2022 OO 第一单元个人总结
一、前言
对于本单元的项目设计,我认为以下三点是值得深思与提升的:
-
选取合适的数据结构存储信息,数据结构的选取合适程度,与表达式化简的难度以及由代码优化产生的bug数量息息相关;
-
采用递归下降的方法解析expression;
-
通过表达式预处理,更优美地书写代码;
但我们不得不承认,预处理、化简等不论是优化代码本身、抑或结果输出的方式,都极大的增加了bug产生的可能性。因为优化的同时,就意味着我们考虑更少的可能性,也就存在更多的非法情况。对于 优化 与 bug 之间的矛盾,是需要我们权衡的。
对于三次作业的迭代,笔者认为对于项目的思考,主要聚焦于数据结构选取、是否进行表达式的预处理、以及化简的程度这三点。
对于递归下降分析法的应用,在第一次作业中也许是一件有挑战的事,但在第二、三次作业中,也并不显得很困难。
故而本博客将仅对于第三次作业进行全面分享,并辅以 与第一次作业的数据结构 、 与第二次作业的代码优化、表达式预处理 进行对比,阐述自己的思考。
二、项目迭代的最终版本
1. 形式化表述
首先,为方便观看与回忆,附上第三次作业的形式化表述(本博客不再讨论关于课程限定等细枝末节的内容,而是聚焦于答题思路,课程限定不过是为了方便我们完成项目)。

2. 数据结构与程序架构
程序 = 数据结构 + 算法
数据结构
在本程序中,数据结构的选择需要面对存储与化简两个问题。
Factor -> Term -> Expression
对于存储的需求,我们自然而然地建立了Num 、Power、 Sin、 Cos四个类来储存最基本的信息。并通过Factor这个抽象类来实现对基本类的统一。对于 Sin与 Cos如何存储信息(或者说其内部变量的数据结构)暂且不论,至少,我们拥有了这四个最基本的类,构成了可以完成本项目的最基本的数据结构。
在构造完成上一段的基本类后,事实上我们完成了最基本的Factor需求,接下来便是思考如何完成将Factor连乘为Term的数据结构构造。
近乎自然的发散思维,可以让我们联想到将基本类统一为一个NormalOfFactor类,正如数学模型C*x^p*∏(Sin()^q)*∏(Cos()^r这样的形式(就像物理一直追求四个基本力大一统一样)。该类通过如下 数据结构储存信息、方法完成Term连乘功能。
private String op;
private BigInteger coe;
private BigInteger pow;
private ArrayList<Sin> sinFactors = new ArrayList<>();
private ArrayList<Cos> cosFactors = new ArrayList<>();
public void addFactorOfNum(Num num); //事实上,可以将四个方法再次包装成一个方法:
public void addFactorOfPower(Power power); //addFactor(Factor factor);
public void addFactorOfSinArray(Sin sin);
public void addFactorOfCosArray(Cos cos);
接下来,我们创建Term类,用来实现Term的功能,分析Factor与完成计算。
private final ArrayList<NormalOfFactor> normalOfFactors = new ArrayList<>();
public void addFactor(Factor factor); //将Factor对与normalOfFactors中每个元素乘
根据形式化表述,我们可以将Factor分为两类,基本类与表达式,基本类的连乘方法已在NormalOfFactor中实现,而考虑表达式的作用,表达式的连乘功能将在Expr类中实现。
另外,normalOfFactors的存在,是为了满足表达式因子的计算,如(x+1)(x+2)。
通过上面的构建,我们已经拥有了很多个Term,现在的目的是将terms,计算出expression。
expression具有两个内容,一是将terms加在一起,二是将其计算幂次。
在不考虑化简的情况下,功能一仅需要将每个term的normalOfFactors加在一起,所以在Expr,我们仍定义normalOfFactors而非terms。
public void addTerm(Term term) {
for (NormalOfFactor normalOfFactor : term.getNormalOfFactors()) {
addOneOfTerm(normalOfFactor); //在添加时化简
}
}
而对于功能二,在NormalOfFactor类的方法下,就是相当于一个三重循环。
public void calForPow();
public void multiTwoNormalOfFactors(ArrayList<NormalOfFactor> normalOfFactors1,
ArrayList<NormalOfFactor> normalOfFactors2,ArrayList<NormalOfFactor> newNormalOfFactors);
private void multiNormalOfFactorToNormalOfFactors(NormalOfFactor normalOfFactor,
ArrayList<NormalOfFactor> normalOfFactors,ArrayList<NormalOfFactor> newNormalOfFactors);
private void multiTwoNormalOfFactor(NormalOfFactor normalOfFactor1,
NormalOfFactor normalOfFactor2,ArrayList<NormalOfFactor> newNormalOfFactors);
我们可以看出,此前挖的坑(Term如何处理Expr因子),只需要调用expr.multiTwoNormalOfFactors()即可。
于是,抛去一些细枝末节的东西,数据结构的存储便如此完成了。
现在我们讨论对化简的需求。
注意:此时未根据三角函数的性质化简(奇偶性、三角恒等式)
化简的思路只有一个:给定标准型,然后递归下降。
我们自顶而下看:
-
如何化简两个项相加?
