线性回归和量化交易基础(上)
回归法选股,是做以下几件事
1. 判断因子和股票收益的相关性
2. 选择合适的因子
3. 整理数据 判断横截面下 上个月的月末,因子对下个月初的股票的影响, 每个月统计一次,用系数表示
4. 当我们确定了所有因子对股票的影响后,就可以用回归方程来选择合适的股票,也即判断大盘中股票得分最高的 (沪深300也可以)
所用数学技术:
1. 标准化
2. 三倍中位数去极值
3. 市场中性化
4. 主成分分析
下面的代码获取total_data的数据
1 import numpy as np 2 import pandas as pd 3 import datetime 4 5 # 训练回测区间 6 # 准备好因子对应日期的数据 获取每个月月末的数据 7 dates=get_trading_dates(start_date="2008-01-01",end_date="2018-01-01") 8 9 month_date=[] 10 for i in range(len(dates)-1): 11 if dates[i].year!=dates[i+1].year: 12 month_date.append(dates[i]) 13 elif dates[i].month!=dates[i+1].month: 14 month_date.append(dates[i]) 15 16 month_date.append(dates[-1]) 17 18 # 获取沪深300的股票列表 19 stocks=index_components("000300.XSHG") 20 21 total_data=pd.DataFrame() 22 23 for date in month_date[:-1]: 24 q=query(fundamentals.eod_derivative_indicator.pe_ratio, 25 fundamentals.eod_derivative_indicator.market_cap, 26 fundamentals.eod_derivative_indicator.pb_ratio, 27 fundamentals.financial_indicator.return_on_equity, 28 fundamentals.financial_indicator.cost_to_sales, 29 fundamentals.income_statement.r_n_d, 30 fundamentals.income_statement.operating_revenue, 31 fundamentals.income_statement.net_profit, 32 fundamentals.income_statement.total_expense).filter( 33 fundamentals.stockcode.in_(stocks)) 34 35 fund=get_fundamentals(q,entry_date=date) 36 fund["date"]=date 37 fund=fund.to_frame() 38 # 数据拼接 处理数据格式 39 total_data=pd.concat([total_data,fund])
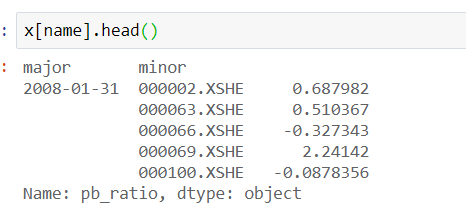
total_data=total_data.dropna() #把缺失值去除 total_data["next_month_return"]=np.nan total_data.head()
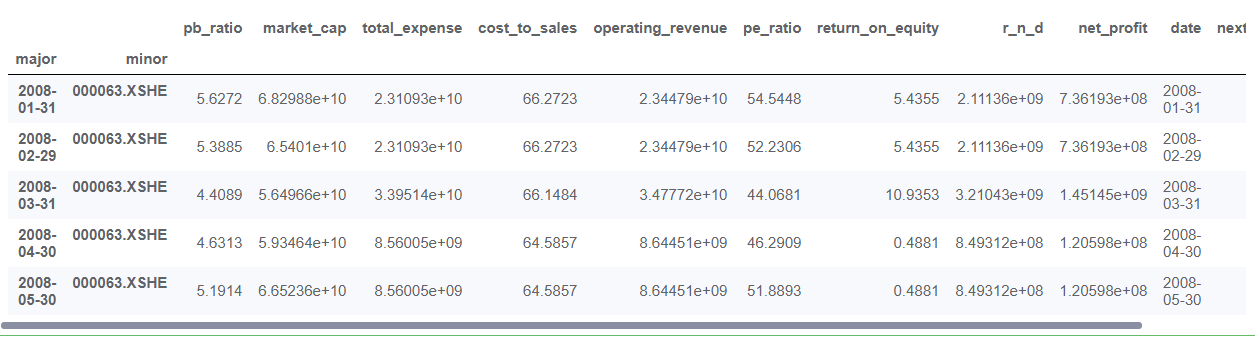
在上面我们看到了pandas.DataFrame中的数据
下面计算收益率
total_price=pd.DataFrame() for date in month_date: price=get_price(stocks,start_date=date,end_date=date,fields="close") total_price=pd.concat([total_price,price]) total_price=total_price.T total_price = total_price.dropna() for i in range(len(total_price.columns)-1): total_price.iloc[:,i] = (total_price.iloc[:,i+1] / total_price.iloc[:,i]) -1 total_price.head()
下面我们把收益率填充到total_data中
## 将收益率填充到total_data中 for i in range(len(total_data)): # 这里是一个tuple stock=total_data.index[i][1] date = total_data.ix[i,'date'] # ans=total_price.columns[i].to_pydatetime().date() # print(ans) # print(type(total_price.columns[0])) # print(type(ans)) # total_price.columns.iloc(i)=ans # print(stock in total_price.index) # print(str(stock)) # got a stupid mistake !!! Just Instead [] with () if stock in total_price.index and date == ans: total_data.ix[i,"next_month_return"]=total_price.loc[stock,date]
图示如下:
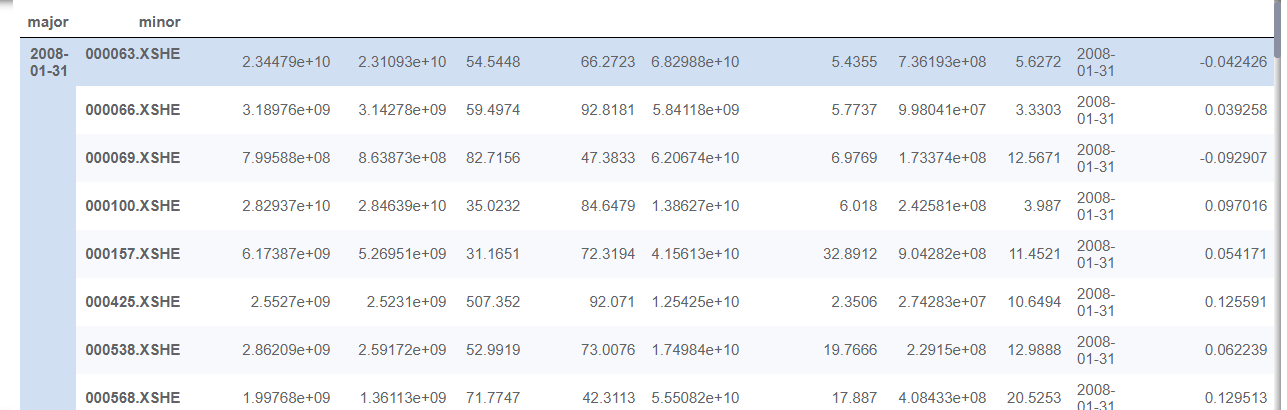
我们然后确定x,y即可,实际上一行的值,除了date和next_month_return 都是系数,只有next_month_return 是因变量
利用stand函数
def stand(factor): mean=np.mean(factor) std=np.std(factor) return (factor-mean)/std
和mad函数
def mad(factor): med=np.median(factor) mad=np.median(np.abs(factor-med)) high=med+3*1.4826*mad low=med-3*1.4826*mad factor=np.where(factor>high,high,factor) factor=np.where(factor<low,low,factor) return factor
将值去极值并标准化