成。这也很好的满足了可复用接口的原则,在设计时,可以使得模块之间的耦合性更低,调用更方便。
3.可重入函数与线程安全
谈论这个话题之前,我们先来熟悉一下可重入和线程的概念。线程的概念我们很熟悉,线程是操作系统能够进行运算调度的最小单位。它包含在进程之中,是进程中的实际运作单位;而可重入的概念对我而言就很陌生了,在上完高软课之后,大概对此有了一定的了解。可重入函数可以由多于一个任务并发使用,而不必担心数据错误。相反,不可重入函数不能由超过一个任务所共享,除非能确保函数的互斥(或者使用信号量,或者在代码的关键部分禁用中断)。可重入函数的基本要求如下:

由以上的几个要求,我们大概可以知道,可重入函数要么使用局部变量,要么使用全局变量时对其进行保护,即被中断时,不会丢失数据,可继续正常运行。这里,可重入函数对全局变量的保护让我们很容易就联想到我们之前学习过的互斥锁和排他锁等知识,就是在线程运行时,对全局变量或者共享变量的操作不当,导致出现了写后读这样的错误,读出了很多脏数据或者存的数据不正确这样的情况,这个时候可重入便于线程安全联系起来了。
可重入与函数与线程安全的关系大概如下:不可重入的函数一定不是线程安全的;可重入的函数不一定是线程安全的,可能是线程安全的也可能不是线程安全的;可重入的函数在多个线程中并发使用时是线程安全的,但不同的可重入函数(共享全局变量及静态变量)在多个线程中并发使用时会有线程安全问题。不可重入函数不是线程安全很好理解,但是可重入的函数导致不安全的情况简而言之还是共享全局变量和静态变量导致的,再多个函数操作这一些临界资源时,就会出现一些难以预料的错误,针对这一问题,最常见的解决办法就是加锁,即在操作之前给临界资源上锁,保证其互斥。这个在代码之中也有很好的体现,下面看具体代码:
1 struct LinkTable 2 { 3 tLinkTableNode *pHead; 4 tLinkTableNode *pTail; 5 int SumOfNode; 6 pthread_mutex_t mutex; 7 8 };
在定义的这个linktable结构体中,定义了一个pthread_mutex_t变量,这个就是我们熟知的信号量的实现形式,以DeleteLinkTable函数为例来分析:
1 int DeleteLinkTable(tLinkTable *pLinkTable) 2 { 3 if(pLinkTable == NULL) 4 { 5 return FAILURE; 6 } 7 while(pLinkTable->pHead != NULL) 8 { 9 tLinkTableNode * p = pLinkTable->pHead; 10 pthread_mutex_lock(&(pLinkTable->mutex)); 11 pLinkTable->pHead = pLinkTable->pHead->pNext; 