
🔧 cgroup-cpu/内存多用户资源管理效果演示
适用场景:多用户共享的Linux服务器(如开发测试机、数据分析集群),需隔离用户资源抢占,保障系统稳定性。
一、环境配置与工具安装
1. 安装cgroup管理工具
yum install -y libcgroup libcgroup-tools # 安装核心组件
systemctl enable --now cgconfig cgred # 启用并启动服务
作用:
-
libcgroup:提供cgroup内核支持 -
cgconfig:管理cgroup规则模板 -
cgred:实时将进程绑定到cgroup组
二、配置用户组资源规则
1. 关联用户组与cgroup策略(/etc/cgrules.conf)
cat > /etc/cgrules.conf <<EOF
@analog cpu,memory processlimit/%u # 用户组analog绑定模板
@digital cpu,memory processlimit/%u
@layout cpu,memory processlimit/%u
@cad cpu,memory processlimit/%u
EOF
关键配置解析:
- felix_li用户属于cad组别,因此在cgrules.conf配置文件当中关联了cgroup组
[root@oss1 ~]# id felix_li
uid=1167(felix_li) gid=1006(cad) groups=1006(cad)
-
%u:动态匹配用户名,自动生成独立cgroup目录(如processlimit/felix_li) -
cpu,memory:限制CPU和内存资源
三、定义资源模板(/etc/cgconfig.conf)
cat > /etc/cgconfig.conf <<EOF
template processlimit/%u {
cpu {
cpu.cfs_quota_us = 400000; # 允许400ms/周期的CPU时间(等效4核)
cpu.cfs_period_us = 100000; # 周期=100ms
}
memory {
memory.limit_in_bytes = 107374182400; # 内存上限100GB
memory.swappiness = 0; # 禁用Swap交换
}
}
EOF
参数说明:
-
CPU限制:
quota / period = 400000/100000 = 4核 -
内存限制:
memory.limit_in_bytes:物理内存硬上限memory.swappiness=0:禁止使用Swap,避免性能抖动
四、重启服务并验证配置
systemctl restart cgconfig cgred # 重启服务加载配置
ls /sys/fs/cgroup/cpu/processlimit/ # 检查模板目录生成
ls /sys/fs/cgroup/memory/processlimit/
预期输出:
自动创建目录如felix_li,内含cpu.cfs_quota_us、memory.limit_in_bytes等控制文件。
五、测试资源限制效果
场景:用户felix_li尝试分配104GB内存(超过100GB限制)
su - felix_li
stress-ng --vm 4 --vm-bytes 26G --vm-keep --timeout 300 # 启动4进程,各占26GB
--vm-bytes 26G 申请的是虚拟内存(VIRT)
--vm 4 4个 stress-ng 进程
--vm-keep 持续占用内存不释放

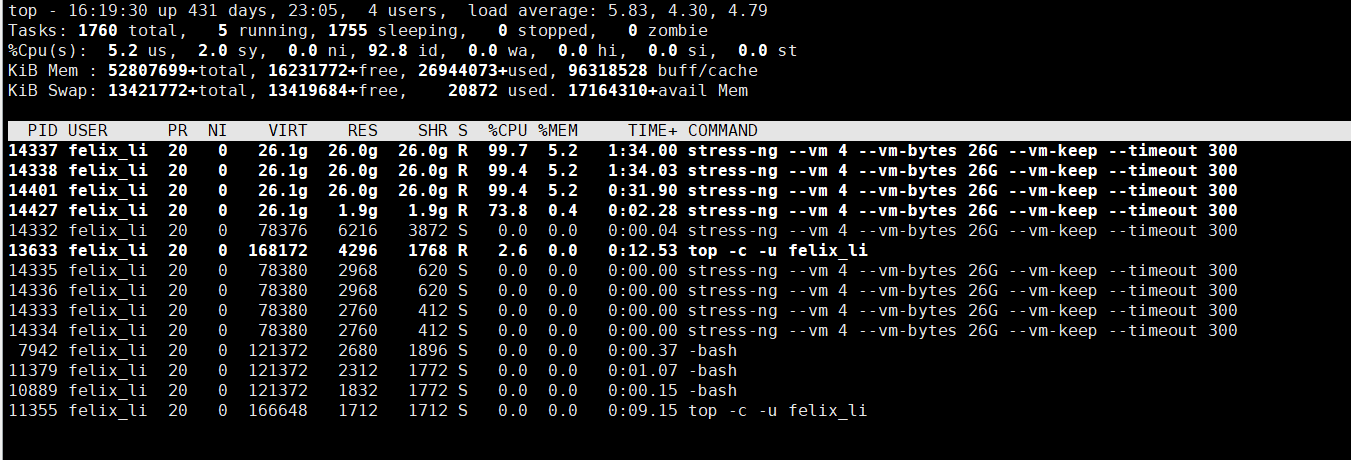
top动态显示负载:top -c -u felix_li
可以看到RES常驻内存已经都逼近26GB,但是由于cgroup内存最高限制到100G,最终被内核oom killer掉进程,4个进程cpu也是差不多在4个核左右,因此达到cgroup对felix_li单用户的cpu、内存限制的效果
使用 dmesg -Tw | grep -i "killed process" 实时显示含时间戳的OOM日志,截图如下

监控与结果:
-
内存占用:
watch -n 1 "grep -i 'oom\|kill' /var/log/messages" # 监控OOM事件现象:
- 进程启动后,
free -h显示总内存迅速逼近100GB - 触发OOM Killer:超过100GB时,内核强制终止部分进程(
stress-ng进程被杀死) - 系统日志输出:
Out of memory: Killed process [PID] (stress-ng)
- 进程启动后,
-
CPU限制验证:
stress-ng --cpu 8 --timeout 60 # 启动8个CPU负载进程现象:
top显示总CPU使用率稳定在400%(即4核满负载,未突破配额)
六、关键问题解析
1. 为何内存超限后进程被Kill而非阻塞?
-
cgroup内存限制是硬限制,超限时内核直接触发OOM Killer终止进程(即使
memory.oom_control=0也无法完全避免)。 -
规避方案:设置
memory.oom_control=1+memory.swappiness=0,但仅能延缓OOM,无法彻底避免。
2. 多进程资源如何统计?
-
cgroup自动追踪进程组内所有子进程的资源总和。
-
示例:父进程加入cgroup后,其fork的子进程自动继承相同限制 。
3. 动态调整限制
# 临时修改felix_li的CPU配额(调整至8核)
echo 800000 > /sys/fs/cgroup/cpu/processlimit/felix_li/cpu.cfs_quota_us
七、总结与最佳实践
核心价值:
✅ 用户级资源隔离:避免单用户抢占所有CPU/内存
✅ 限制实时生效:无需重启进程,规则动态应用
✅ 审计能力:通过cpuacct.usage、memory.usage_in_bytes统计用量
生产建议:
-
内存超配:总限制应小于物理内存(如预留20%给系统进程)
-
Swap谨慎启用:避免磁盘I/O拖慢性能
-
结合Namespace:与容器技术(如Docker)协同实现全隔离

 浙公网安备 33010602011771号
浙公网安备 33010602011771号