-
在
addTerm时,对于相同的normalOfFactor完成合并(即两个coe相加); -
如何识别
normalOfFactor可以合并?-
规范
normalOfFactor.toStringExcCoe;
-
若
normalOfFactor.toStringExcCoe相等,则认为可以合并;
-
-
最终:保证
Expr的normalOfFactors不存在可化简情况。
-
-
如何化简两个因子相乘?
-
coe直接相乘 -
pow直接相加 -
sin(expr)^p二重循环-
如果
expr.toString相同,则两个p相加;-
expr通过Collections.sort(normalOfFactorsToString)提供排序规范;
-
-
-
cos(expr)^p二重循环-
如果
expr相同,则两个p相加;-
expr通过Collections.sort(normalOfFactorsToString)提供排序规范;
-
-
-
最终:保证
Term的normalOfFactors不存在可化简情况。
-
-
如何确定
normalOfFactorsToString相等?-
coe + * + normalOfFactor.toStringExcCoe-
规范
Num.toString; -
规范
normalOfFactor.toStringExcCoe-
x^p相等;-
规范
Power.toString;
-
-
通过
Collections.sort(sinStrings)规范∏(Sin()^q)的String输出顺序;-
规范
Sin.toString;
-
-
通过
Collections.sort(cosStrings)规范∏(Cos()^q)的String输出顺序;-
规范
Cos.toString;
-
-
-
-
上文中省略了如sin(0), coe == 0, pow == 1等情况的讨论。
如上述讨论,我们自顶而下分析,通过Collections.sort(Strings)这个java自带的函数,通过重写toString函数,完成了排序与优化。
算法
预处理
对于输入的expr,对其进行五方面的化简:
-
消除" "与"\t";
-
将"**"替换为"^";
-
使
expr仅连续有一个正负号; -
使数字没有前导零;
-
消除一次幂;
自定义函数
