25-5 早期绑定与晚期绑定
在本节及下一节中,我们将深入探讨虚拟函数的实现机制。虽然这些知识并非有效使用虚拟函数的必要条件,但颇具趣味性。不过,您可将这两部分内容视为可选阅读材料。
当C++程序执行时,它会从main()函数顶部开始顺序执行。遇到函数调用时,执行点会跳转至被调用函数的开头。CPU如何实现这种跳转?
程序编译时,编译器会将C++代码中的每条语句转换为一行或多行机器语言。每行机器语言都会被分配一个唯一的顺序地址。函数也不例外——当遇到函数时,它会被转换为机器语言并分配下一个可用地址。因此每个函数最终都拥有唯一的地址。
绑定与分派
我们的程序包含许多名称(标识符、关键字等)。每个名称都关联着一组属性:例如,若名称代表变量,则该变量具有类型、值、内存地址等属性。
例如当我们声明 int x 时,是在告知编译器将名称 x 与类型 int 建立关联。后续执行 x = 5 时,编译器便能利用此关联进行类型检查,确保赋值操作有效。
在编程中,绑定binding是指将名称与属性关联的过程。函数绑定Function binding(或方法绑定method binding)是确定函数调用对应何种函数定义的过程。实际调用已绑定函数的过程称为分派dispatching。
在C++中,“绑定”一词使用更为灵活(且分派通常被视为绑定的一部分)。下面我们将探讨C++中这些术语的具体用法。
术语说明:
绑定是一个含义模糊的术语。在其他语境中,绑定可能指代:
- 将引用绑定到对象
- std::bind
- 语言绑定
早期绑定
编译器遇到的绝大多数函数调用都是直接函数调用。直接函数调用是指直接调用函数的语句。例如:
#include <iostream>
struct Foo
{
void printValue(int value)
{
std::cout << value;
}
};
void printValue(int value)
{
std::cout << value;
}
int main()
{
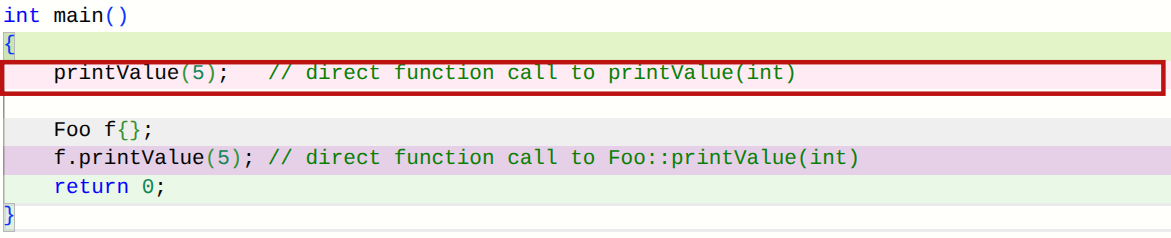
printValue(5); // direct function call to printValue(int)
Foo f{};
f.printValue(5); // direct function call to Foo::printValue(int)
return 0;
}
在 C++ 中,当直接调用非成员函数或非虚成员函数时,编译器能够确定应匹配哪个函数定义。这种机制有时被称为早期绑定(或静态绑定),因为它可在编译时完成。随后编译器(或链接器)会生成机器语言指令,指示 CPU 直接跳转至该函数的地址。
对于高级读者:
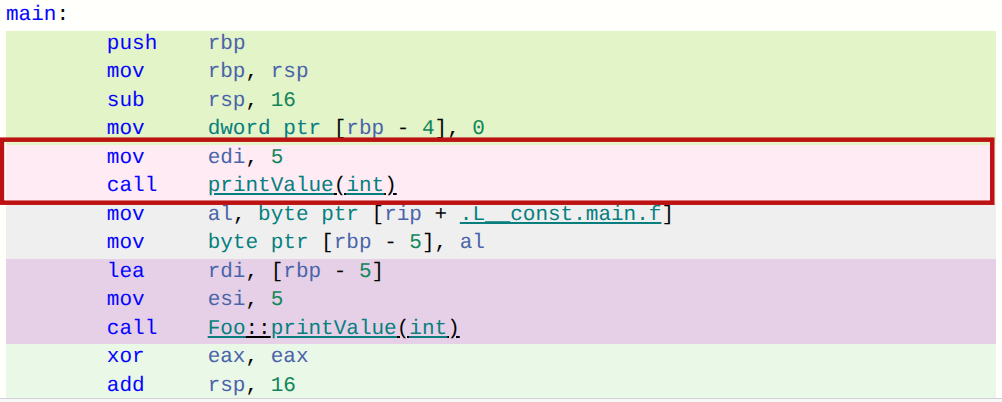
若我们查看针对 printValue(5) 调用生成的汇编代码(使用 clang x86-64 编译器),会看到类似以下内容:mov edi, 5 ; copy argument 5 into edi register in preparation for function call call printValue(int) ; directly call printValue(int)你可以清楚地看到,这是对 printValue(int) 的直接函数调用。
重载函数和函数模板的调用同样可以在编译时解析:
#include <iostream>
template <typename T>
void printValue(T value)
{
std::cout << value << '\n';
}
void printValue(double value)
{
std::cout << value << '\n';
}
void printValue(int value)
{
std::cout << value << '\n';
}
int main()
{
