
MySQL 高可用领域中,MHA(Master High Availability) 和 MGR(MySQL Group Replication) 是两种代表性的解决方案,但它们在实现原理、数据一致性、故障切换逻辑和应用场景上存在根本性差异。以下是深度对比:
一、核心原理对比
| 特性 | MHA(MasterHighAvailability) | MGR(MySQLGroupReplication) |
|---|---|---|
| 架构本质 | 外部管理工具(Perl脚本) | 内置引擎级插件(InnoDB整合) |
| 复制模式 | 基于传统异步/半同步复制(主从架构) | 基于组通信协议(Paxos) 的强同步复制(多主/单主架构) |
| 故障检测 | Manager节点主动轮询健康状态(易漏判) | 节点间心跳检测 + 分布式共识(自动驱逐故障节点) |
| 故障切换主体 | MHA Manager 脚本触发(需 SSH 免密登陆) | 组内节点自协商 + 内置选举协议(无需外部组件) |
| 数据一致性保证 | 最终一致性(切换后需补 Binlog 差异) | 强一致性(多数派提交后才返回客户端成功) |
| 脑裂防护 | 需额外配合(如写 VIP、调用脚本 kill 旧主) | 内建防脑裂(基于多数派 Quorum 机制) |
二、核心差异深度解析
1. 数据一致性:弱 vs 强
-
MHA:
- 依赖异步/半同步复制,主从数据可能有延迟。
- 故障切换后需人工介入:新主数据可能缺失,需用
apply_diff_relay_logs脚本补足 Binlog 差异(仍有数据丢失风险)。 - 适用场景:允许分钟级数据延迟的业务(如报表库、日志分析)。
-
MGR:
- 事务提交需多数派投票(如 3 节点中至少 2 个确认)。
- 客户端收到成功响应时,数据已在多数派节点逻辑确认并持久化(Redo Log)。
- 适用场景:金融交易、核心业务(要求数据零丢失)。
2. 故障切换逻辑:手动 vs 全自动
-
MHA:
![]()
- 痛点:需人工确认、补日志慢、VIP 漂移依赖脚本(可能失败)。
-
MGR:


- **优势**:无需人工干预、秒级切换、内置防脑裂。
3. 扩展性与读负载均衡
-
MHA:
- 仅支持单主写入,从库只读。
- 读扩展需配合中间件(如 ProxySQL)实现负载均衡。
-
MGR:
- 默认单主模式(亦可配置多主)。
- MySQL Router 原生支持读写分离:自动路由写请求到主节点,读请求负载均衡到从节点。
三、应用场景对比
| 场景 | 推荐方案 | 原因 |
|---|---|---|
| 传统业务,可容忍分钟级数据丢失 | MHA | 轻量级、部署简单,适合非核心业务(如内部系统) |
| 金融级业务,要求强一致性 | MGR | 数据零丢失、切换全自动,符合监管要求 |
| 云环境或容器化部署 | MGR | 无依赖 SSH/VIP,原生适应动态 IP 环境 |
| 多地域部署 | MGR | 内置流控与冲突检测,降低多中心写入风险 |
| 开发/测试环境 | MHA | 资源消耗低,快速搭建 |
四、选型决策树
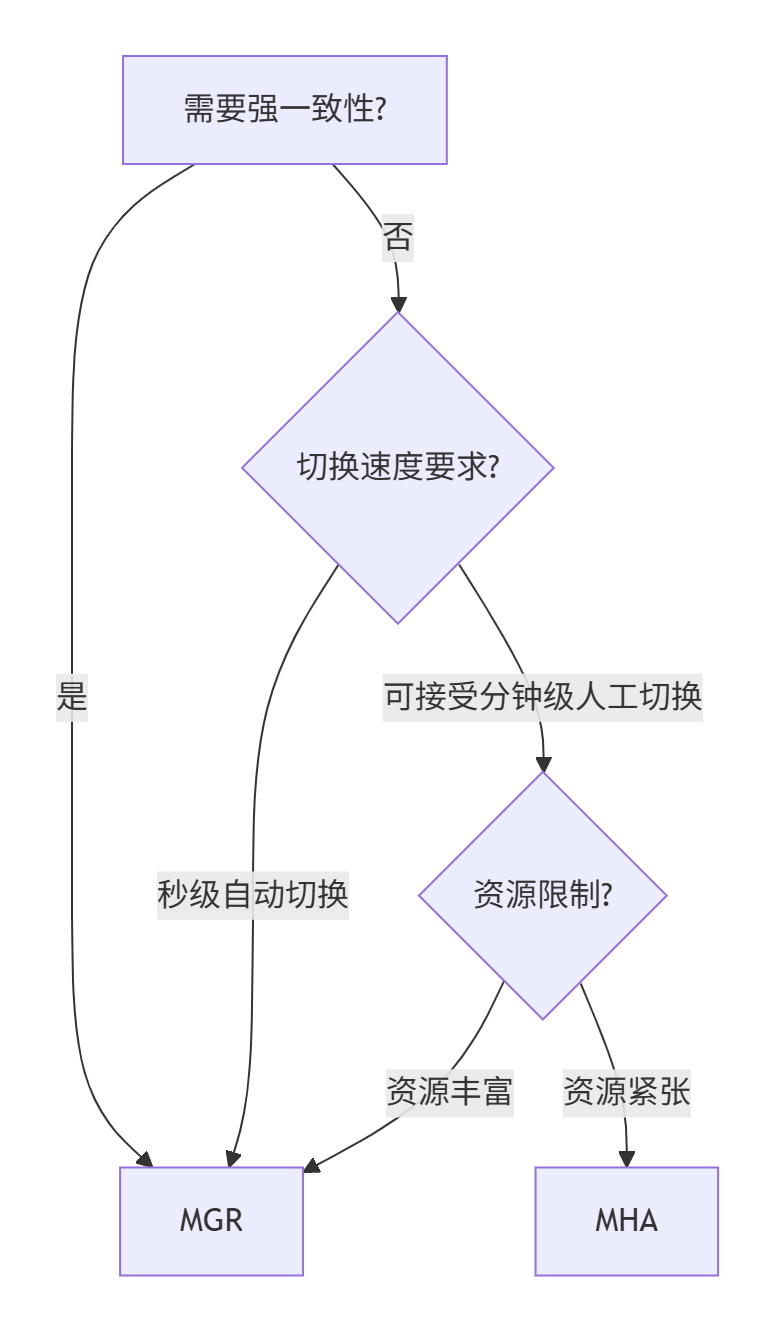
总结
-
MHA:过渡性方案
适合传统异步复制架构升级,低成本提升可用性,但存在数据一致性风险与运维复杂度。 -
MGR:未来方向
MySQL 官方推荐的高可用架构,提供分布式强一致性与全自动故障转移,适应云原生与核心业务场景,但需至少 3 节点和低延迟网络。
💡 建议:
- 新项目优先选择 MGR(MySQL 8.0 内置,技术成熟)
- 存量业务迁移评估网络和资源,逐步从 MHA 切换至 MGR
- 混合云场景可用 MGR + MySQL Router 实现跨云高可用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号