首先储存函数,并进行预处理,后在使用时对参数进行替换。注意,对于次幂要加入()防止出现表达式无括号的情况;
求和函数
对于求和函数,先将i进行替换,后进行预处理。注意,对于次幂要加入()防止出现表达式无括号的情况;
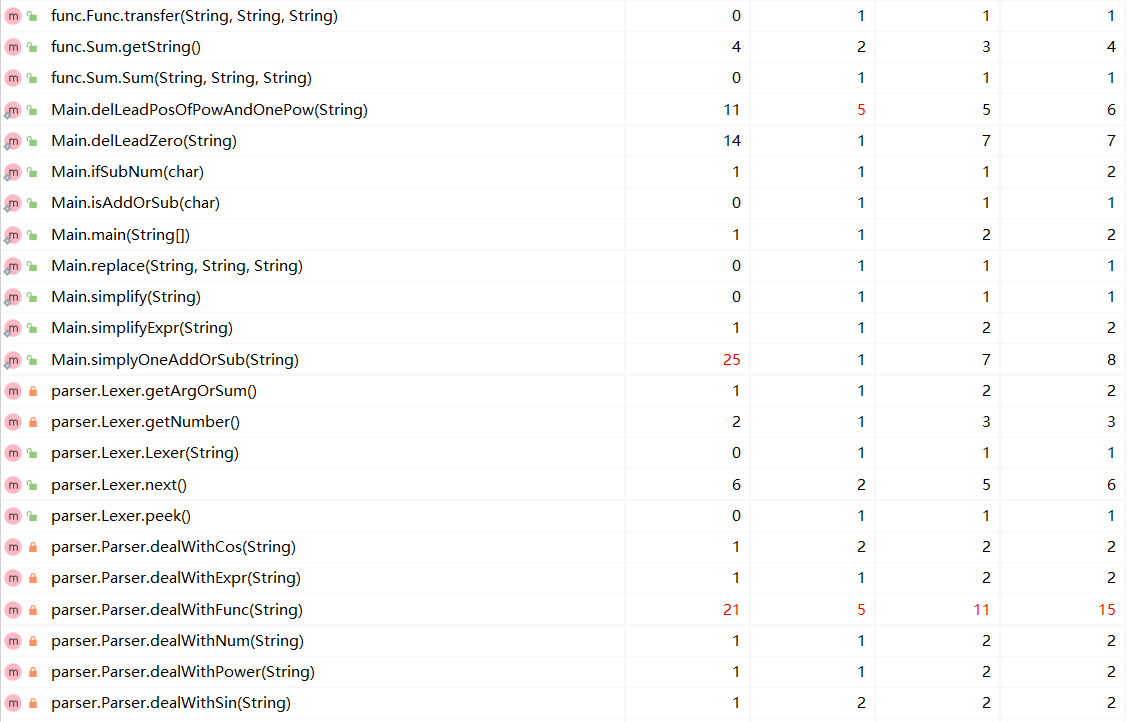
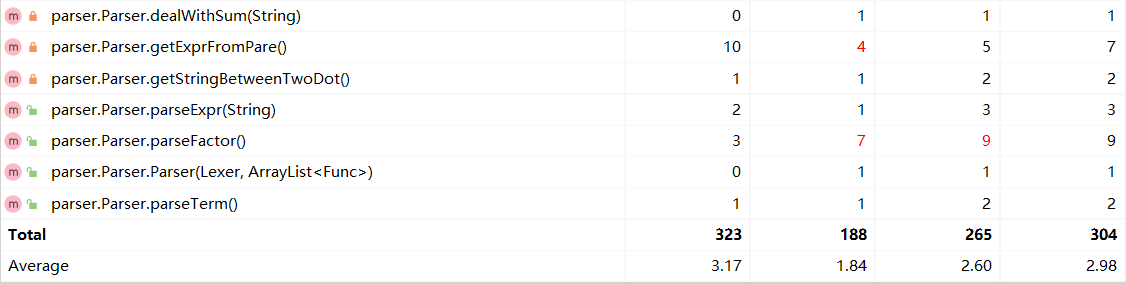
3. 代码度量
UML图

OO度量
LOC:Lines of Code: 类/方法代码规模
NAAC:Number of Attributes: 类属性个数
NOAC:Number of Methods:类方法个数
CONTROL:Number of Control statements:控制分支个数
-
代码统计
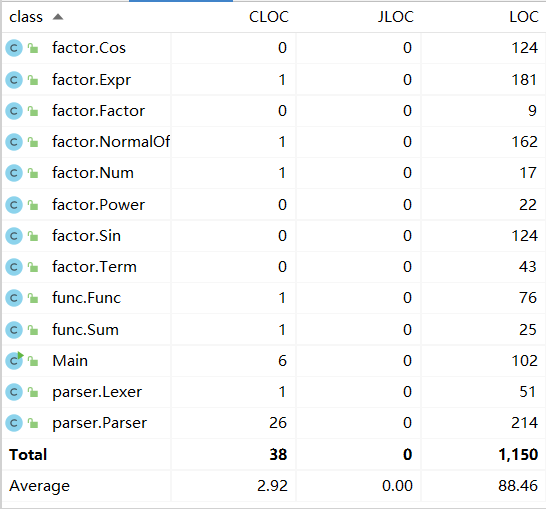
-
类度量

-
类复杂度度量
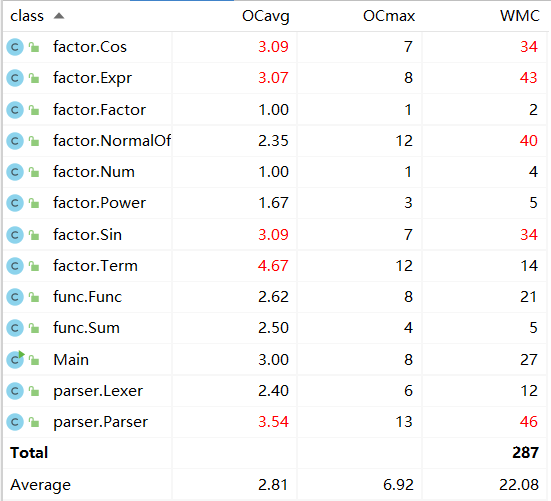
-
方法复杂度度量
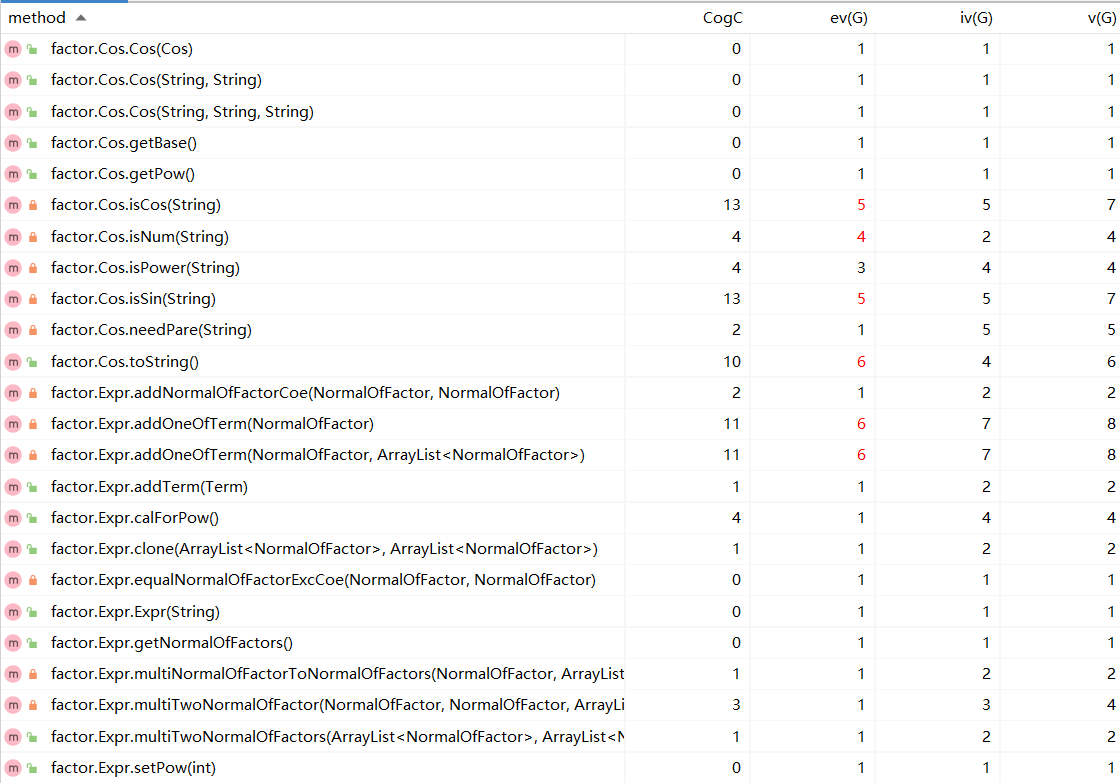

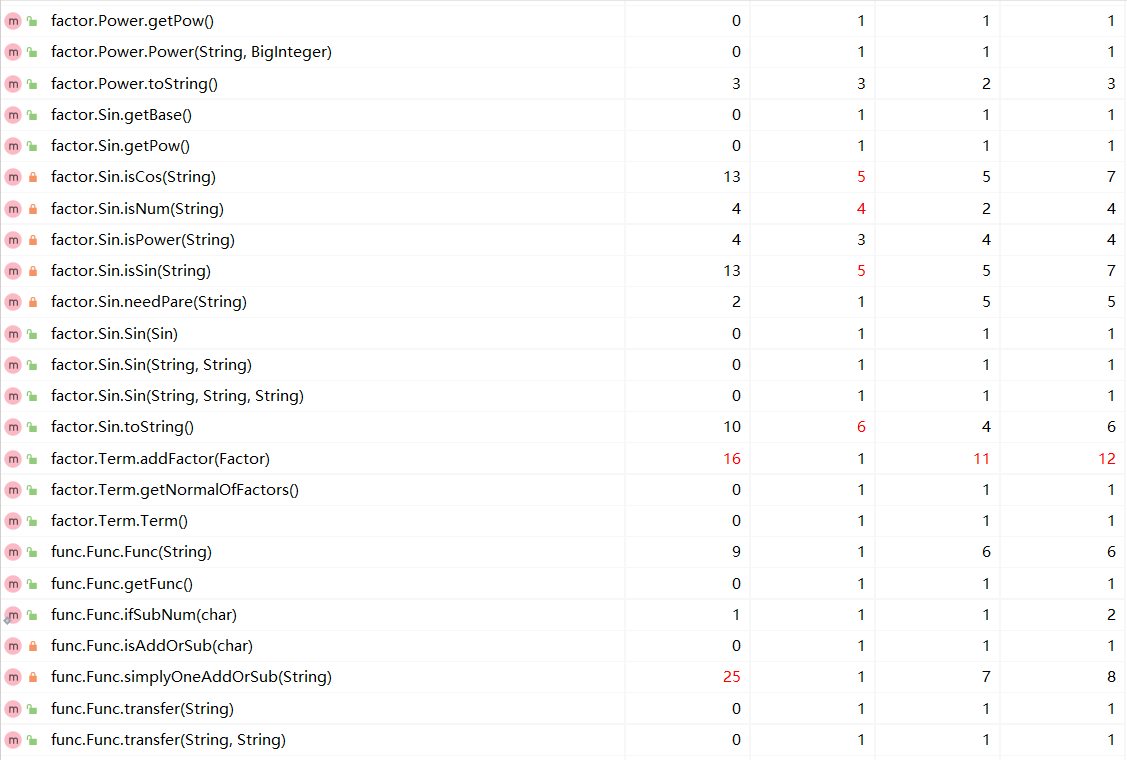