printValue(5); // direct function call to printValue(int)
printValue<>(5); // direct function call to printValue<int>(int)
return 0;
}

让我们来看看一个使用早期绑定实现的简单计算器程序:
#include <iostream>
int add(int x, int y)
{
return x + y;
}
int subtract(int x, int y)
{
return x - y;
}
int multiply(int x, int y)
{
return x * y;
}
int main()
{
int x{};
std::cout << "Enter a number: ";
std::cin >> x;
int y{};
std::cout << "Enter another number: ";
std::cin >> y;
int op{};
std::cout << "Enter an operation (0=add, 1=subtract, 2=multiply): ";
std::cin >> op;
int result {};
switch (op)
{
// call the target function directly using early binding
case 0: result = add(x, y); break;
case 1: result = subtract(x, y); break;
case 2: result = multiply(x, y); break;
default:
std::cout << "Invalid operator\n";
return 1;
}
std::cout << "The answer is: " << result << '\n';
return 0;
}

由于 add()、subtract() 和 multiply() 都是对非成员函数的直接调用,编译器将在编译时将这些函数调用与各自的函数定义进行匹配。
请注意,由于存在 switch 语句,实际调用哪个函数要等到运行时才确定。但这属于执行路径问题,而非绑定问题。
晚期绑定
在某些情况下,函数调用无法在运行时之前解析。在C++中,这种情况有时被称为晚期绑定late binding(或在虚拟函数解析的情况下称为动态分派dynamic dispatch)。
作者注:
在通用编程术语中,“晚绑定”通常指仅凭静态类型信息无法确定被调用函数,必须通过动态类型信息进行解析的情况。在C++中,该术语的使用范围更为宽泛,泛指任何在函数调用发生时编译器或链接器无法知晓实际调用函数的场景。
在 C++ 中,实现晚期绑定的一种方式是使用函数指针。简要回顾函数指针的概念:函数指针是一种指向函数而非变量的指针类型。通过在指针上使用函数调用运算符 () 即可调用该指针所指向的函数。
例如,以下代码通过函数指针调用了 printValue() 函数:
#include <iostream>
void printValue(int value)
{
std::cout << value << '\n';
}
int main()
{
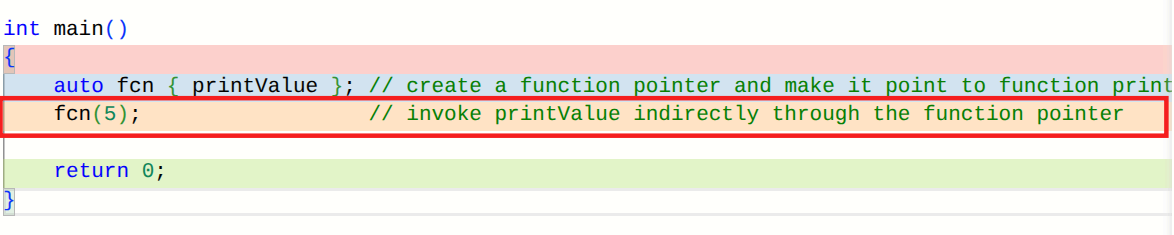
auto fcn { printValue }; // create a function pointer and make it point to function printValue
fcn(5); // invoke printValue indirectly through the function pointer
return 0;
}
通过函数指针调用函数也称为间接函数调用。在实际调用 fcn(5) 的位置,编译器无法在编译时确定将调用哪个函数。相反,在运行时,系统会根据函数指针指向的地址,对该地址处的函数执行间接函数调用。
对于高级读者:
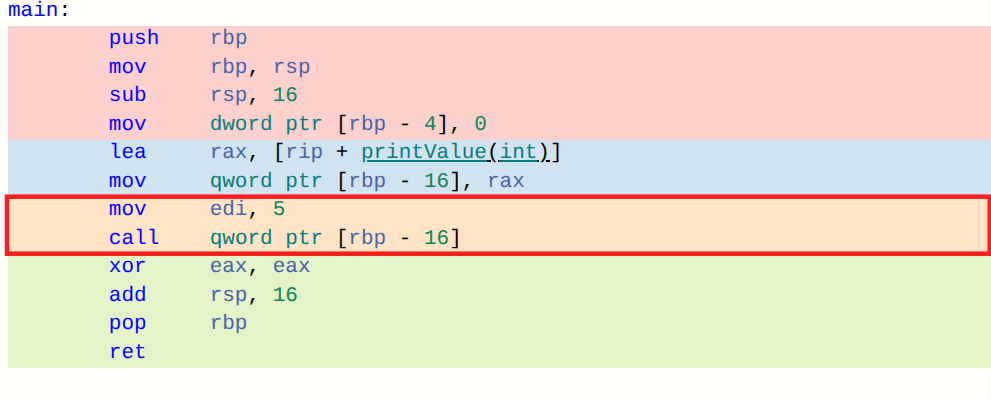
若我们查看调用 fcn(5) 时生成的汇编代码(使用 clang x86-64 编译器),会看到类似以下内容:lea rax, [rip + printValue(int)] ; determine address of printValue and place into rax register mov qword ptr [rbp - 8], rax ; move value in rax register into memory associated with variable fcn mov edi, 5 ; copy argument 5 into edi register in preparation for function call call qword ptr [rbp - 8] ; invoke the function at the address held by variable fcn你可以清楚地看到,这是通过地址间接调用 printValue(int) 函数。
以下计算器程序的功能与上述计算器示例完全相同,区别在于它使用函数指针而非直接调用函数:
#include <iostream>
int add(int x, int y)
{
return x + y;
}
int subtract(int x, int y)
{
return x - y;
}
int multiply(int x, int y)
{
return x * y;
}
int main()
{
int x{};
std::cout << "Enter a number: ";
std::cin >> x;
int y{};
std::cout << "Enter another number: ";
std::cin >> y;
int op{};
std::cout << "Enter an operation (0=add, 1=subtract, 2=multiply): ";
std::cin >> op;
using FcnPtr = int (*)(int, int); // alias ugly function pointer type
FcnPtr fcn { nullptr }; // create a function pointer object, set to nullptr initially
// Set fcn to point to the function the user chose
switch (op)
{
case 0: fcn = add; break;
case 1: fcn = subtract; break;
case 2: fcn = multiply; break;
default:
std::cout << "Invalid operator\n";
return 1;
}
// Call the function that fcn is pointing to with x and y as parameters
std::cout << "The answer is: " << fcn(x, y) << '\n';
return 0;
}
在此示例中,我们并未直接调用 add()、subtract() 或 multiply() 函数,而是将 fcn 设置为指向目标函数的指针,随后通过该指针调用函数。
编译器无法通过早期绑定解析函数调用 fcn(x, y),因为它无法在编译时确定 fcn 将指向哪个函数!
晚绑定效率稍低,因其涉及额外的间接层级。采用早绑定时,CPU可直接跳转至函数地址;而晚绑定需先读取指针存储的地址再跳转,多出一个步骤导致速度略有下降。但晚绑定的优势在于比早绑定更具灵活性——何时调用哪个函数的决策可延迟至运行时才做。
在下一课中,我们将探讨延迟绑定如何用于实现虚函数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号