12 pLinkTable->SumOfNode -= 1 ; 13 pthread_mutex_unlock(&(pLinkTable->mutex)); 14 free(p); 15 } 16 pLinkTable->pHead = NULL; 17 pLinkTable->pTail = NULL; 18 pLinkTable->SumOfNode = 0; 19 pthread_mutex_destroy(&(pLinkTable->mutex)); 20 free(pLinkTable); 21 return SUCCESS; 22 }
重点在于中间的几行代码
1 pthread_mutex_lock(&(pLinkTable->mutex)); 2 pLinkTable->pHead = pLinkTable->pHead->pNext; 3 pLinkTable->SumOfNode -= 1 ; 4 pthread_mutex_unlock(&(pLinkTable->mutex));
此时进行删除节点的操作,但是由于定义的pLinkTable并不是互斥资源,所以此时删除节点之前应该利用pthread_mutex_lock对其进行上锁,然后删除节点之后在利pthread_mutex_unlock对其进行解锁,这样在操作的过程中,该线程操作的链表即为独占资源了,即不会引起数据的丢失。这个时候即是线程安全的,而此时如果不上锁造成的互斥即为写互斥,加锁之后也让其变成了可重入函数。AddLinkTableNode函数和这个删除节点类似,也是加锁消除了写互斥,而其他的SearchLinkTableNode等不进行写操作的函数即为可重入函数,不会造成数据改变和线程安全的问题。
综合以上的分析,我们明白了可重入函数和线程安全之间的关系,然后也知道了加锁的重要性,对于多个线程同时操作时,为避免写互斥等冲突,加锁还是很有必要的。
4.代码书写风格
作为程序员,咱们写简洁优美的代码是毕生的追求,一个良好的代码书写习惯会很大的影响我们以后的工作和生活。良好的代码书写习惯,从注释到每一个换行和括号,都应做到优美。老师提供的代码中的注释如下所示:
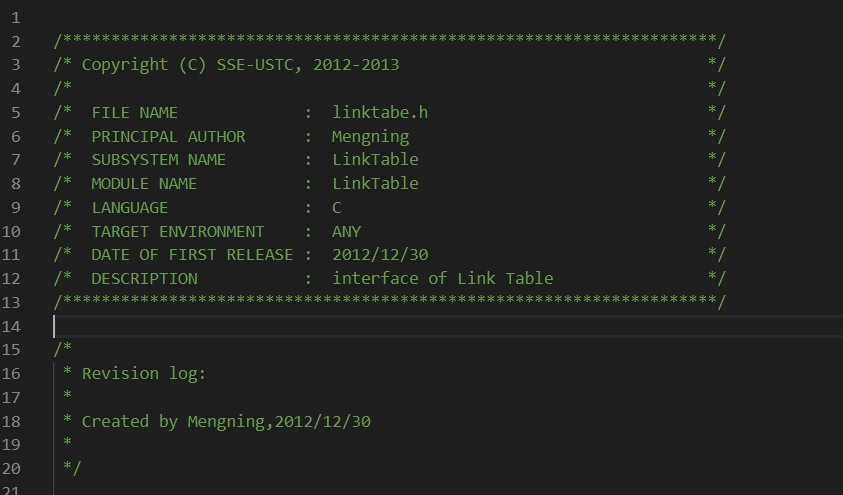
这个注释风格老师解释道是教学用的注释风格,在实际应用中基本上没人使用,因为说实话是有点过于复杂了。可是这样的目的可能也是为了我们以后实际书写注释时能养成良好的习惯,这样的注释看多了,以后写规范的注释就能够得心应手了。其实这也是给我自己的一个提醒,因为我在写注释时习惯很不好,全部都是斜杠,这样看起来就很乱,所以,以后还是得慢慢养成好的习惯呀。另外一点就是关于括号的使用:
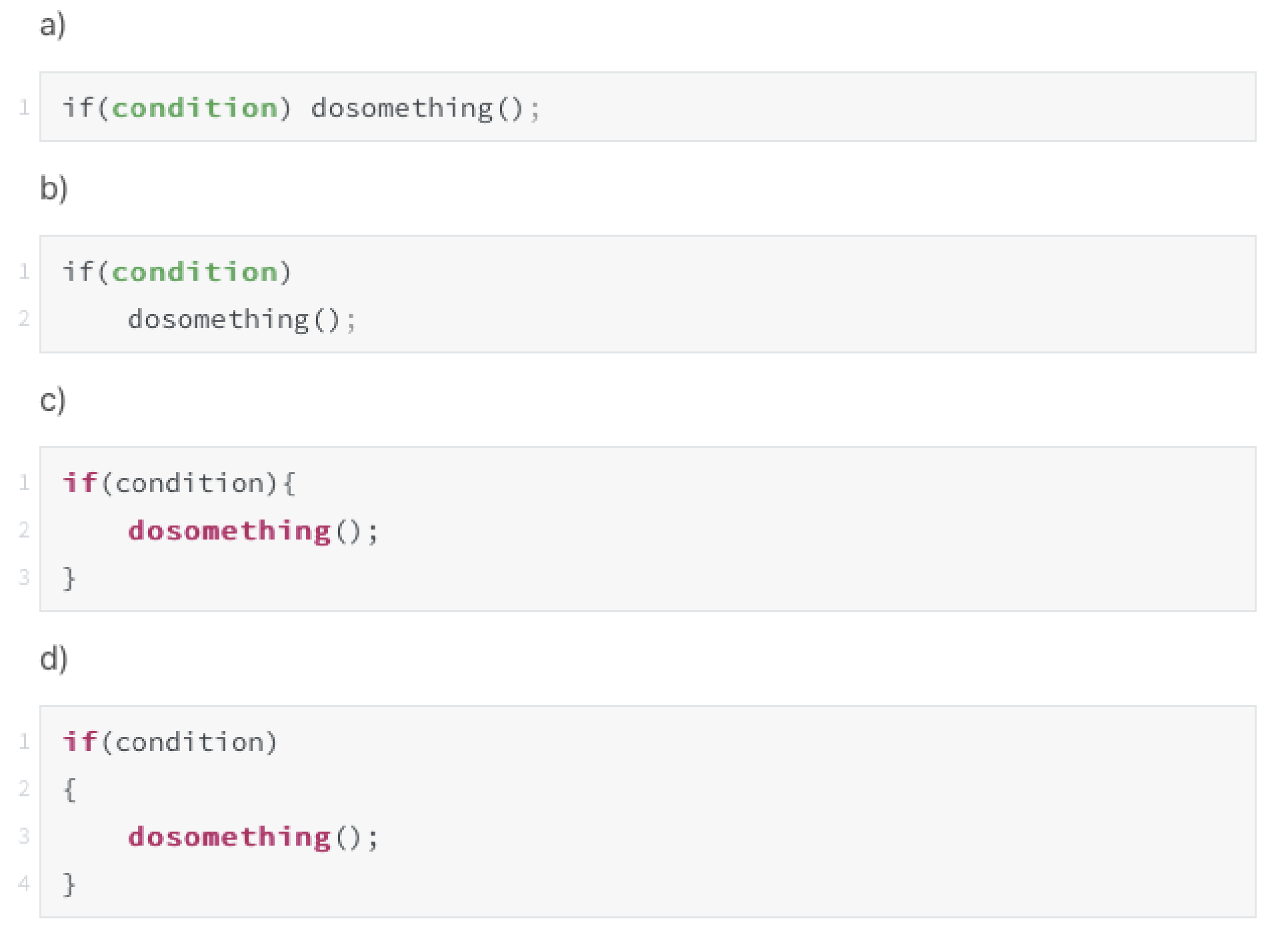