-
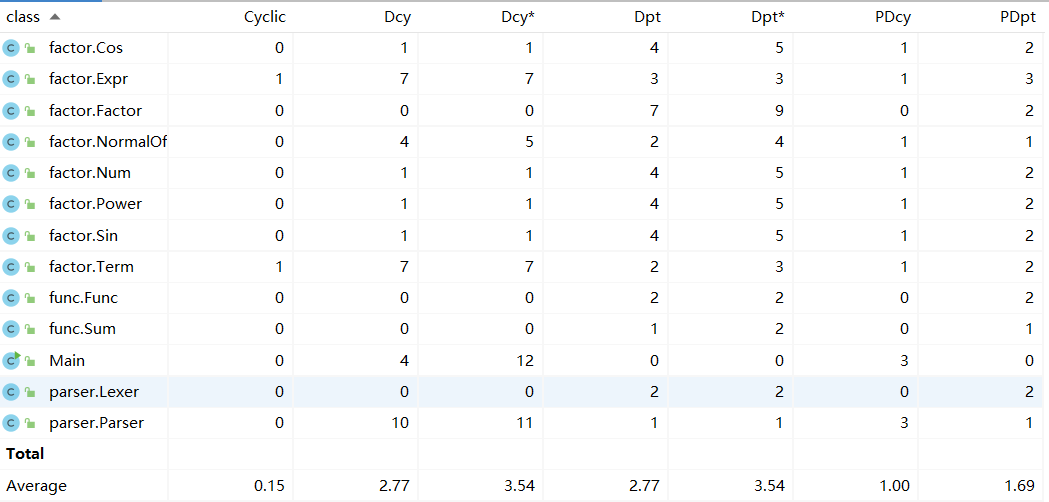
类耦合度量
![]()
复杂度较低,耦合度较低,内聚情况良好
4. 对比
与第一次作业对比,增添了预处理,极大的减少了Parser类中toParser、toTerm与toFactor的复杂度,但会由此产生更多的bug。
与第二次作业相比,代码优化与数据结构的构造,让代码变得优雅而输出复杂度低;但同样,存在一定的bug,并且数据结构复杂。
三、bug分析
一个最重要的bug,就是对于深浅拷贝理解不充分导致的。
对于大多数情况,如项的加减,浅拷贝即可。但对于表达式的幂次,必须要深拷贝,因为要多次运用其原表达式。
其他大多bug一个出现于化简代码,另外均出现于sum类。由于在sum类代换后,未进行表达式化简。
事实上,许多bug的产生是由于测试不充分导致的,应当进行更多、更充分的测试。
四、架构体会与感想
本单元的练习,我对递归下降的思想有了更深刻的理解与应用。
同时,对于OO的思想,高内聚低耦合的设计思路,有了自身的理解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号