这是例举的四种括号使用方法,由于平时编写java代码较多,然后量又不是很大,所以习惯性的使用c这种风格的大括号,但是对于量大然后比较复杂的代码块,自习看看还是d这种风格最好,这样能使代码块更清晰、更易于阅读,当然也更易于调试。
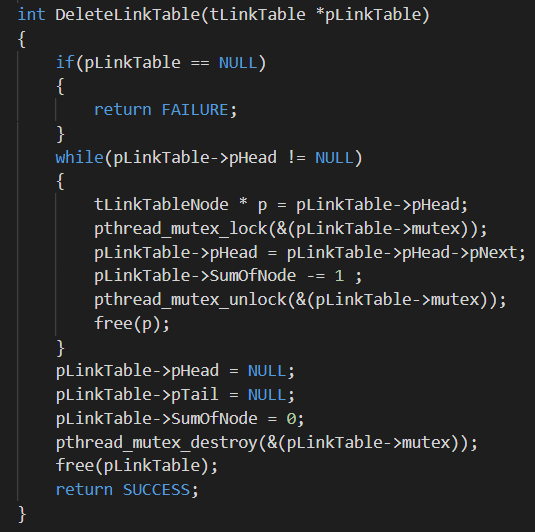
这种括号较多然后较为复杂的代码,如果转化为c这种形式的,确实看的有点眼花,所以,针对此还是要做出一定的改变。部分的代码规范课总结如下:
- 缩进:4个空格;
- 行宽:< 100个字符;
- 代码行内要适当多留空格,如“=”、“+=” “>=”、“<=”、“+”、“*”、“%”、“&&”、“||”、“<<”,“^”等二元操作符的前后应当加空格。对于表达式比较长的for语句和if语句,为了紧凑起见可以适当地去掉一些空格,如for (i=0; i<10; i++)和if ((a<=b) && (c<=d));
- 在一个函数体内,逻揖上密切相关的语句之间不加空行,逻辑上不相关的代码块之间要适当留有空行以示区隔;
- 在复杂的表达式中要用括号来清楚的表示逻辑优先级;
- 花括号:所有 ‘{’ 和 ‘}’ 应独占一行且成对对齐;
- 不要把多条语句和多个变量的定义放在同一行;
- 命名:合适的命名会大大增加代码的可读性;
- 类名、函数名、变量名等的命名一定要与程序里的含义保持一致,以便于阅读理解;
- 类型的成员变量通常用m_或者_来做前缀以示区别;
- 一般变量名、对象名等使用LowerCamel风格,即第一个单词首字母小写,之后的单词都首字母大写,第一个单词一般都表示变量类型,比如int型变量iCounter;
- 类型、类、函数名等一般都用Pascal风格,即所有单词首字母大写;
- 类型、类、变量一般用名词或者组合名词,如Member
- 函数名一般使用动词或者动宾短语,如get/set,RenderPage;
总结的规范比较多,虽然有时候可能会忽略很多,但是对于这些重要规则,写代码时还是要注意一下。
四、总结
之前接触过的项目都是体量比较小的项目,所以很多软件工程的方法都没有严格意义上的投入到项目的使用中去,导致很多时候出现了代码不规范、接口混乱以及代码耦合度过高,最终调试困难等一些问题,经过这次的项目的运行调试和源代码的分析,我对软件工程方法的认识有了根本的改变,并不是说项目小代码简单就用不到软件工程理论,恰恰相反,一切真理皆存在于一些小的方面上,只有将平时的一些小的项目慢慢的利用软件工程方法来进行规范和设计,才能真正领会到其中各个方法的意义。而且另一个方面也要加强实践,很多时候只了解理论,是没办法解决实际问题的。
最后,再次感谢孟宁老师的指导,让我对软件工程方法理论知识有了更深刻的认识,在以后的编码生涯中,还是值得不断的学习!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号